GLM4
ChatGLM技术报告:大语言模型的创新与应用
元数据:
分类:人工智能技术
标签:ChatGLM, 大语言模型, 预训练, 对齐训练, 技术创新
日期:2025年4月12日
模型结构
ChatGLM的模型结构在多个方面进行了优化,以提升训练速度和性能:
- 除了QKV,其余部分都移除了bias,这不仅提升了训练速度,还改善了模型的长度外推性。
- 使用了RMSNorm、SwiGLU、RoPE等经典技术组合。
- GQA减少了MHA的参数量,因此FFN的隐藏层维度增加到了原来的10/3。
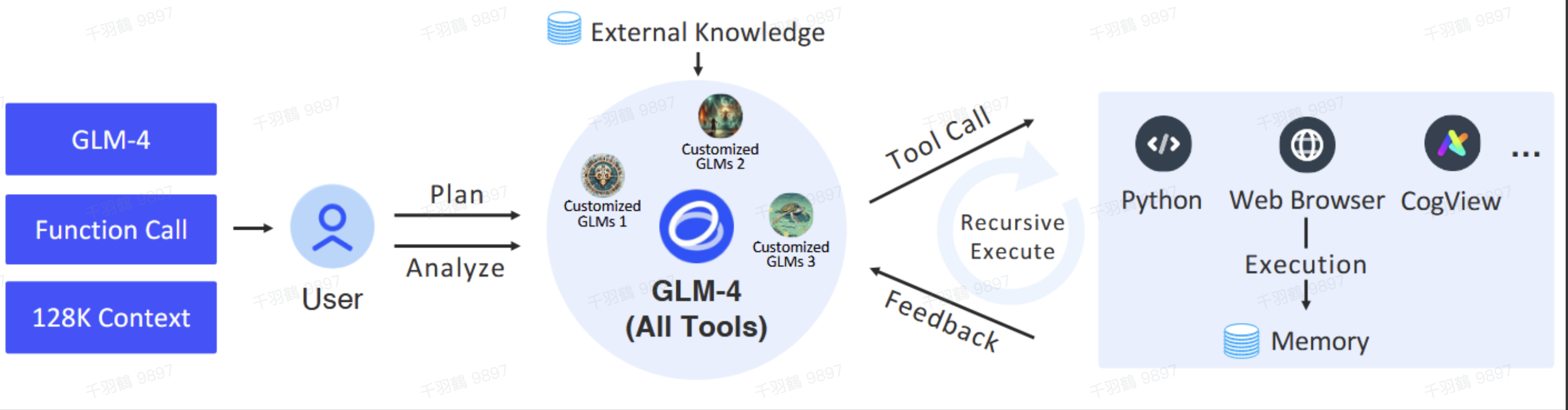
预训练数据处理
ChatGLM在预训练阶段使用了多语言文档,包括网页、维基百科、书籍、代码及研究论文。数据处理步骤如下:
✅ 去重处理:确保数据的唯一性,减少冗余信息。
⚠ 筛选:选择高质量的数据源。
❗ 分词:对文本进行适当的分词处理,以便于模型理解。
💡启发点:通过位置编码扩展以及长文本对齐,ChatGLM能够处理长达1M上下文的文本。
对齐训练技术
对齐训练是为了让大模型输出与人类的偏好保持一致,包括理解人类意图、指令遵循和多轮对话。主要技术包括:
- SFT:采用真实的人类提示和交互,比基于模板或模型生成的响应更能提高对齐质量。
- RLHF:在SFT基础上进一步帮助缓解响应拒绝、安全、多语种混合以及多轮连贯性等问题。
警告区块:
⚠ 常见错误:过度依赖模板生成的响应可能会导致对齐质量下降,需注意使用真实数据进行训练。
ChatGLM技术创新
ChatGLM系列模型采用了一系列创新技术来提高性能和对齐效果:
- Emergent Abilities of LLMs:不同模型尺寸和训练token数的LLM在预训练损失相同的情况下,下游任务性能一致。某些任务如MMLU和GSM8K只有预训练损失降低到一定程度才可能有效果。
- LongAlign:通过长上下文对齐来改善大语言模型的长文本处理能力。
- ChatGLM-Math:使用自我评价而非外部模型或手动注释来选择数据。
- Self-Contrast:利用目标LLM自生成的大规模负样本进行RLHF对齐,减少昂贵的人工标注。
- AgentTuning:开发AgentTuning框架,构建高质量的agent与环境交互轨迹指令微调数据集。
行动清单:
- 研究ChatGLM在长文本处理上的应用潜力。
- 探索自我评价机制如何提高数学问题解决能力。
- 评估AgentTuning框架在不同环境中的适用性。
来源标注:
原文出处:ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools