DeepSeek-R1
Introduce
元数据
分类:人工智能技术
标签:强化学习,深度学习,模型蒸馏,推理性能,人工智能
日期:2025年4月12日
内容概述
本文探讨了通过纯粹的强化学习(Reinforcement Learning)增强深度学习模型的推理能力,特别是介绍了DeepSeek-R1和DeepSeek-R1-Zero模型。DeepSeek-R1-Zero无需SFT(监督微调)即通过RL训练展现出强大的推理行为,而DeepSeek-R1通过多阶段训练和冷启动数据解决了Zero模型的可读性差等问题。此外,本文还研究了从DeepSeek-R1蒸馏到小模型的效果。
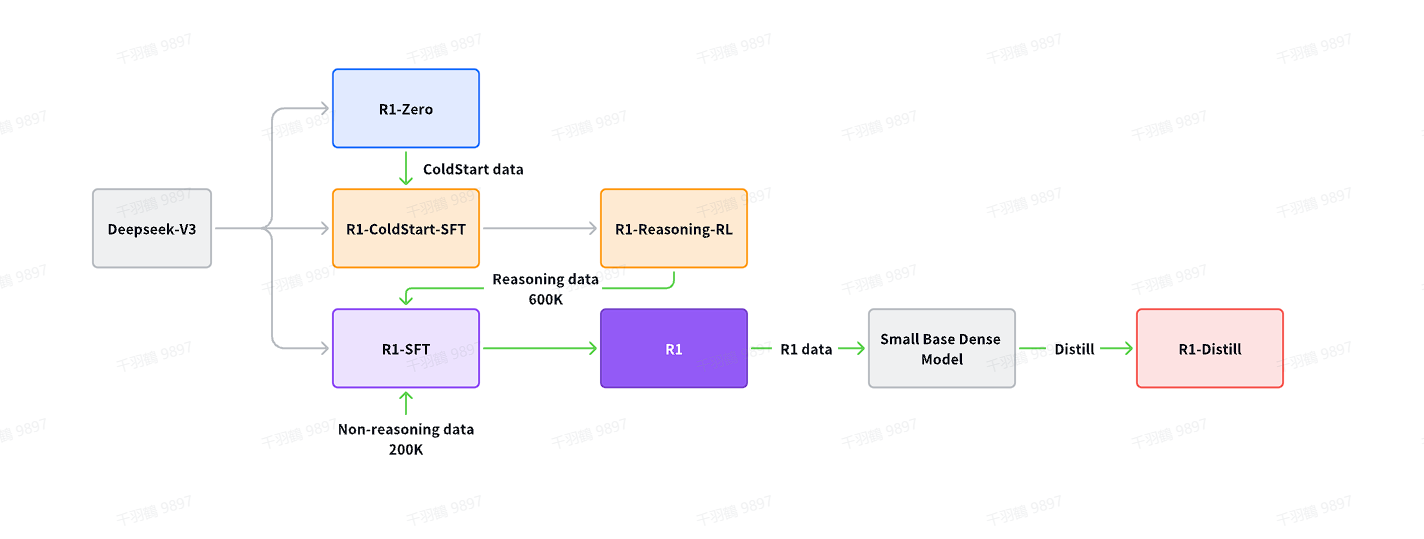
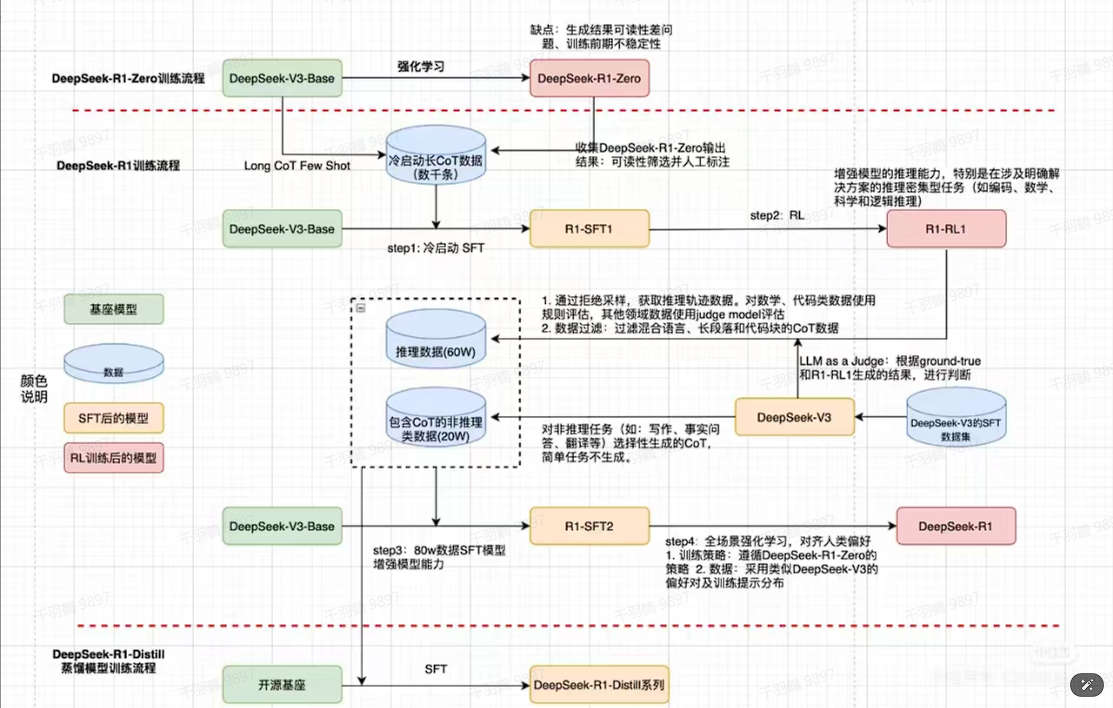
研究背景与内容
研究背景
- Post-training提高推理任务准确性,与社会价值对齐,适应用户偏好。
- OpenAI通过增加思想链CoT推理过程的长度引入inference-time scaling。
- 后续工作探索test-time scaling,包括PRM、MCTS和Beam Search等,但未达到OpenAI-o1的水平。
研究内容
- 使用纯粹RL增强大模型推理能力,不使用SFT微调。
- DeepSeek-R1-Zero出现可读性低、语言混合的问题,通过冷启动数据和多阶段训练解决。
- 从DeepSeek-R1蒸馏到小模型,取得良好效果。
研究贡献
