深度偏好优化(DPO)损失函数解析与代码示例
分类
自动推断
标签
深度学习, 损失函数, 优化算法, 对比学习, 人类偏好
日期
2025年4月12日
内容概要
深度偏好优化(DPO)是一种旨在使模型输出与人类偏好对齐的技术。其核心思想是通过对比学习的方式,优化模型在选择与拒绝回答的概率差异。本文将详细解析DPO损失函数的原理,并提供相关代码示例。
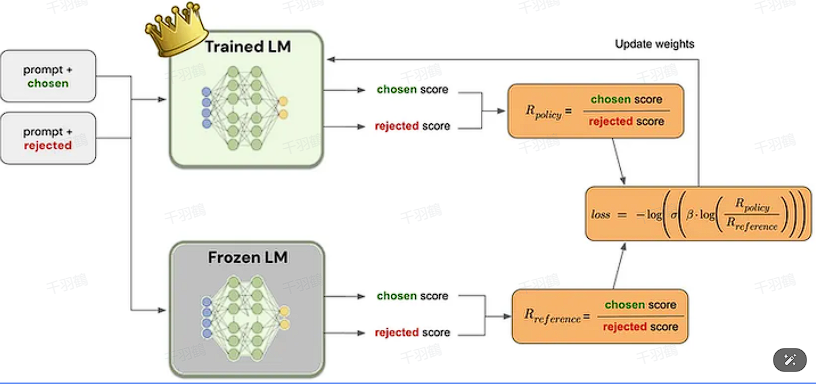
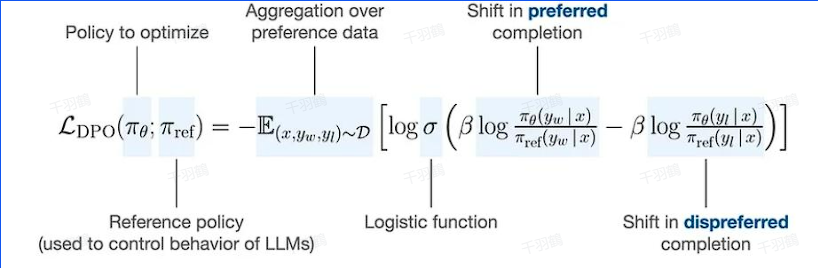
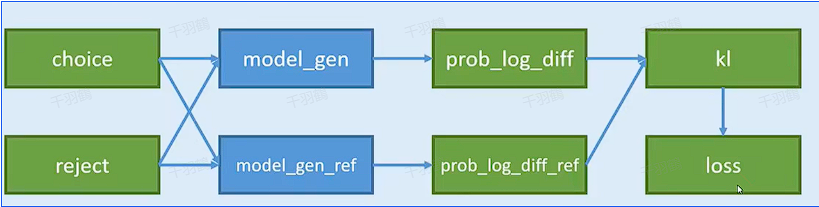
理解DPO损失函数
DPO损失函数的目标是最大化偏好回答与不偏好回答之间的概率差值。理想情况下,偏好回答的概率会增加,而不偏好回答的概率会减少,从而实现与人类偏好的对齐。
💡启发点:DPO通过约束概率差值而非绝对概率,提供了灵活的优化方式。
核心代码解析
下面是DPO损失函数的代码示例:
class DPOLoss(nn.Module):
"""
DPO Loss
"""
def __init__(self, beta: float, label_smoothing: float = 0.0, ipo: bool = False) -> None:
super().__init__()
self.beta = beta
self.label_smoothing = label_smoothing
self.ipo = ipo
def forward(
self,
policy_chosen_logps: torch.Tensor,
policy_rejected_logps: torch.Tensor,
reference_chosen_logps: torch.Tensor,
reference_rejected_logps: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
pi_logratios = policy_chosen_logps - policy_rejected_logps
ref_logratios = reference_chosen_logps - reference_rejected_logps
logits = pi_logratios - ref_logratios
if self.ipo:
losses = (logits - 1 / (2 * self.beta)) ** 2
else:
losses = (
-F.logsigmoid(self.beta * logits) * (1 - self.label_smoothing)
- F.logsigmoid(-self.beta * logits) * self.label_smoothing
)
loss = losses.mean()
chosen_rewards = self.beta * (policy_chosen_logps - reference_chosen_logps).detach()
rejected_rewards = self.beta * (policy_rejected_logps - reference_rejected_logps).detach()
return loss, chosen_rewards, rejected_rewards
操作步骤
✅ 理解损失函数公式:通过对比学习最大化概率差值。
⚠ 注意参数设置:
❗ 检查代码实现:确保代码逻辑与理论一致。
常见错误
警告:在实践中可能出现选择和拒绝概率同时下降的情况,因为DPO仅约束差值。
行动清单
- 探索不同的正则化手段以优化DPO。
- 测试不同的
值对模型输出的影响。 - 研究其他对比学习方法与DPO结合的效果。
数据转换
| 参数 | 描述 |
|---|---|
| 控制损失函数敏感度 | |
| 标签平滑 | 减少过拟合风险 |
公式显示
公式在代码中使用:
来源标注
原始出处:深度学习损失函数解析