Mistral
Mixtral of Experts: 高效推理的未来
元数据
- 分类:AI模型优化
- 标签:小模型、专家组、推理效率、Transformer、MoE
- 日期:2025年4月12日
核心观点总结
Mixtral of Experts模型通过将大型模型分解为多个“专家”,在推理过程中只选择最相关的两个专家进行计算,从而提高推理效率并降低成本。该模型的创新在于使用门控机制动态选择专家组合,适用于处理大规模数据集或复杂任务。
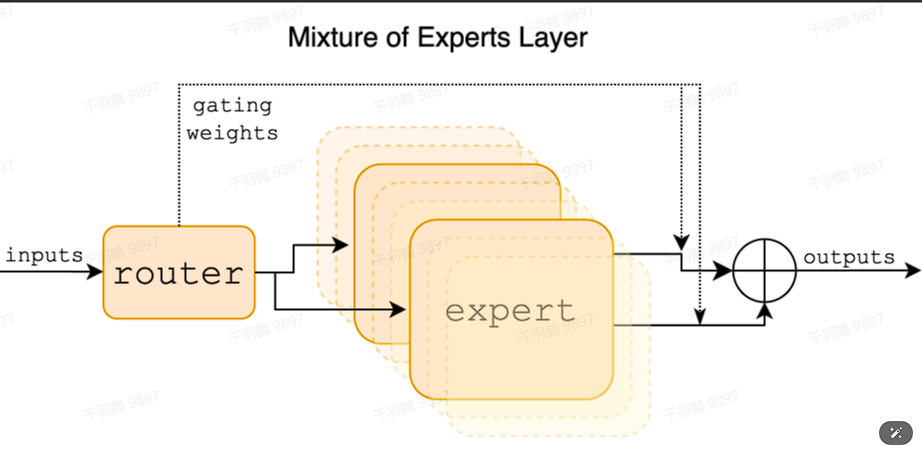
重点段落与数据
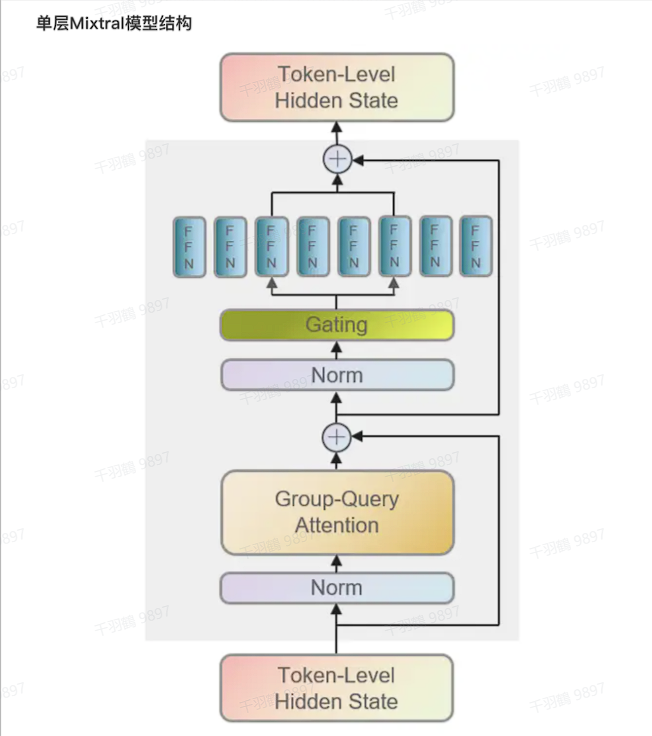
模型结构与工作原理
Mixtral模型由8个小模型组成,训练时使用所有8个模型,但推理时仅使用其中两个。这种设计使得总参数量为46.7B,但每个token只需使用12.9B参数,降低了计算成本。专家组中的每个成员专注于处理输入数据的特定方面,例如语法或语义。
MOE并行训练
分类
机器学习
标签
MoE, 并行训练, 分布式系统, GPU
日期
2025年4月12日
内容概述
