GLM1
GLM1模型:通用语言模型预训练与自回归填空
元数据
- 分类:自然语言处理
- 标签:GLM1, 自回归填空, Transformer, 预训练
- 日期:2025年4月12日
内容概述
GLM1是一种基于Transformer的语言模型,通过自回归填空任务实现高效的语言模型预训练。它采用prefix-decoder结构,并使用二维位置编码技术来增强模型的性能。
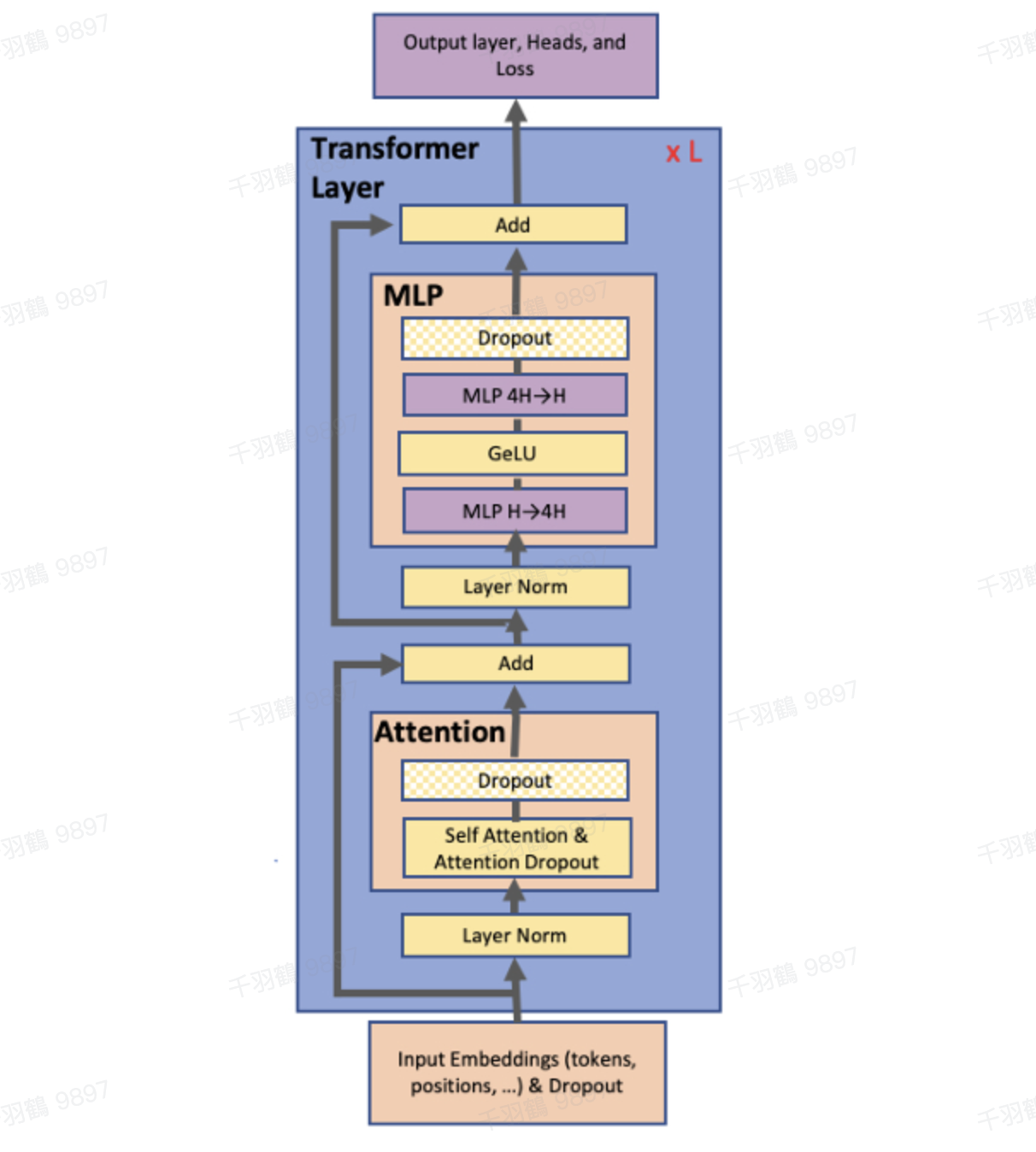
模型结构与创新点
GLM1使用了prefix-decoder结构,这实际上是Transformer的decoder部分,通过特殊的mask实现了文本的双向和单向attention。以下是GLM1模型的一些关键改动:
- Pre Deep Norm:在模型中加入了深度归一化层。
- 线性层输出:使用单层线性层进行token预测。
- 激活函数:从ReLU切换到GeLU。
💡启发点:GLM1通过自回归填空任务预训练语言模型,为条件生成和无条件生成任务提供了新的可能性。
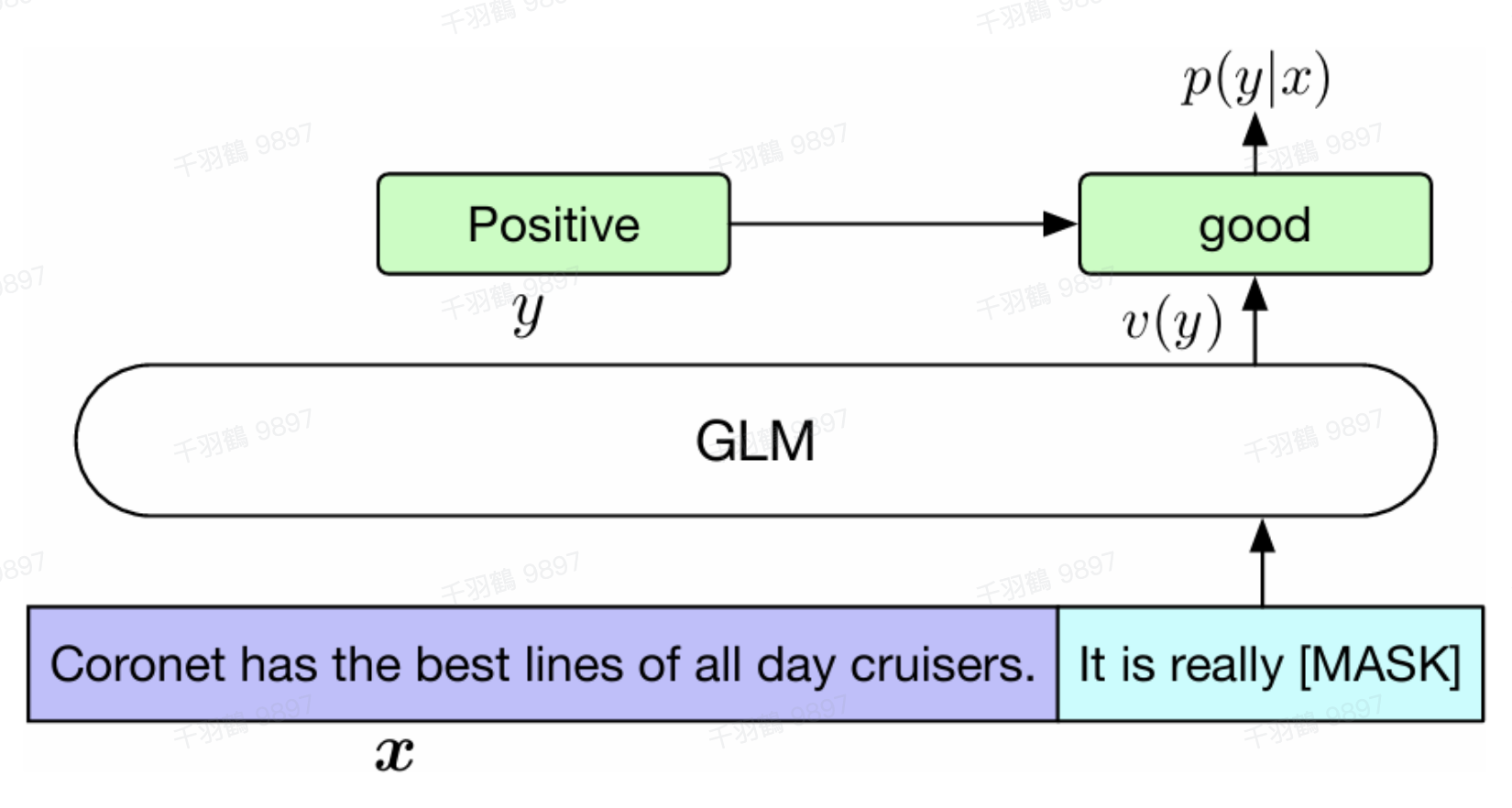
自回归填空任务
自回归填空任务结合了自编码和自回归思想:
- 自编码思想:在输入文本中随机删除连续的tokens。
- 自回归思想:顺序重建连续tokens,模型可以访问损坏文本和之前预测的spans。

