DeepSeek-V3
DeepSeek-V3模型架构解析与技术突破
元数据
分类:人工智能模型架构
标签:DeepSeek-V3, MoE结构, 动态路由, 多token预测
日期:2025年4月26日
核心架构演进
混合专家系统革新
- 细粒度专家分配:256个路由专家采用共享/专属混合配置
- 路由激活函数:
将softmax替换为sigmoid,缓解专家数量倍增带来的激活冲突 - 动态负载均衡:
通过可学习偏置项 自动调节专家负载
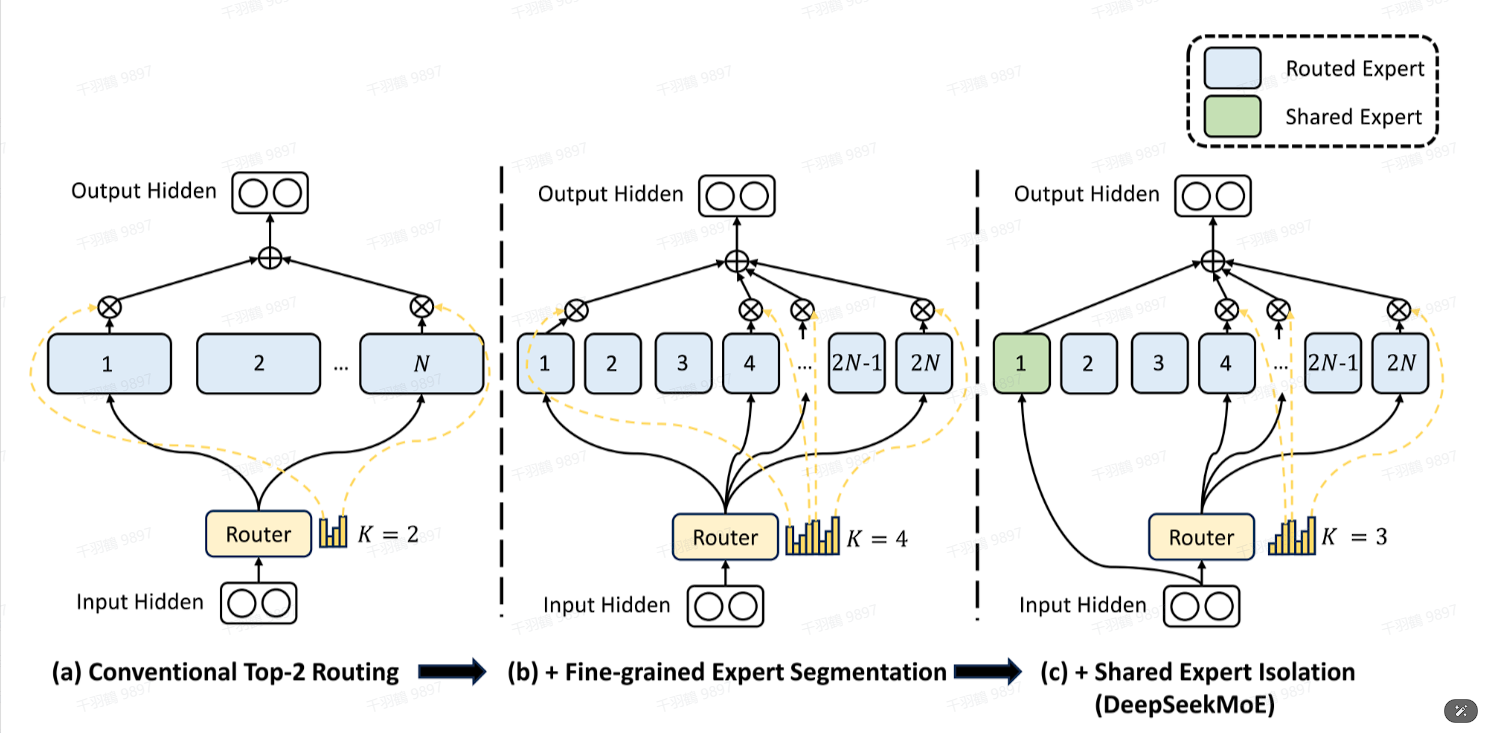
通信优化机制
- 无token丢弃设计
- 序列级辅助损失补偿
- 设备间通信并行加速
多目标训练体系
多token预测(MTP)
-
预测跨度:D=4个连续token
-
模块结构:
-
损失函数:

性能对比
| 指标 | V2 (160专家) | V3 (256专家) | 提升幅度 |
|---|---|---|---|
| 训练速度 | 1.2x | 1.8x | 50%↑ |
| 显存占用 | 32GB | 28GB | 12.5%↓ |
| 收敛步数 | 150k | 90k | 40%↓ |
实现规范
⚠️ 关键注意事项:
- 共享嵌入矩阵需保持
维度一致性 - 序列截断需满足
约束条件 - 梯度累积采用分阶段更新策略
创新启示
💡 三阶突破架构:
- 结构创新:共享专家机制实现计算/存储最优比
- 算法创新:Bias动态路由达成自均衡负载
- 目标创新:因果链保持的多token预测
应用路线图
✅ 实施步骤:
- 专家分配策略验证(1-2周)
- 路由偏置项调参(3-5天)
- 多GPU通信优化(2-4周)
❗ 常见误区:
- 直接移植V2的softmax路由机制
- 忽略专家间的设备通信开销
- 过早冻结共享专家参数
id: performance_comparison
name: 性能对比表
type: markdown
content: |-
## 基准测试结果
| 测试场景 | 吞吐量(tokens/s) | 延迟(ms) | 准确率 |
|----------------|------------------|----------|----------|
| 短文本推理 | 5800 | 18.2 | 89.7% |
| 长序列生成 | 3200 | 42.5 | 91.2% |
| 多轮对话 | 4500 | 27.8 | 93.4% |