模型剪枝
剪枝简介
在深度学习领域,模型压缩是一个非常重要的研究方向,尤其是在计算资源有限的情况下。通过模型压缩,可以有效减少模型的存储需求和计算复杂度,同时尽量保持模型性能。本文将介绍模型剪枝的基本概念及其流程。
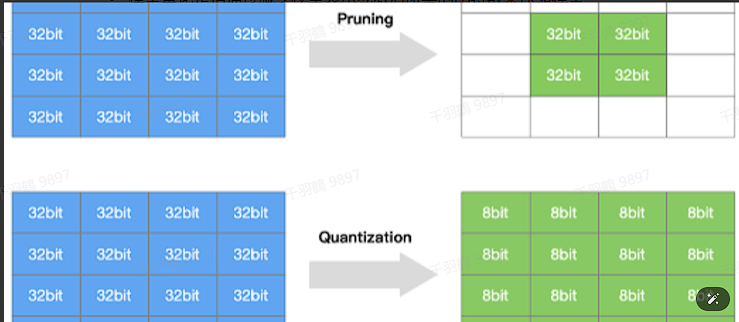
模型量化与剪枝的区别
模型量化是通过减少权重表示或激活所需的比特数来压缩模型。例如,将权重从 32 位浮点数表示转换为 8 位整数表示,从而显著减少模型的存储空间。
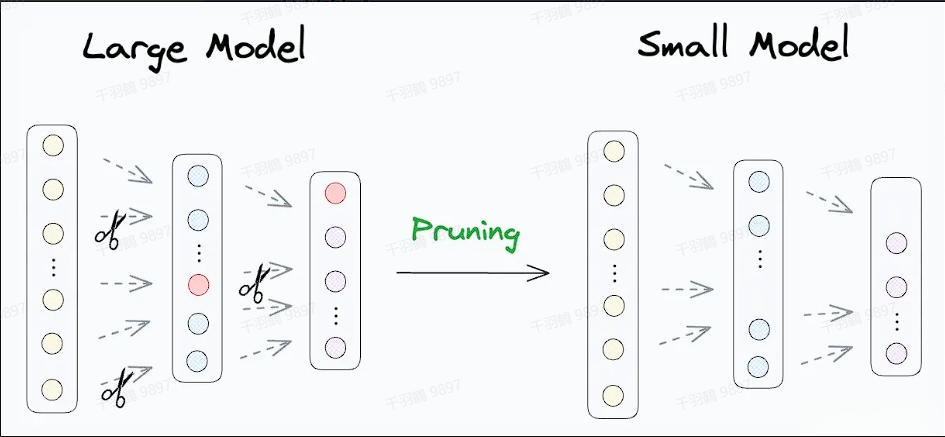
模型剪枝则不同,它研究模型权重中的冗余部分,并尝试删除或修剪这些冗余和非关键的权重,以此来减小模型的大小和计算复杂度。与量化相比,剪枝更关注去除不必要的参数,而不是改变参数的精度。
剪枝流程
在实际应用中,模型剪枝的流程可以分为以下三种主要方式:
1. 先训练模型,然后剪枝,最后微调
这是最为经典的一种剪枝流程。具体步骤如下:
- 训练模型:首先训练一个完整的模型,使其达到较高的性能。
- 剪枝:根据某种策略对模型进行剪枝,去除冗余权重。
- 微调:对剪枝后的模型进行微调,以恢复部分因剪枝造成的性能损失。
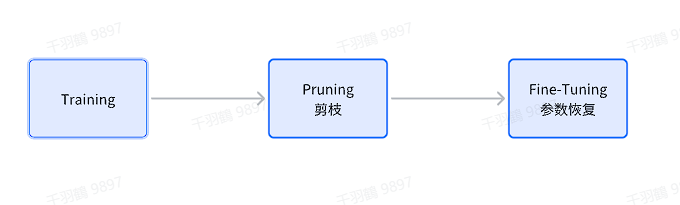
这种方法适用于对性能要求较高的场景,因为先训练完整模型可以确保初始性能较优。
2. 模型训练的过程中剪枝,然后微调
这种方法将剪枝过程融入到模型训练中。具体步骤如下:
- 边训练边剪枝:在训练过程中动态评估权重的重要性,并逐步移除冗余权重。
- 微调:完成训练后,对模型进行微调,用以进一步优化性能。
相比于第一种方法,这种方法可以节省一定的时间和计算资源,因为省去了单独训练完整模型的步骤。
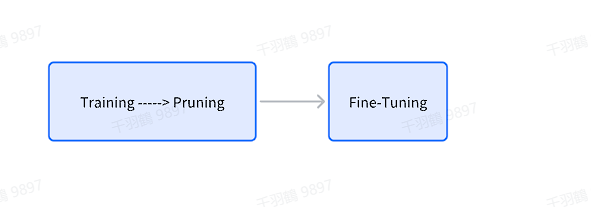
3. 进行剪枝,然后从头训练剪枝的模型
在深度学习领域,模型压缩是一个重要的研究方向,而剪枝技术作为其中的一种方法,能够有效地减少模型参数量,从而降低模型的存储和计算成本。本文将详细介绍剪枝技术的分类和具体方法,帮助读者更好地理解这一领域的最新进展。
7.2.3 剪枝分类
