Deepseek-math
深度数学预训练与强化学习探索
分类:自动推断
标签:数学预训练、强化学习、数据处理、DeepSeek
日期:2025年4月12日
核心观点总结
本文探讨了Deepseek-math项目的主要贡献,包括可扩展的数学预训练和对强化学习的探索与分析。重点介绍了数据处理过程,涉及训练数据的收集与清洗、预训练模型的参数设置、以及指令微调和强化学习过程。
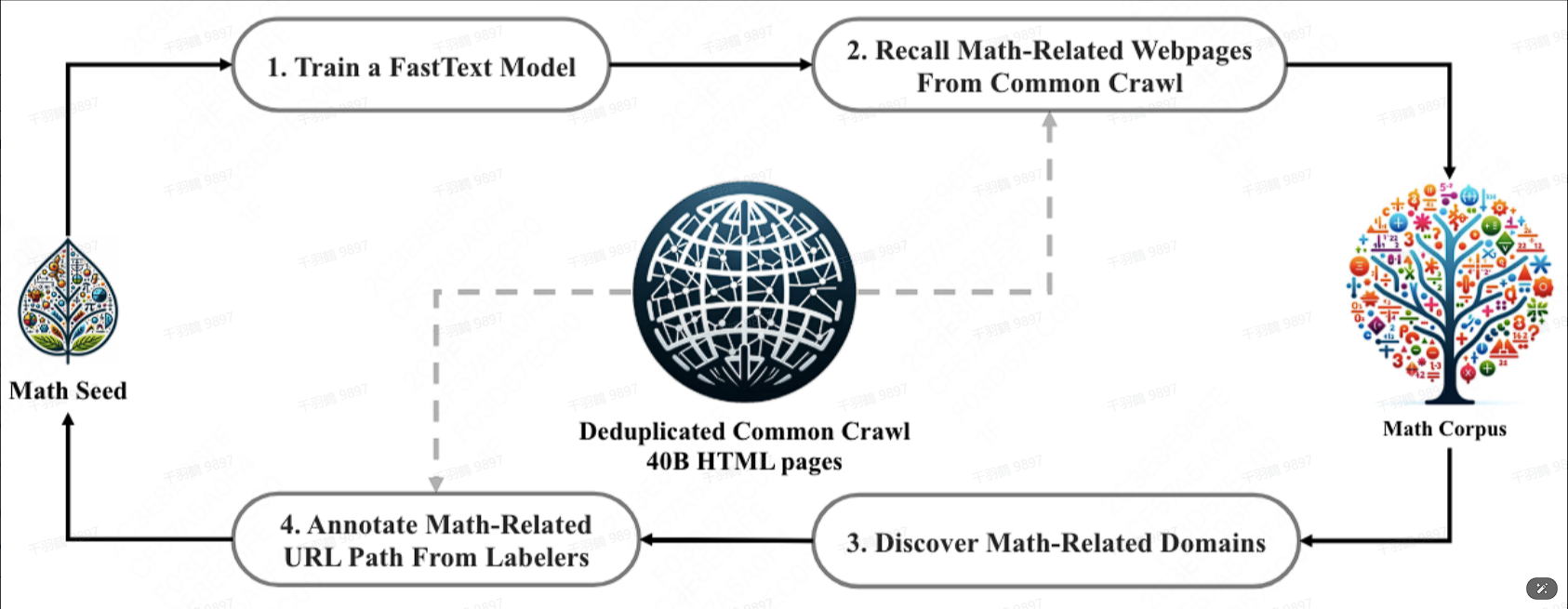
重点段落与数据
训练数据与来源
- 120B数学标记来自Common Crawl的数据,使用fastText分类器提取,多语言支持。
- 数据分布:56%来自DeepSeekMath语料库,4%来自AlgebraicStack,10%来自arXiv,20%是Github代码,其余10%是Common Crawl的自然语言数据。
数据集收集和清洗过程
- 去重和召回:确保数据唯一性,避免冗余。
- 去污染:过滤掉包含英语和中文数学基准测试题目或答案的网页,以免基准污染。
指令微调与强化学习
- 构建了一个数学指令调优数据集,共776K个样本。
- 使用GRPO进行强化学习,group size设为64。
数据表格
| 数据来源 | 占比 |
|---|---|
| DeepSeekMath Corpus | 56% |
| AlgebraicStack | 4% |
| arXiv | 10% |
| Github代码 | 20% |
| Common Crawl | 10% |
操作步骤
- ✅ 收集数据:从Common Crawl提取120B数学标记。
- ⚠ 训练fastText模型:注意与word2vec CBOW的区别。
- ❗ 去污染:确保基准测试题目或答案不被包含在训练数据中。
常见错误
注意在数据去重和召回过程中,可能会遗漏重要的数据片段,需特别小心。
💡启发点
- 数据去污染策略有效防止了基准测试的污染,为模型的公平评估奠定了基础。
行动清单
原始出处:[Deepseek-math项目文档]