强化学习在大模型上的应用
- 在Deepseek-V3-base上进行大规模强化学习,展示self-verification、reflection和生成长CoT功能。
- 大模型可以纯靠强化学习学习,而不需要SFT过程。
蒸馏技术的应用
- 较大模型的推理模式可以很好地蒸馏到较小模型,取得很好的成绩。
操作步骤
- ✅ 进行大规模强化学习训练。
- ⚠ 使用冷启动数据解决语言混合问题。
- ❗ 应用多阶段训练提升模型性能。
- ✅ 从DeepSeek-R1蒸馏至小模型。
常见错误
⚠ 注意在强化学习过程中可能出现的可读性低、语言混合问题,需要通过适当的数据处理和训练策略解决。
💡启发点
- 利用纯粹的强化学习方法,不依赖于传统的微调步骤,展示了深度学习推理的新可能性。
行动清单
- 探索更多RL在不同模型上的应用。
- 研究蒸馏技术在其他领域的潜力。
- 优化冷启动数据策略以提高模型性能。
原始出处:DeepSeek-R1论文链接
Method
强化学习算法
重点段落
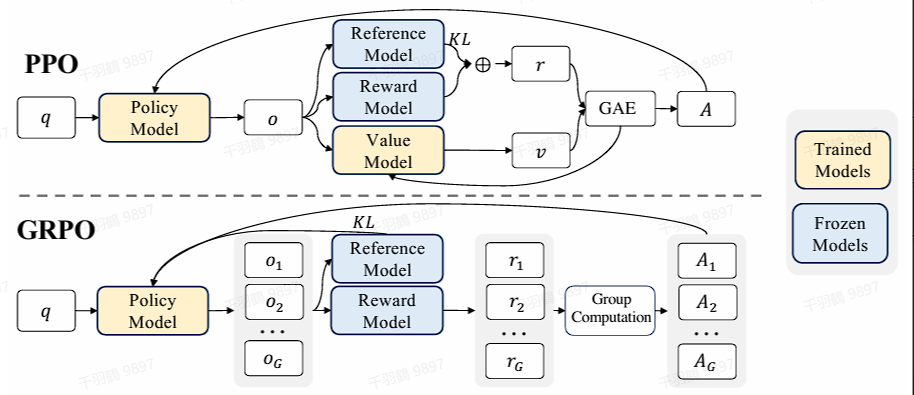
强化学习算法的优化
GRPO算法使用自家的PPO算法进行优化,通过对相同问题产生的多个采样输出的平均奖励作为value的估计值,去掉了Value model,从而简化了训练过程。对于每个问题,GRPO从旧策略中采样一组输出,然后Reward model对这些回答给予奖励值,最后奖励值的平均值作为value的估计。
优化公式
优化公式如下:
优势函数计算
优势函数通过下式计算:
奖励建模
奖励建模核心观点
奖励是强化学习(RL)的关键组成部分,提供训练信号并决定优化方向。本文设计了两种基于规则的奖励机制:
- 正确率奖励(Accuracy):评估生成答案的正确性。对于数学问题,模型生成固定格式的答案以便验证;编程任务则通过测试用例和编译器验证。
- 格式奖励(Format):强制模型将思维过程生成在指定的标签内,以确保结构化输出。
由于奖励过度利用问题,本文没有使用ORM或PRM奖励模型。
训练模板设计
本文设计了一个简单的训练模板,引导基础模型遵循指令。模板要求模型首先生成推理过程,然后给出最终答案,以避免偏差,比如强制进行反思性推理或推广特定解题策略。

性能
DeepSeek-R1-Zero在无需监督微调数据的情况下,通过强化学习获得强大的推理能力,其在AIME benchmark上的性能随着训练进展而稳定提升,并且可以通过多数投票进一步增强性能。
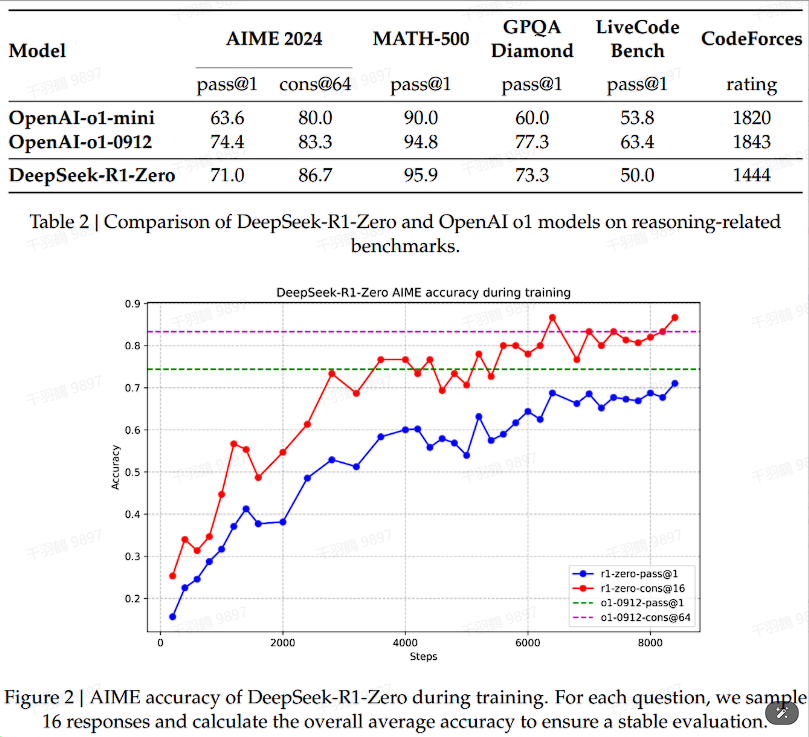
self-evolution
关键段落
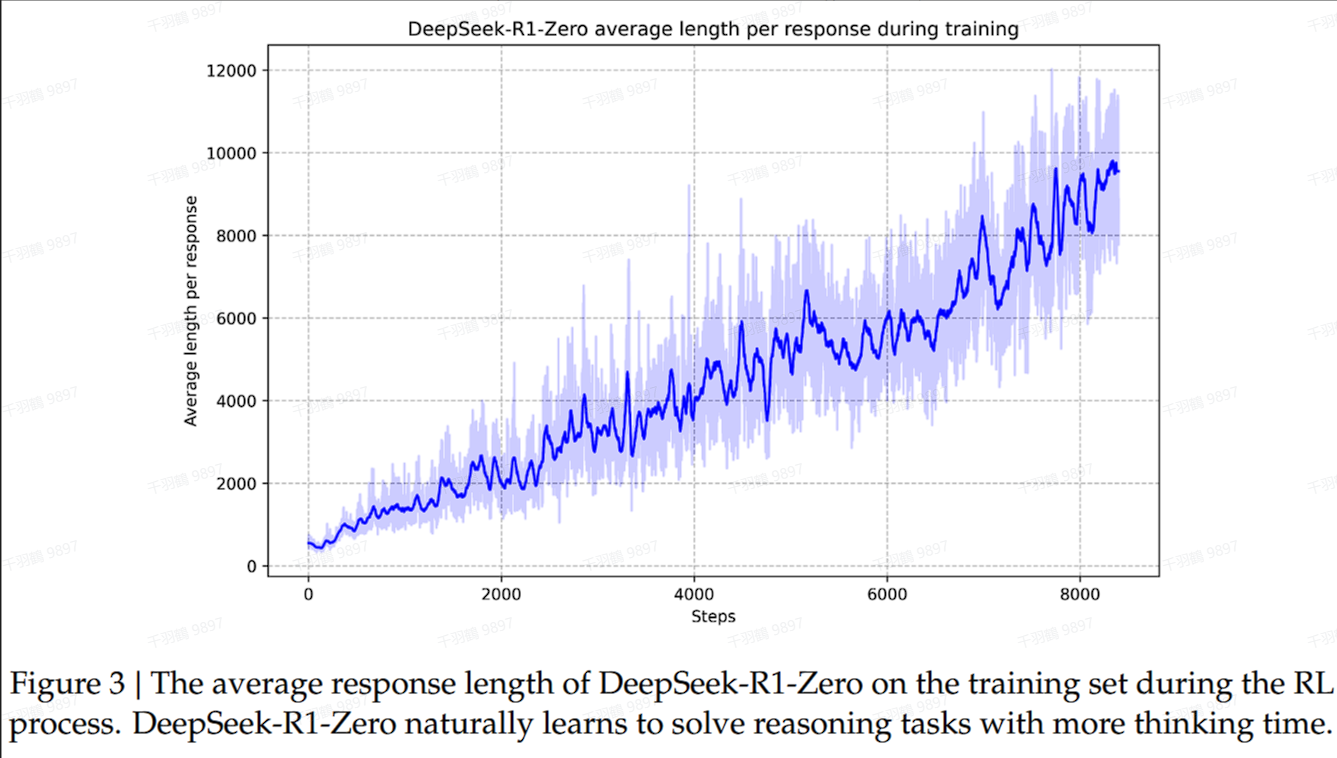
自我进化过程
DeepSeek-R1-Zero在训练过程中表现出自我进化能力。随着训练步数的增加,模型的回答长度和思考时间几乎线性增长。这种提升源于模型内部的自我调整,而非外部的干预。
复杂行为表现
随着测试时间的增加,模型开始表现出复杂行为,例如反思行为。模型会重新审视和评估其先前步骤,并自发探索解决问题的替代方法。这些行为是模型与强化学习环境互动的结果,而不是预先编程设定的。