剪枝技术主要分为非结构化剪枝和结构化剪枝两大类。每种方法各有优缺点,并适用于不同的场景。
非结构化剪枝
非结构化剪枝是指随机对独立权重或者神经元链接进行剪枝,即移除个别参数,而不考虑整体网络结构。这种方法通过将低于阈值的参数置零的方式对个别权重或神经元进行处理。非结构化剪枝会导致模型出现不规则的稀疏结构,需要专门的压缩技术来存储和计算被剪枝的模型。此外,非结构化剪枝通常需要对大语言模型(LLM)进行大量的再训练以恢复准确性,这对于LLM来说尤其昂贵。
优点
- 剪枝算法简单
- 模型压缩比高
缺点
- 精度不可控
- 剪枝后权重矩阵稀疏,没有专用硬件难以实现压缩和加速的效果
非结构化剪枝方法
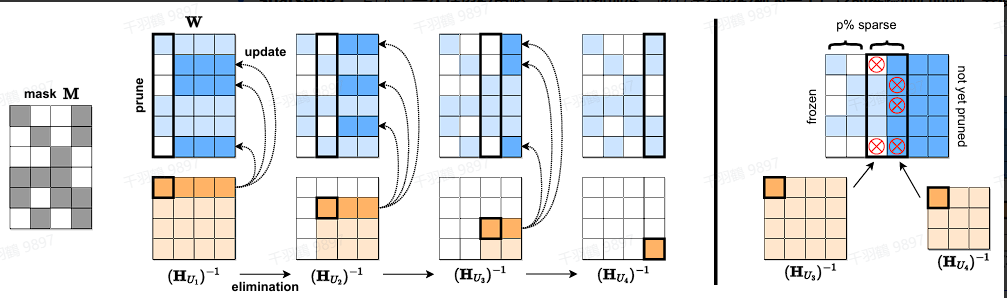
- SparseGPT
SparseGPT 引入了一次性剪枝策略,无需重新训练。该方法将剪枝视为一个广泛的稀疏回归问题,并使用近似稀疏回归求解器来解决,从而实现了显著的非结构化稀疏性。
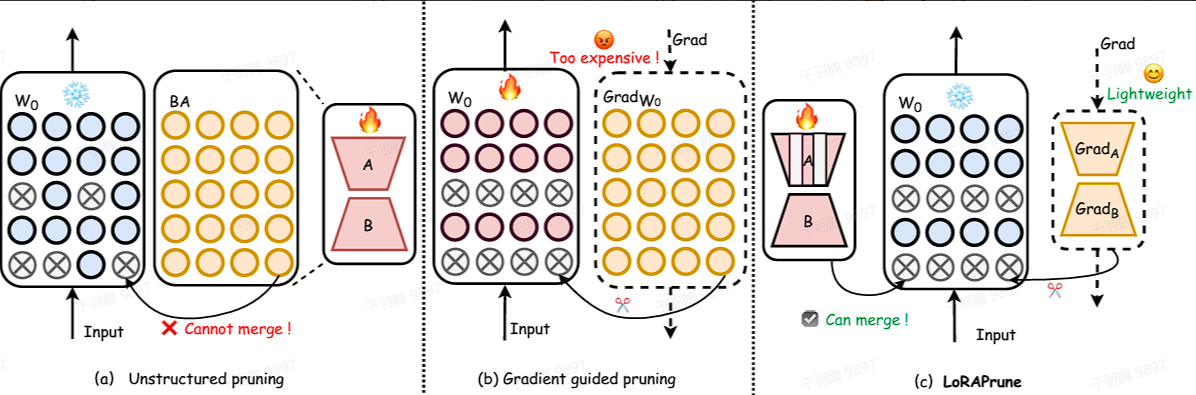
- LoRAPrune
LoRAPrune 将参数高效微调(PEFT)方法与剪枝相结合,以提高下游任务的性能。它引入了一种独特的参数重要性标准,该标准使用了来自 LoRA 的值和梯度。
- Wanda
Wanda 提出了一种新的剪枝度量,该度量根据每个权重的大小以及相应输入激活的范数的乘积进行评估:这个乘积是通过使用一个小型校准数据集来近似计算的。该度量用于线性层输出内的局部比较,使得可以从 LLM 中移除优先级较低的权重。

结构化剪枝
结构化剪枝是指根据预定义规则移除连接或分层结构,同时保持整体网络结构。这种方法一次性地针对整组权重,具有降低模型复杂性和内存使用的优势,同时保持整体 LLM 的结构完整。
结构化剪枝方法
- LLM-Pruner
LLM-Pruner 采用了一种多功能的方法来压缩 LLM,同时保护它们在多任务解决和语言生成能力上的表现。它引入了一个依赖检测算法,用于定位模型内部的相互依赖结构。此外,它还实施了一种高效的重要性估计方法,该方法综合考虑了一阶信息和近似 Hessian 信息。

