GPT-3
GPT-3: Sparse Attention and Few-Shot Learning
分类
自然语言处理
标签
GPT-3, Sparse Attention, Few-Shot Learning, AI模型, 机器学习
日期
2025年4月12日
内容概述
GPT-3采用了Sparse Attention技术,与GPT-2相比,显著提升了生成内容的真实性和处理更长输入序列的能力。GPT-3主推few-shot学习,并拥有更大的数据量和模型参数。其训练范式结合了预训练与in-context learning,与元学习相关联。
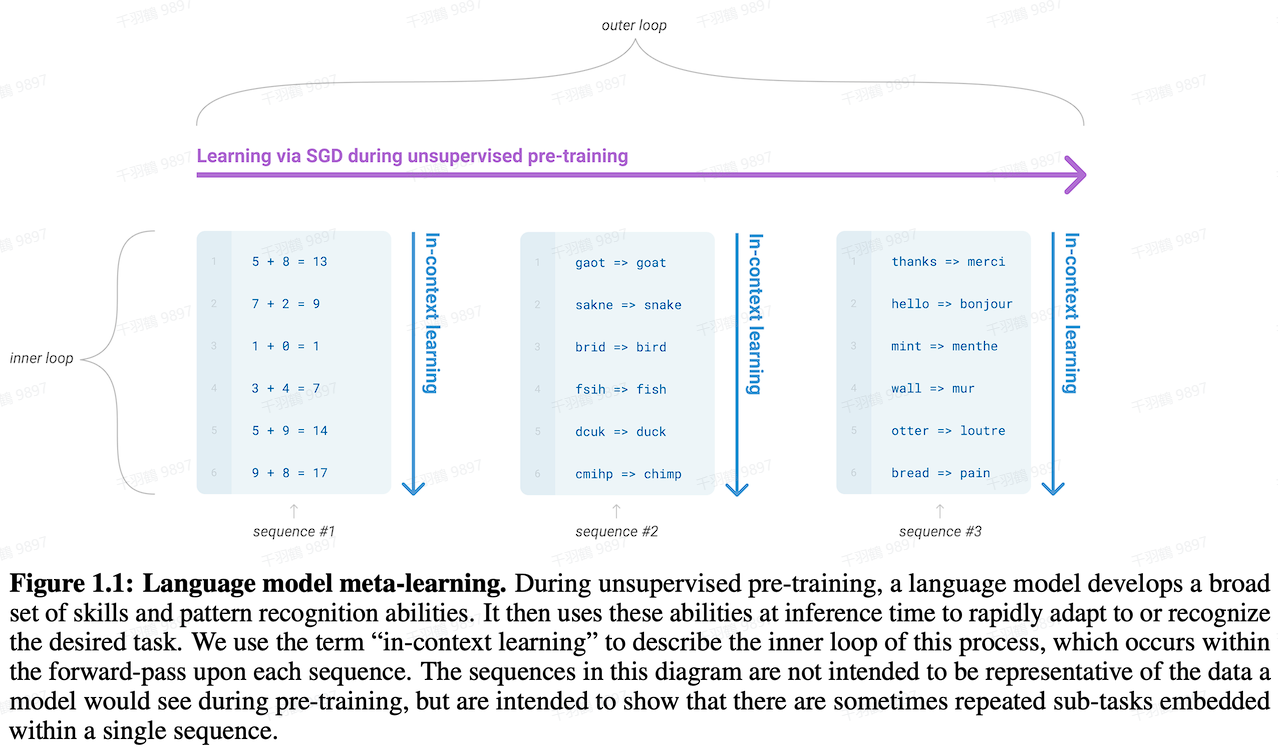
模型结构与技术创新
Sparse Attention
- Dense Attention:每个token之间两两计算attention,复杂度是
。 - Sparse Attention:每个token只与其他token的一个子集计算attention,复杂度降低为
。
💡启发点:使用Sparse Attention不仅节约了显存和耗时,还能处理更长的输入序列,并关注距离较近的上下文。
训练范式
- 结合预训练和few-shot/in-context learning。
- GPT-3主推few-shot学习,而GPT-2则主推zero-shot。
与GPT-2区别
- 模型结构:在GPT-2基础上,将attention改为了sparse attention。
- 效果:生成内容更为真实。
- 数据量:GPT-3的数据量远大于GPT-2,清洗后达到570G,而GPT-2仅有40G。
- 模型参数:GPT-3最大模型参数为1750亿,GPT-2最大为15亿。
常见错误
⚠ 注意在实现Sparse Attention时,确保正确选择token子集以避免信息丢失。
行动清单
- ✅ 研究Sparse Attention在其他模型中的应用可能性。
- ❗ 探索few-shot学习在不同领域的效果。
- ⚠ 评估GPT-3在实际应用中的性能表现。
数据表格
| 模型 | 数据量 | 参数数量 |
|---|---|---|
| GPT-3 | 570G | 1750亿 |
| GPT-2 | 40G | 15亿 |
来源标注
原始出处: Language Models are Few-Shot Learners
通过以上分析,GPT-3不仅在模型结构上进行了创新,还通过Sparse Attention技术提升了效率和性能,值得在自然语言处理领域进一步探索和应用。