GPT-1
GPT1: 生成性预训练的语言理解提升
元数据
- 分类:自然语言处理
- 标签:GPT1, 生成性预训练, 语言模型, Transformer
- 日期:2025年4月12日
内容摘要
GPT1模型通过生成性预训练来提升语言理解能力。其核心在于使用Transformer的decoder结构,结合自监督预训练和有监督微调,来提高模型的泛化性和加速训练收敛。
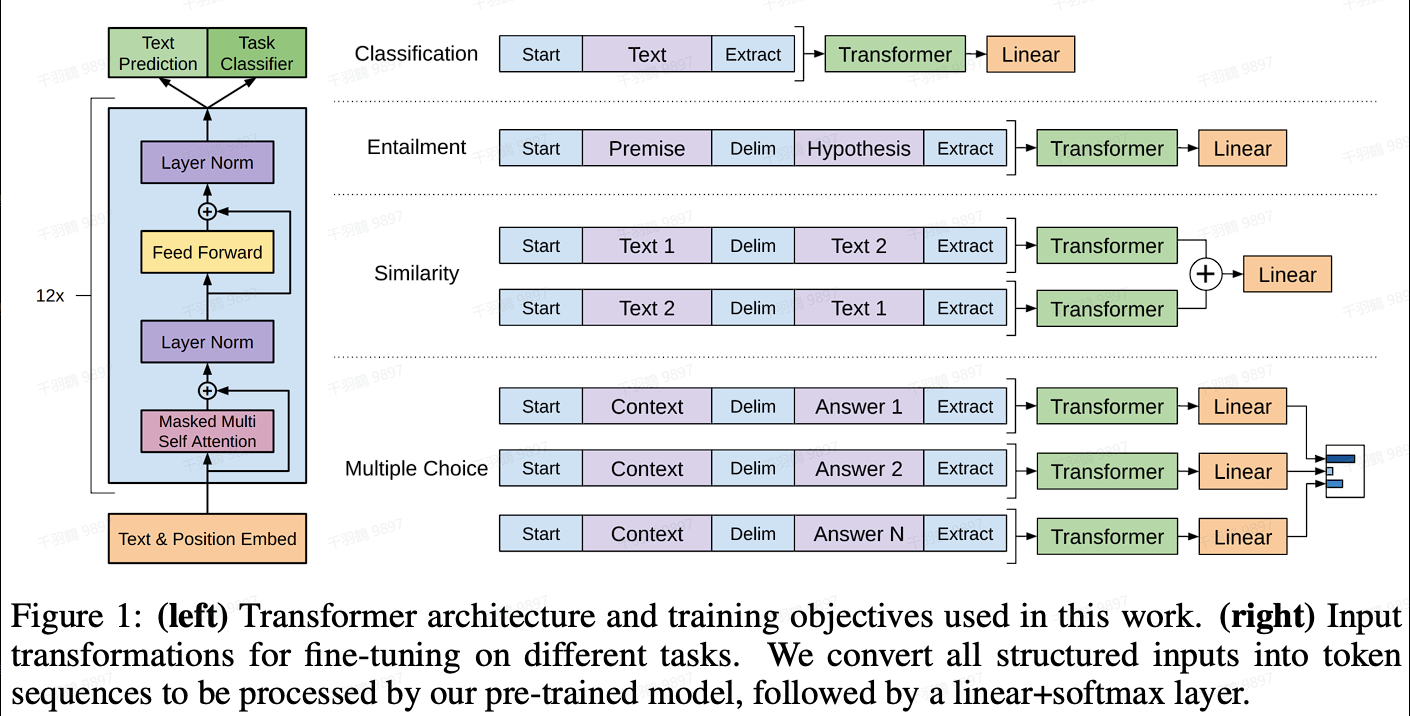
模型结构
GPT1采用的是Transformer的decoder-only结构,共12层。与传统的Transformer结构不同,GPT1在位置编码上进行了可训练的改进。原始的Transformer decoder包含两个attention机制:cross-attention和mask multi-head attention,而GPT1仅使用了mask multi-head attention。
训练范式
预训练
GPT1采用自监督的语言模型目标函数,通过根据前面K个词预测下一个词来进行预训练。公式为:
微调
微调阶段结合了完整输入序列的有监督目标函数和无监督目标函数。此方法不仅增加了模型的泛化能力,还加快了收敛速度。微调目标函数为:
并且结合无监督目标函数:
输入形式的改变
通过在序列前后添加特殊标识符如[Start]和[Extract]来表示开始和结束,并在序列之间添加[Delim]标识符来表示分隔。
操作步骤
- ✅ 模型结构选择:采用Transformer decoder-only结构。
- ⚠ 位置编码训练:将位置编码设置为可训练。
- ❗ 预训练与微调结合:采用自监督预训练结合有监督微调。
常见错误
⚠ 在微调过程中,忽视无监督目标函数可能导致模型泛化能力不足。
💡启发点
GPT1通过结合自监督和有监督学习,不仅提高了模型在各种任务上的表现,还加速了训练过程。
行动清单
- 探索GPT1在不同下游任务中的应用。
- 研究位置编码可训练性的影响。
- 比较GPT1与其他语言模型的性能差异。
原始出处:Improving Language Understanding by Generative Pre-Training