介绍
BERT: 深度学习中的革命性语言模型
元数据
- 分类:自然语言处理
- 标签:BERT, 预训练模型, NLP, 深度学习
- 日期:2025年4月12日
内容处理
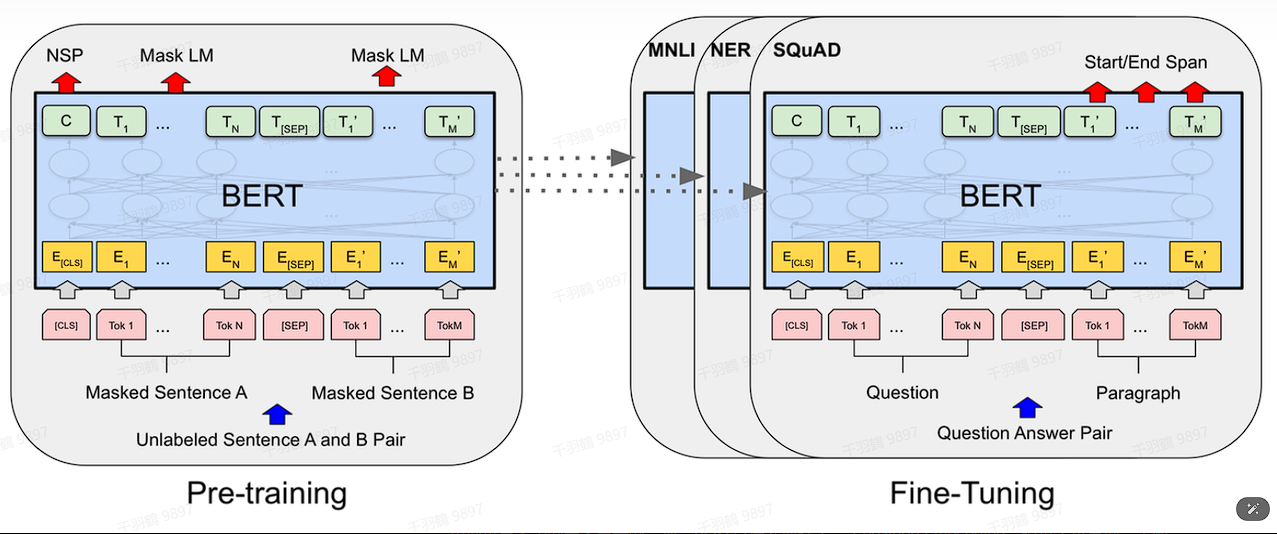
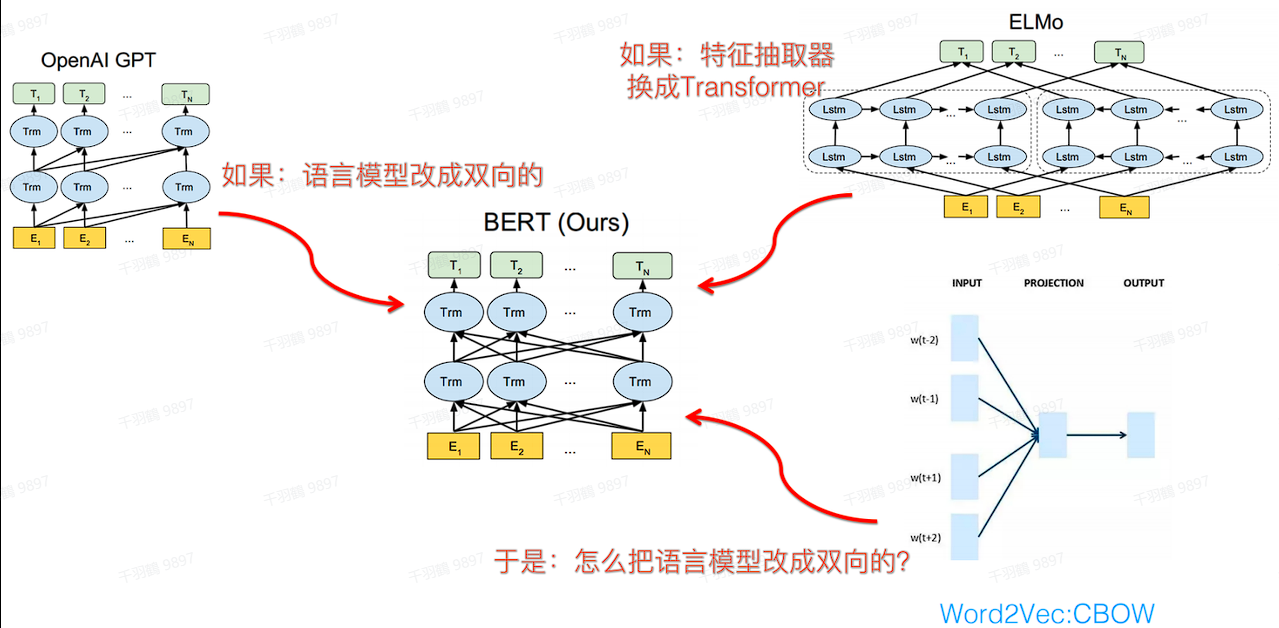
BERT(Bidirectional Encoder Representation from Transformers)是一种用于自然语言处理的预训练模型,主要用于替代传统的Word2Vec。通过两个核心任务:Masked Language Model (MLM) 和 Next Sentence Prediction (NSP),BERT可以学习更丰富的文本表征。

BERT Embedding
BERT的输入编码向量由三个嵌入特征组成:
- 位置嵌入:将单词的位置信息编码为特征向量,帮助模型理解单词之间的位置关系。
- Token嵌入:将单词分解为更小的token,例如‘playing’被拆分成‘play’和‘ing’。
- Segment嵌入:用于区分两个句子,例如判断句子B是否为句子A的后续部分。
Masked LM (MLM)
在训练过程中,约15%的单词会被替换为[MASK],并通过上下文预测这些被掩盖的单词。具体步骤包括:
✅ 80%的tokens替换为[MASK]以融合双向语义信息。
⚠ 10%的tokens替换为随机单词以增强纠错能力。
❗ 10%的tokens保持不变以提供模型偏向。
Next Sentence Prediction (NSP)
BERT通过成对的句子进行训练,预测第二个句子是否是原始文档中的后续句子。50%的句子对是前后关系,另50%是随机组合。
常见错误
⚠ 在使用BERT进行微调时,务必确保输入数据格式正确,否则可能导致不准确的预测结果。
💡启发点
- BERT通过双向语境学习解决了一词多义的问题。
- 使用随机替换和保持不变的方法提高了模型的泛化能力。
行动清单
- 探索BERT在不同NLP任务中的应用。
- 研究其他预训练模型与BERT的比较。
- 实施BERT微调以提高特定任务的性能。
数据转换
| 特征类型 | 描述 |
|---|---|
| 位置嵌入 | 编码单词位置信息 |
| Token嵌入 | 将单词拆分为小单位 |
| Segment嵌入 | 区分句子对中的两个句子 |
来源标注
原始来源:[选自提供文本内容]