T5
T5模型:通用语言处理的文本到文本转换
元数据
- 分类:自然语言处理
- 标签:T5模型, 文本转换, 预训练, 自然语言处理
- 日期:2025年4月12日
内容概述
T5(Text-to-Text Transfer Transformer)是一种基于编码器-解码器架构的预训练语言模型。其核心理念是将所有自然语言处理任务转化为文本到文本的形式,并通过一个统一模型来解决。这种方法特别适用于多种任务,如机器翻译、问答系统、抽象摘要和文本分类。T5的训练方式类似于BERT,但其创新之处在于使用了更大的数据集和模型参数。
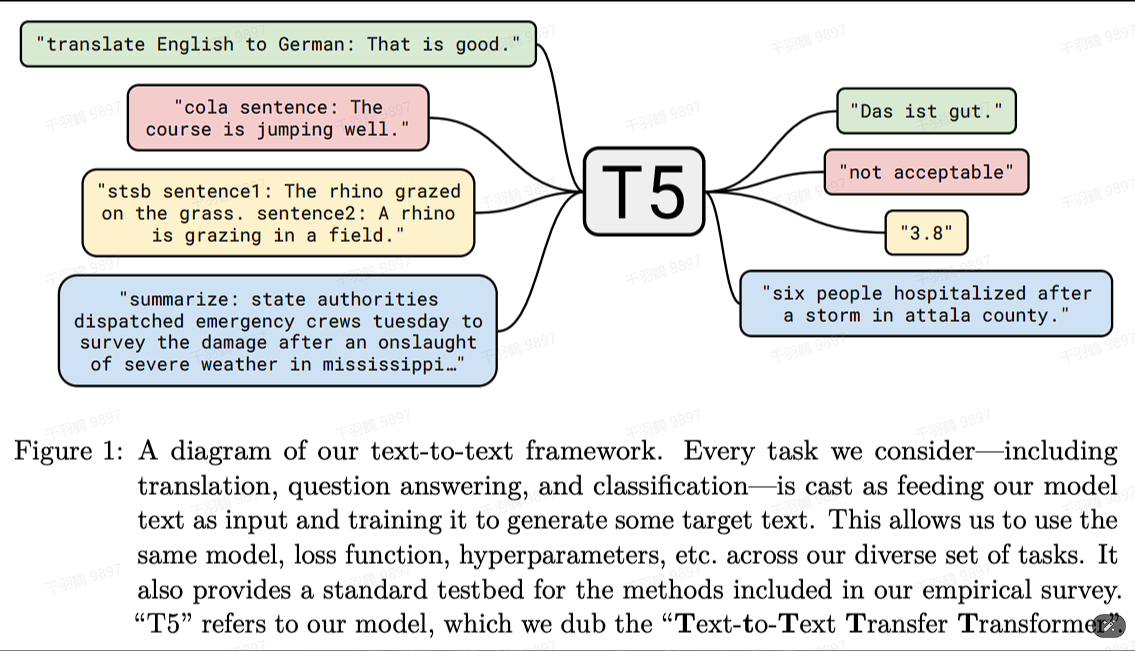
关键点
T5模型的核心思想
T5模型的基本思想是将自然语言问题转化为“文本到文本”的形式。输入是带有任务前缀声明的文本序列,而输出则是相应任务的结果。这种统一的处理方式使得模型在应对不同任务时无需进行结构上的调整。
任务与数据集
T5主要关注以下四个任务:
- 机器翻译
- 问答系统
- 抽象摘要
- 文本分类
此外,T5还贡献了一个名为C4(Colossal Clean Crawled Corpus)的语料库,支持其大规模数据训练。
模型训练方式
与BERT相似,T5采用掩码语言模型的方法进行训练,但不同之处在于T5会掩码连续的三个词,并仅预测被掩码的部分词。这种方法强调使用大量数据和更大的模型参数(高达11B参数)。
操作步骤
- ✅ 将自然语言问题转化为带有任务前缀的文本序列。
- ⚠ 使用统一的T5模型进行文本到文本转换。
- ❗ 利用C4语料库进行大规模数据训练。
常见错误
警告:
在使用T5进行任务转换时,务必确保输入文本序列的格式正确,尤其是任务前缀声明部分。如格式不当,可能导致模型输出不准确。
💡启发点
T5模型通过统一的文本到文本转换方法简化了多任务处理流程,这种方法不仅提高了模型的适应性,还减少了对不同任务进行个性化调整的需求。
行动清单
- 研究如何有效地将其他自然语言处理任务转化为文本到文本形式。
- 探索T5模型在不同领域应用中的表现。
- 关注C4语料库的更新和扩展,以支持更广泛的数据训练。
来源:[原始出处]