技术术语解释
- 自我进化:指模型在训练过程中通过内部机制自动提升性能,而不依赖外部调整。
- 反思行为:模型在解决问题时,会重新评估其过去的步骤并尝试新的方法。
💡启发点
DeepSeek-R1-Zero通过自我进化展现了深度学习模型在复杂环境中自动提升性能的潜力。
DeepSeek-R1-Zero的Aha Moment
💡 启发点:DeepSeek-R1-Zero模型在优化过程中,通过重新评估初始方法,为问题分配更多思考时间,这种自我改进的能力展示了强化学习的强大与优雅。

强化学习的核心价值
通过为模型提供正确的奖励信号,DeepSeek-R1-Zero无需明确指导,便能自主学习出更优的问题解决策略。这种方法不仅减少了人为干预,还体现了强化学习在复杂任务中的潜力。
DeepSeek-R1-Zero的缺点与局限性
尽管推理能力显著提升,但DeepSeek-R1-Zero也存在以下问题:
- 可读性低:生成内容的语言结构复杂,难以理解。
- 语言混合问题:输出中可能出现多语言混杂的情况,影响用户体验。
操作步骤:如何优化DeepSeek-R1-Zero的使用
以下是优化模型性能的关键步骤:
✅ 重新定义奖励机制:为模型提供更明确、更贴近任务目标的奖励信号。
⚠ 监控语言输出:检测并纠正潜在的语言混杂问题。
❗ 提升可读性:通过后处理算法简化输出语言结构,提高用户可读性。
提高模型推理性能与用户友好性方法探讨
元数据
- 分类:人工智能模型训练
