GShard
元数据
分类:机器学习架构
标签:GShard, 条件计算, 自动分片, 专家模型, 负载均衡
日期:2025年4月12日
内容处理
核心观点总结
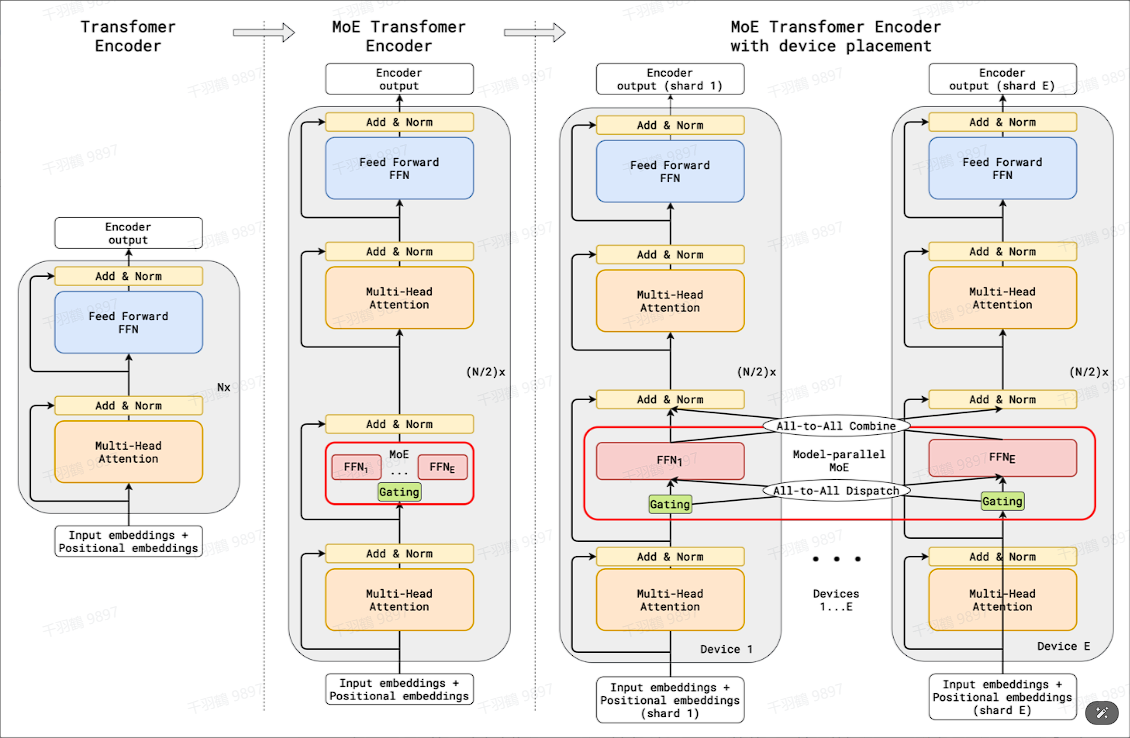
GShard是一个用于扩展巨型模型的架构,通过条件计算和自动分片实现高效的模型训练。其核心在于使用Gate来判断每个token应该发送到哪个expert,并采用top2Expert策略来确保计算效率。为了处理token溢出,GShard引入了drop tokens和zero padding机制。此外,为了保证专家负载均衡,还使用了一种辅助损失函数。
重点段落提取
-
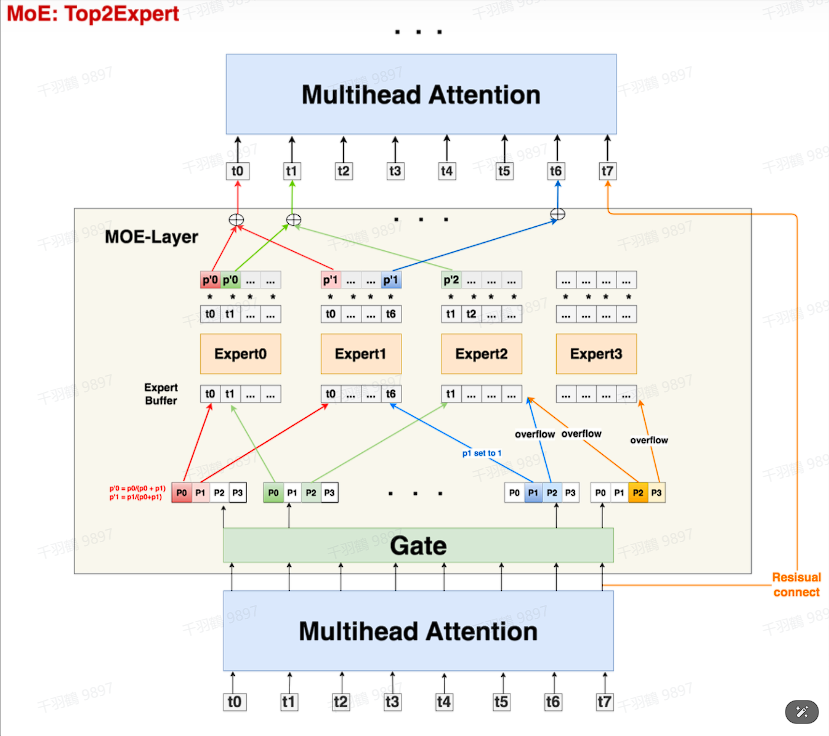
Gate机制:使用线形层Gate判断token应该送去哪个expert,尺寸大小为
,其中 表示expert数量。输入数据 过Gate后,得到prob数据 ,表示每个token去向每个expert的概率。 -
Expert与溢出处理:设置expert buffer来处理token溢出,每个expert接收的token上限为
。如果单个expert溢出,则调整权重值为1;若两个expert都溢出,则通过残差连接直接送至下一层。 -
随机路由与辅助损失函数:在选择第二个expert时,通过加噪处理和mask操作来确定最终的top2Expert,并通过辅助损失函数来保证负载均衡。
技术术语转述
- Gate:类似于路由器,决定数据流向哪个专家。
- Expert Buffer:专家的缓存区,用于存储待处理的token。
- Drop Tokens:丢弃无法正常处理的溢出token。
- Zero Padding:用零填充未使用的缓存区位置。
- Random Routing:通过随机噪声影响选择第二个专家。
操作步骤
- ✅ 使用Gate确定每个token的去向。
- ⚠ 设置expert buffer以处理溢出情况。
- ❗ 在发生溢出时,调整权重或通过残差连接发送至下一层。
- ✅ 使用随机路由策略选择第二个专家。
- ❗ 引入辅助损失函数以确保负载均衡。
常见错误
注意在设置expert buffer时,确保其容量计算正确,以避免过多token溢出导致模型性能下降。
💡启发点
GShard通过条件计算和自动分片的结合,提供了一种有效扩展巨型模型的方法,同时通过负载均衡机制提高了计算效率。
行动清单
- 研究GShard在不同任务上的性能表现。
- 探索其他MoE架构中的路由机制。
- 实验不同的辅助损失函数对负载均衡的影响。
数据转换
| Token 数量 | Expert 数量 | 每个 Expert 接收 Token 上限 |
|---|---|---|
| 8 | 4 | 4 |
公式显示
原始出处:论文《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》