BART
BART: Bidirectional and Auto-Regressive Transformers
元数据
- 分类:自然语言处理
- 标签:BART, Transformer, NLP, 文本生成, 文本理解
- 日期:2025年4月12日
内容概述
BART是一种基于Transformer架构的模型,结合了双向和自回归的特性。它在文本生成任务中表现优异,同时也能在文本理解任务中取得领先的效果。
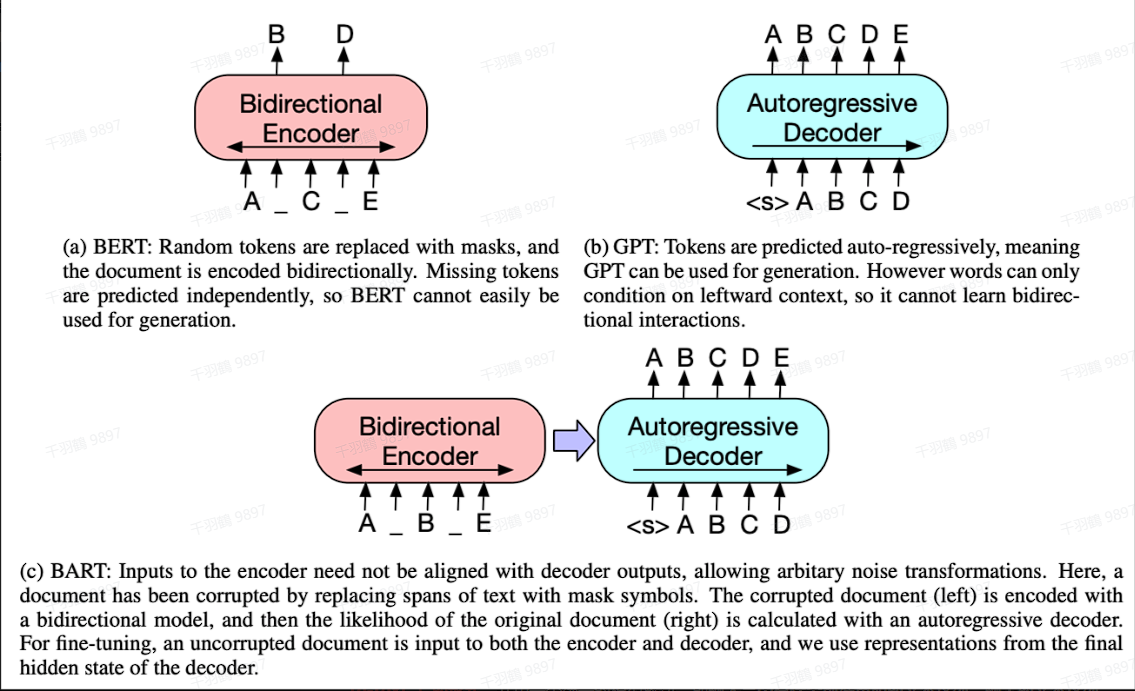
核心观点
- 模型架构:BART采用标准的encoder-decoder结构,并进行了若干调整。
- 激活函数与参数初始化:与GPT类似,BART使用GeLU激活函数,参数初始化服从正态分布
。 - 层数配置:BART base模型的Encoder和Decoder各有6层,而large模型则扩展到12层。
- cross-attention:解码器的各层对编码器最终隐藏层额外执行cross-attention。
- 与BERT的区别:BERT在词预测之前使用了额外的Feed Forward Layer,而BART没有。
- 应用场景:相比GPT,BART增加了双向上下文语境信息,更适合文本生成。
技术术语简化
- Encoder-Decoder:一种用于处理输入数据并生成输出数据的结构,类似于翻译系统。
- GeLU激活函数:一种数学函数,用于帮助神经网络学习复杂模式。
- cross-attention:一种机制,允许解码器更好地理解编码器生成的信息。
操作步骤
- ✅ 将ReLU激活函数替换为GeLU。
- ✅ 初始化参数为正态分布
。 - ⚠ 确保解码器的各层执行cross-attention。
常见错误
⚠ 在实现BART时,容易忽略cross-attention机制,这会导致模型性能下降。
💡启发点
BART在文本生成任务中的双向上下文语境信息是其优于GPT的一大创新点。
行动清单
- 研究BART在其他NLP任务中的应用潜力。
- 比较BART与其他Transformer模型在不同任务中的表现。
- 探索BART与其他激活函数的兼容性。
来源:原始内容提供者不详,内容经过处理和总结。