LLama 2
Llama 2 模型优化与训练策略解析
元数据
- 分类:人工智能、机器学习
- 标签:Llama 2、模型训练、拒绝采样、数据质量
- 日期:2025年4月12日
内容概要
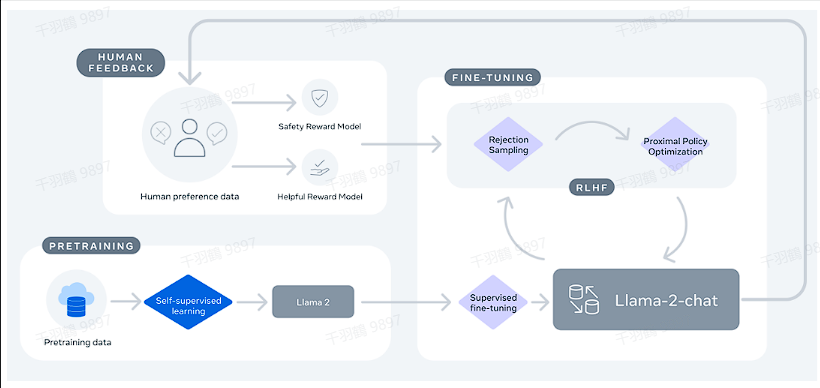
Llama 2 是一种新型的开放基础和微调聊天模型,相较于 LLaMA1,Llama 2 在模型结构和训练数据上进行了多项优化。本文将深入探讨这些改进以及其对模型性能的影响。
模型结构改进
Llama 2 在以下几个方面对模型结构进行了优化:
- GQA 增强:大参数模型引入了 GQA(Generalized Query Attention),虽然整体参数量有所减少,但模型的推理能力得到了提升。
- FFN 扩充:FFN(Feed-Forward Network)模块的矩阵维度扩展,增强了模型的泛化能力。
- 上下文窗口延长:上下文窗口从 LLaMA1 的 2K 增加到 4K,能够处理更长的文本输入。
训练数据策略
Llama-2 采用了来自公开可用源的 2T 数据 token 进行预训练。尽管公开数据丰富,Meta 强调数据质量的重要性,选择使用自有标注数据以确保高质量训练。不同的数据源和标注供应商显著影响下游微调结果,强调了数据检查的重要性。

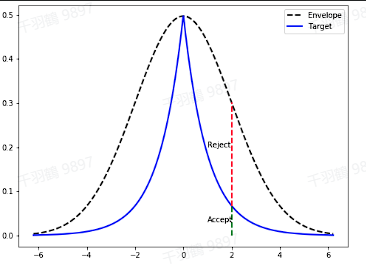
拒绝采样方法
拒绝采样(Reject Sampling, RS)是一种从目标概率分布中获取样本的蒙特卡洛方法。在 LLM 中,模型对同一提示生成多个响应,并利用奖励模型对这些答案进行评分,选出得分最高的答案。这一过程提升了生成质量,并为模型进一步训练提供了优质样本。
后训练总结
- SFT 阶段:SFT(Supervised Fine-Tuning)阶段不应停留太久,通常一万个样本足以达到标注员水平。
- 奖励模型语料构建:建议从自身模型中获取数据,以提升奖励模型的效果。
操作步骤
- ✅ 确定模型结构调整,如 GQA 增强和 FFN 扩充。
- ⚠ 收集并筛选高质量的训练数据。
- ❗ 实施拒绝采样以优化生成质量。
常见错误
小心选择数据源,不同数据源可能导致微调结果不一致。
💡 启发点
- 数据质量比数量更重要,少量高质量数据优于大量低质量数据。
行动清单
原始出处:[Llama 2: Open Foundation and Fine-Tuned Chat Models]