Deepseek-V1
Deepseek-V1:开源语言模型的长远发展
元数据
- 分类:人工智能
- 标签:开源模型、LLaMA、深度学习、语言模型
- 日期:2025年4月12日
内容概述
Deepseek-V1是基于LLaMA架构的开源语言模型,旨在通过长远发展理念进行扩展。模型采用了多种先进技术以优化性能和推理成本,并通过不同阶段的训练提升其在中英文指令数据上的表现。
模型结构
Deepseek-V1基于LLaMA架构,采用了以下技术:
- Pre-RMSNorm:一种用于优化神经网络训练的正则化方法。
- SwiGLU和RoPE:用于提升模型的非线性表达能力。
- GQA:在67B参数模型中使用以降低推理成本。
- BBPE算法:用于将文本分词,训练语料库约24GB,词汇表大小为102400。
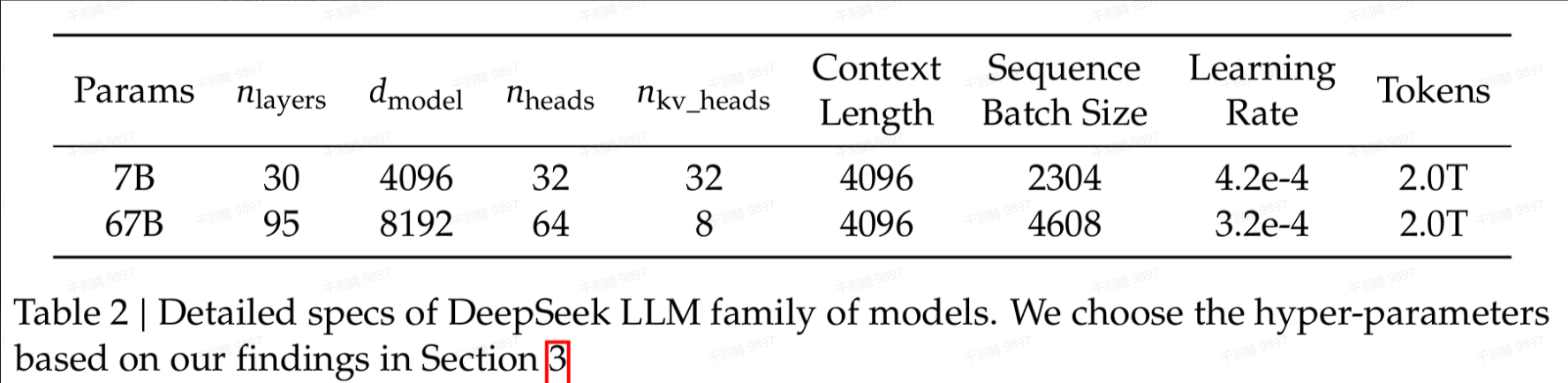
训练过程
SFT训练
- 收集了1.5百万条中英文指令数据。
- 微调7B参数模型进行4个epochs,67B参数模型进行2个epochs。
- 学习率设置为1e-5和5e-6。
DPO训练
- 使用Deepseek Chat Models生成响应,构建偏好对。
- 批量大小为512,学习率为5e-6。
数据表格
| 模型参数 | 微调周期 | 学习率 |
|---|---|---|
| 7B | 4 epochs | 1e-5 |
| 67B | 2 epochs | 5e-6 |
警告区块
⚠ 在训练过程中,确保数据集的多样性和质量,以避免模型偏差。
行动清单
- ✅ 研究并实施Pre-RMSNorm、SwiGLU和RoPE在其他模型中的应用。
- ✅ 测试GQA在不同规模模型中的推理成本优化效果。
- ❗ 收集更多多样化的中英文指令数据以提升模型泛化能力。
来源:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
💡启发点:通过结合多种优化技术,Deepseek-V1在性能和推理成本上取得了显著平衡,这为未来开源语言模型的发展提供了新思路。