- 标签:强化学习、冷启动、语言一致性、推理性能、用户友好
- 日期:2025年4月12日
核心观点总结
本文探讨了如何通过冷启动数据和强化学习方法提高模型的推理性能及用户友好性。主要研究问题包括利用少量高质量数据加速模型训练,以及如何训练出具备通用能力且能产生清晰连贯推理过程的模型。
重点段落
冷启动的作用
冷启动数据用于稳定强化学习初期训练。通过构建和收集少量高质量的长思维链(CoT)数据,微调模型以作为初始策略。此过程帮助防止早期训练不稳定,并提供一个较好的初始策略。
推理过程中的语言一致性奖励
在强化学习训练中引入语言一致性奖励与推理正确性奖励。计算基于思维链中目标语言单词的比例,从而提升模型在多语言环境下的推理能力。
数据收集与处理
推理数据通过设计推理提示和拒绝采样生成,合并额外数据扩展数据集。非推理数据则采用DeepSeek-V3 pipeline重用部分SFT数据集,共计800K数据用于SFT训练。
技术术语转述
- 冷启动:在模型训练初期使用少量高质量数据稳定训练过程。
- 思维链(CoT):一种用于记录和分析模型推理过程的数据结构。
- 拒绝采样:一种选择正确响应的方法,通过多次采样确保质量。
操作步骤
- ✅ 构建并收集长思维链数据以微调模型。
- ⚠ 使用语言一致性奖励提升多语言环境下的推理能力。
- ❗ 通过拒绝采样确保推理数据质量。
常见错误
在强化学习过程中忽视语言一致性可能导致推理结果不准确或混乱。
💡启发点
引入语言一致性奖励是提升模型在多语言环境下表现的创新方法。
行动清单
