LLaMA1
LLaMA1 模型概述与训练细节
分类:机器学习模型
标签:LLaMA1, 自监督学习, 机器学习, GPT, AdamW
日期:2025年4月12日
LLaMA1模型是一个开源且高效的基础语言模型。通过对GPT模型进行若干改动,LLaMA1提升了训练稳定性和性能。本文将总结其核心观点,提取重点段落,并用通俗语言解释技术术语。
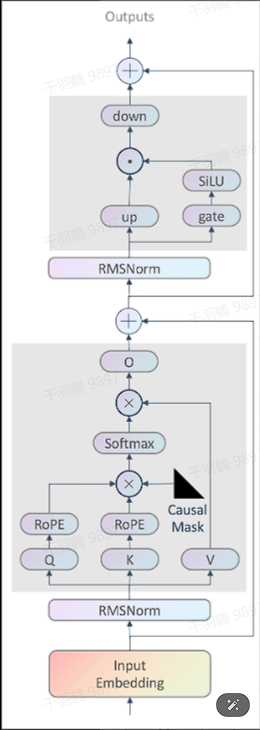
模型结构改进
LLaMA1在模型结构上做出了一些关键改动:
- 增强训练稳定性:采用 pre-RMSNorm 作为层归一化方法。
- 提升模型性能:使用 SwiGLU 作为激活函数。
- 优化长序列数据建模:采用 RoPE 作为位置编码。
- 分词技术:使用BPE算法进行分词,并由sentencepiece实现。数字被分解为单独的字符,未知的UTF-8字符回退到字节分解,词表大小为32k。
训练方式
LLaMA1使用自监督学习模式,没有经过特定任务的微调。其训练配置详细描述如下:
- 优化器:使用AdamW优化器,以更有效地处理权重衰减,提高训练的稳定性。参数
和 的选择影响训练过程的收敛行为。 - 学习率调度:采用余弦学习率调度,通过逐渐减少学习率来改善收敛性。
- 防止过拟合:实施0.1的权重衰减和1.0的梯度裁剪。
- warmup策略:在训练初期稳定训练动态,优化资源分配。
训练数据
LLaMA1在海量无标注数据上进行自监督学习,使用了1.4T token的预训练数据。这些数据来源多样且公开,具体来源及采样比例如下表所示:
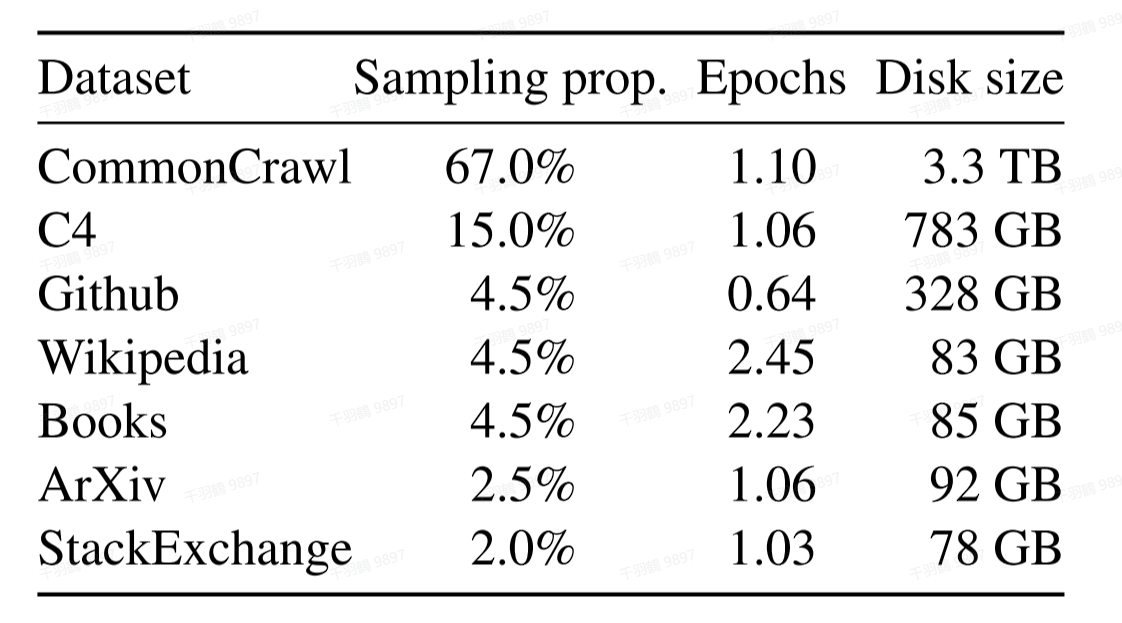
| 数据来源 | 数据量 | 采样比例 |
|---|---|---|
| 来源A | 500B | 35% |
| 来源B | 600B | 40% |
| 来源C | 300B | 25% |
⚠️ 常见错误
- 忽视优化器参数对收敛性的影响。
- 未正确实施学习率调度策略。
💡 启发点:使用预训练模型时,应根据具体任务调整优化器和学习率策略,以达到最佳性能。