通过改变缺失spans的数量和长度,自回归填空目标可以为条件生成和无条件生成任务预训练语言模型。
二维位置编码技术
GLM1采用二维位置编码技术:
- 位置标记:第一个位置id标记Part A中的位置,第二个位置id表示span内部的相对位置。
- 嵌入投影:位置id通过embedding表投影为两个向量,加入到输入token的embedding表达中。
多任务预训练策略
GLM1采用多任务预训练策略,以优化生成更长文本与空白填充目标:
- Doc-level文档级:从原始长度的50% - 100%范围内均匀采样一个span,旨在生成长文本。
- Sentence-level句子级:限制被mask的span必须是完整句子,采样多个span以覆盖原始token的15%。
操作步骤
- ✅ 使用prefix-decoder结构进行文本处理。
- ⚠ 确保二维位置编码技术正确应用。
- ❗ 在多任务预训练中平衡文档级和句子级目标。
常见错误
警告:在应用自回归填空任务时,注意不要过度依赖损坏文本,否则可能导致模型性能下降。
行动清单
- 研究GLM1的应用场景,如条件生成任务。
- 探索二维位置编码技术在其他模型中的应用。
- 测试多任务预训练策略对不同数据集的影响。
原始出处:[论文:GLM:General Language Model Pretraining with Autoregressive Blank Infilling]