- 研究其他领域的冷启动应用。
- 探索更多语言环境下的一致性奖励机制。
- 扩展现有数据集以提高模型通用能力。
数据转换
| 数据类型 | 数据量 |
|---|---|
| 推理数据 | 600K |
| 非推理数据 | 200K |
来源:原始出处未提供,内容基于选取文本进行总结与重构。
实验结果
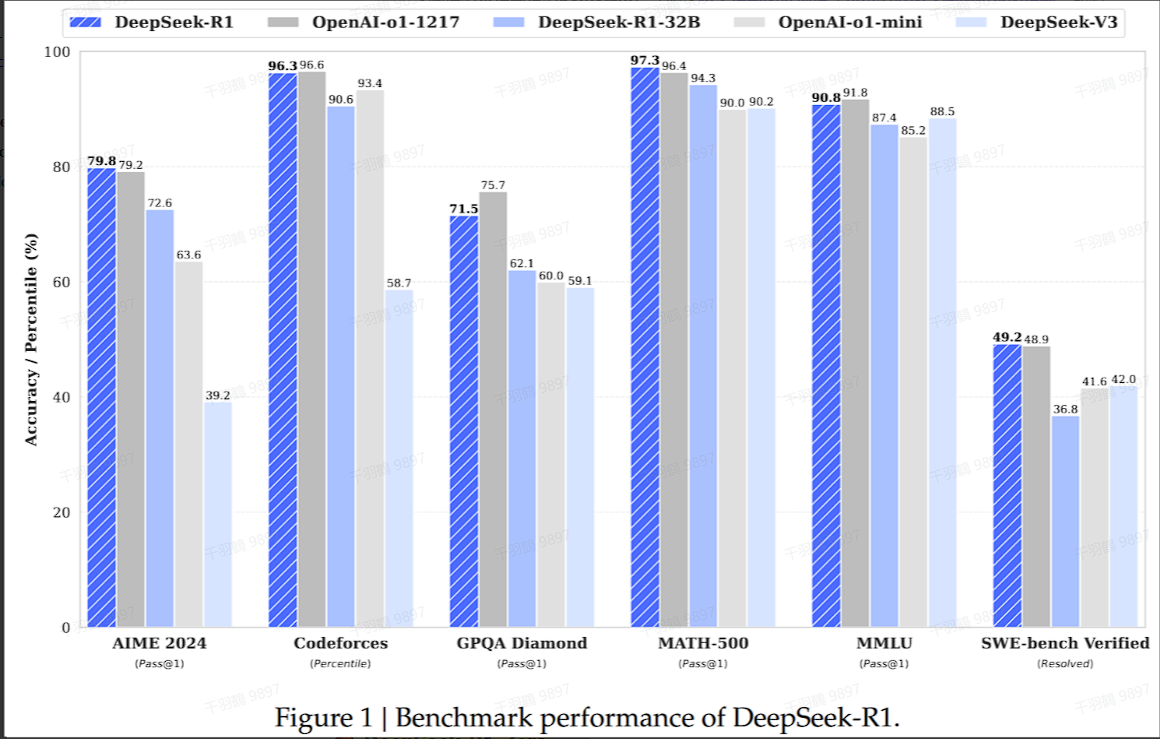
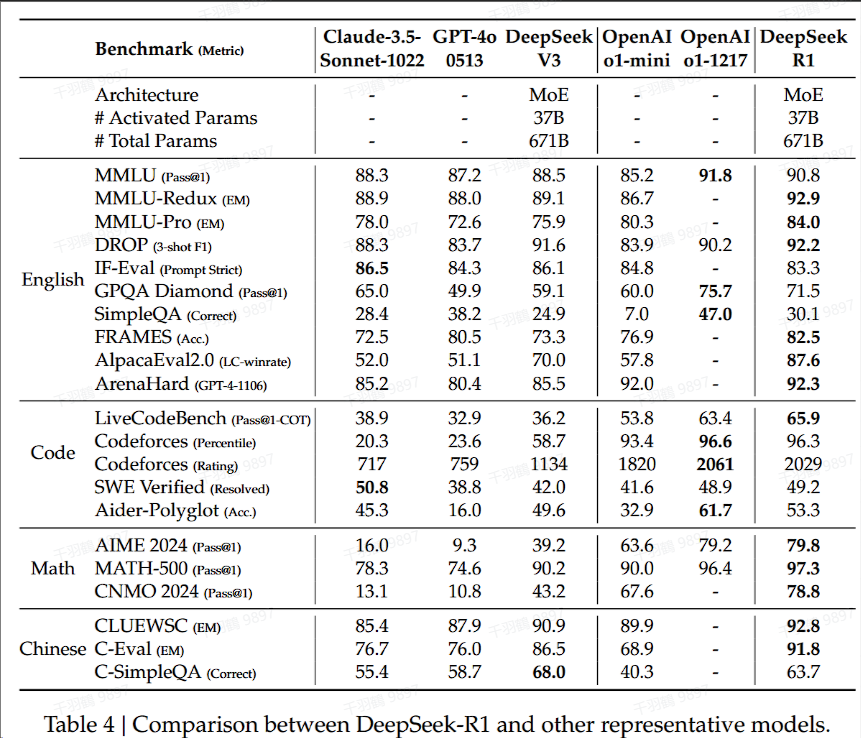
DeepSeek-R1在Chinese SimpleQA中的表现
DeepSeek-R1在Chinese SimpleQA中的表现不如DeepSeek-V3,主要原因在于它经过安全强化学习(safety RL)后,倾向于拒绝回答某些查询。在没有安全强化学习的情况下,DeepSeek-R1的准确率可以达到70%以上。
总结生成的长度分析
DeepSeek-R1生成的总结长度较为简洁。在ArenaHard上的平均长度为689个token,而在AlpacaEval 2.0上的平均长度为2218个token。这表明DeepSeek-R1避免了在评估过程中引入长度偏差(偏向于长的回答)。
蒸馏实验结果
核心观点总结
在蒸馏实验中,通过简单提取 DeepSeek-R1 的输出,可以有效提升 DeepSeek-R1-7B(又称为 DeepSeek-R1-Distill-Qwen-7B)的性能,使其在多个方面全面优于 GPT-4o-0513 等非推理模型。