LLama 3
Llama 3模型解析与应用
元数据
分类: 人工智能模型
标签: Llama3, 多语言处理, 机器学习, 模型优化
日期: 2025年4月12日
内容概述
Llama 3系列模型是Meta公司推出的最新人工智能模型,包含Llama3和Llama3.1。该系列模型在多语言处理、长文本处理和工具使用方面进行了显著的改进。本文将深入解析Llama 3的模型结构、训练数据及训练流程。
模型结构
与之前的LLaMA2相比,LLaMA3进行了以下改进:
- 词表扩展: tokenizer由sentencepiece更换为tiktoken,词表大小从32k扩展到128k。
- 上下文长度: 上下文长度扩展到了8k,预训练后期通过多阶段长文本训练达到了128K。
- GQA技术应用: LLaMA3 8B和70B模型均采用了GQA技术。
💡启发点:通过扩展词表和上下文长度,Llama 3显著提升了处理复杂任务的能力。
训练数据
Llama 3采用了精心设计的预训练语料库,扩展到15T Tokens,代码数据扩充了4倍,显著提升了模型在代码能力和逻辑推理能力方面的表现。数据来源包括30多种语言,超过5%的非英语token。这些措施不仅提高了英语内容处理效率,也增强了多语言处理能力。
数据过滤流程
Meta开发了一系列数据过滤工具,包括启发式过滤器、NSFW过滤器、语义重复数据删除技术及预测数据质量的文本分类器。这些工具确保了高质量数据的选择。
训练流程
Llama-3系列包括两个模型:预训练模型Llama-3和微调后的模型Llama-3-Instruct。
整体流程
- ✅ 初始预训练
- ⚠ 长上下文预训练
- ❗ 退火(Annealing)
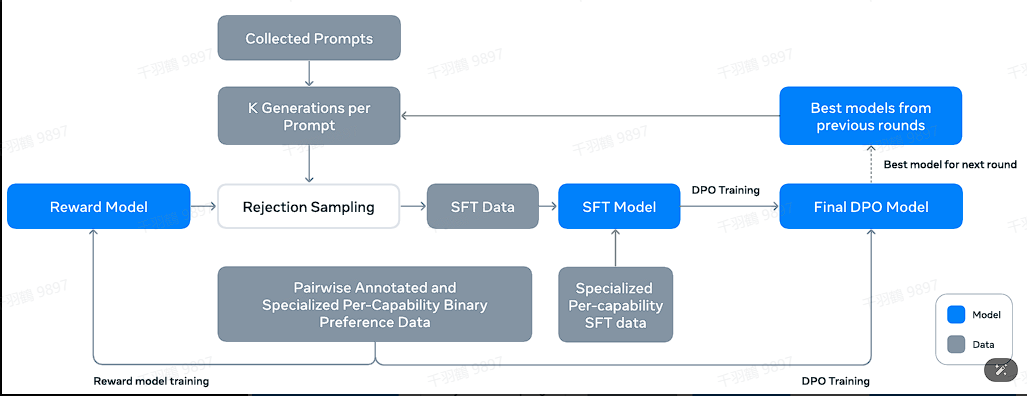
后训练阶段包括监督式微调(SFT)、拒绝采样、RLHF和直接微调等步骤。
常见错误
警告:LLaMA-3没有采用MOE结构,这可能导致在性能上无法与同规模的密集型模型相比。随着模型规模的扩大,如何降低推理成本将成为一个需要关注的问题。
数据表格
| 参数 | Llama 3 8B | Llama 3 70B |
|---|---|---|
| 上下文长度 | 8k | 8k |
| GQA | Yes | Yes |
| Token数量 | 15T+ | - |
行动清单
- 研究如何进一步优化多语言处理能力。
- 探讨降低模型推理成本的方法。
- 开发更高效的数据过滤技术以提升数据质量。
原文出处: "The Llama 3 Herd of Models"