进一步的实验表明,DeepSeek-R1-14B 在所有评估指标上均超越了 QwQ-32BPreview,而 DeepSeek-R1-32B 和 DeepSeek-R1-70B 在大多数基准测试中也显著优于 o1-mini。对蒸馏模型应用强化学习能够带来显著的进一步提升。
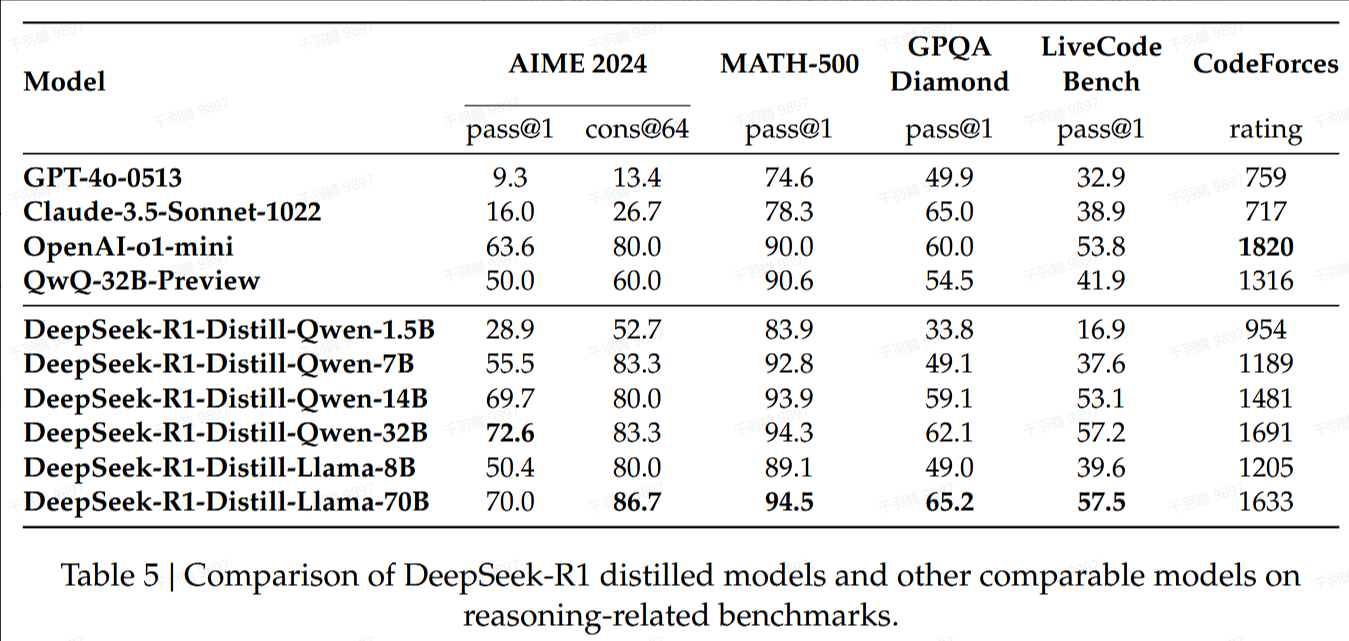
重点段落与数据
1. 蒸馏模型的性能提升
DeepSeek-R1-7B 通过简单提取输出就能全面优于 GPT-4o-0513。这表明在模型蒸馏过程中,适当的输出处理可以带来显著的性能提升。
2. 大规模模型的对比结果
| 模型 | 超越对象 | 评估结果 |
|---|---|---|
| DeepSeek-R1-14B | QwQ-32BPreview | 在所有指标上超越 |
| DeepSeek-R1-32B | o1-mini | 在大多数基准测试中显著超越 |
| DeepSeek-R1-70B | o1-mini | 在大多数基准测试中显著超越 |
💡启发点
通过简单的输出提取和强化学习应用,可以显著提升蒸馏模型的性能,这为未来的模型优化提供了重要的启发。
discussion
核心观点总结
在大规模模型优化中,蒸馏和强化学习是两种主要策略。尽管强化学习可以提升小模型的性能,但其计算成本高昂,且不一定能超越蒸馏策略的效果。蒸馏策略能够有效地将更强大的模型转化为更小的模型,提供经济高效的解决方案。然而,要突破智能的边界,依旧需要更强大的基础模型和大规模的强化学习。
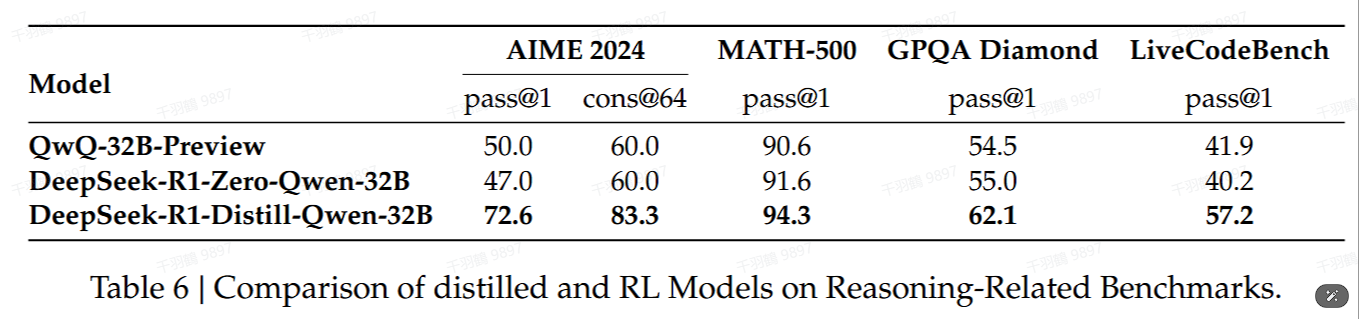
重点段落
-
蒸馏与强化学习对比
32B基础模型通过大规模强化学习训练后,其性能与QwQ-32B-Preview相当。而DeepSeek-R1-Distill-Qwen-32B在所有基准测试中明显优于DeepSeek-R1-Zero-Qwen-32B。 -
蒸馏策略优势
更强大的模型蒸馏成更小的模型会产生优异的结果。虽然蒸馏策略既经济又有效,但超越智能的边界可能仍然需要更强大的基础模型和更大规模的强化学习。 -
PRM过程奖励模型挑战
在一般推理中,明确定义细粒度步骤具有挑战性;使用模型进行自动标注可能无法得到满意的结果,而手动标注则不利于规模化。
技术术语解释
- 蒸馏(Distillation): 将一个复杂的模型转化为一个较小且高效的版本,同时保持其性能。
- 强化学习(Reinforcement Learning, RL): 一种机器学习方法,通过奖励机制来训练模型,使其在特定任务中表现更好。
- PRM(过程奖励模型): 用于评估和指导模型推理过程的奖励机制。
操作步骤
- ✅ 使用大规模数据集进行基础模型训练。
- ⚠ 选择合适的蒸馏策略,将复杂模型精简化。
- ❗ 应用强化学习以进一步提升小模型性能。
常见错误
警告: 强化学习过程中可能出现Reward-hacking现象,导致训练资源浪费。
💡启发点
- 蒸馏策略在资源有限的情况下提供了一种可行的高效解决方案。
- 强化学习在复杂任务中的潜力值得进一步探索。