本文探讨了在机器学习中使用Mixture of Experts (MoE)技术进行并行训练的方法,重点介绍了分布式初始化和FWD与BWD过程中的关键步骤。我们将复杂的技术术语转化为通俗易懂的语言,并提供关键流程的编号列表,以帮助读者更好地理解和应用这些技术。
分布式初始化
分布式初始化是将专家分布排列到多个GPU上的过程。我们先确定使用几块GPU来装载一套专家(EP),然后确认全局有多少套专家副本在运行(DP)。这种方法有助于优化资源使用并提高计算效率。
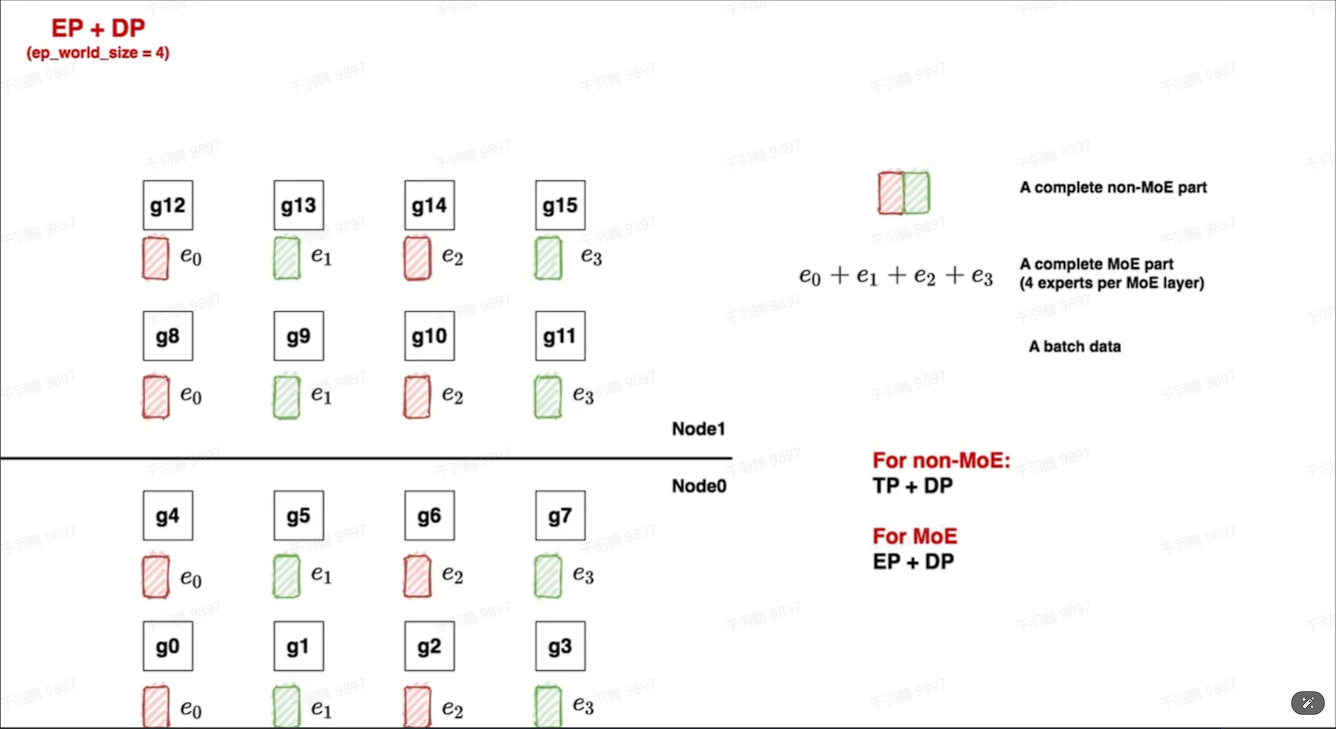
FWD与BWD过程
在FWD过程中,数据首先通过non-MoE层,然后进入MoE层。每个GPU上的数据维度是(E, C, M),通过ep_group内的all2all通讯将token发送到对应的专家。在BWD过程中,通过ep_dp_group中的allreduce来更新梯度结果。
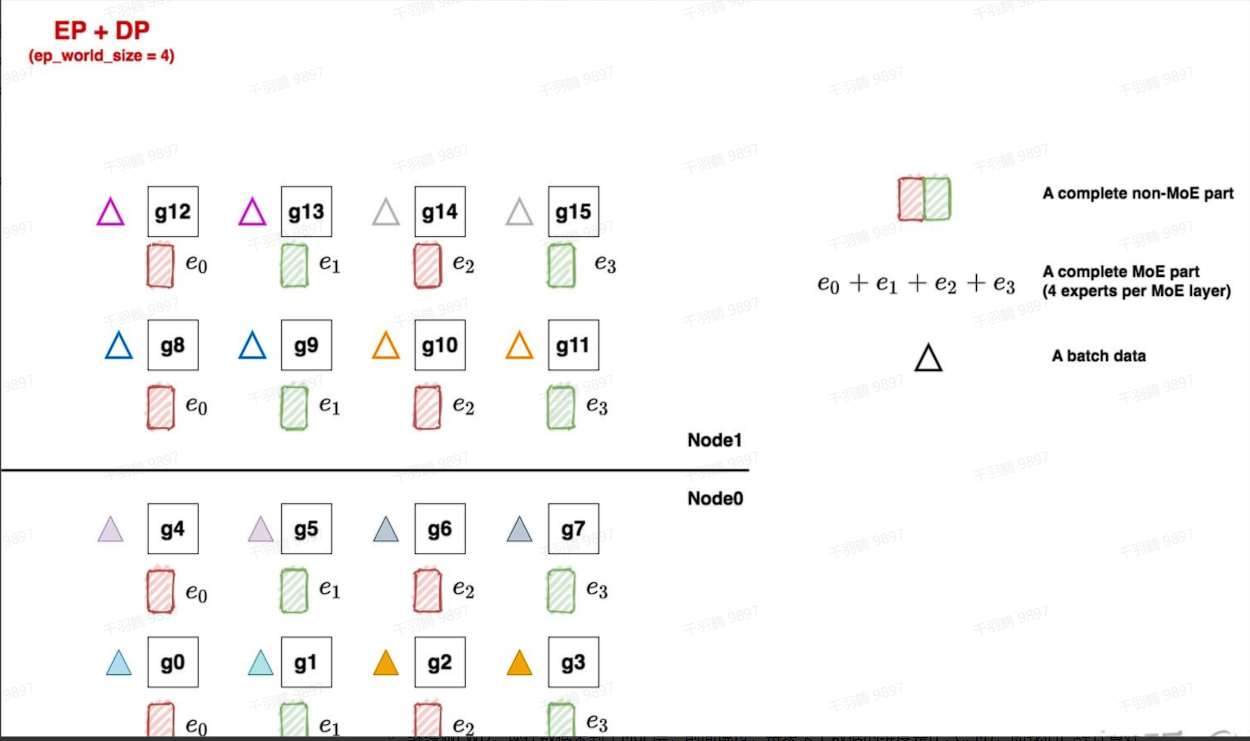
关键步骤
- ✅ 确定GPU数量用于装载专家(EP)。
- ⚠ 确认全局专家副本数量(DP)。
- ❗ 在FWD过程中使用all2all通讯发送token。
- ✅ 在BWD过程中使用allreduce更新梯度。
常见错误
注意在allreduce过程中确保所有GPU同步更新梯度,否则可能导致模型不一致性。
💡启发点
通过合理配置GPU和专家数量,可以显著提高模型训练速度和效率。
行动清单
- 研究MoE技术在不同应用场景中的表现。
- 探索其他分布式训练策略。
- 测试不同GPU配置对训练效率的影响。
原始出处:[粘贴您选取的文本]
路由与门控机制
关键组成部分是门控机制,它根据输入数据特性动态选择最优专家组合。前馈块从8组不同参数集中选择两个“专家”Transformer处理输入,并将它们的输出加权结合。
优化细节
- Sentence-Level:对各个样本分别进行路由。
- Token-Level:对样本中的各个token分别进行路由。
- Task-Level:要求不同的expert明确负责不同任务。
操作步骤
- ✅ 将输入token通过Attention层及残差连接传入模型。
- ⚠ 路由网络选择两个最优专家处理输入。
- ❗ 对专家输出进行加权聚合,并通过残差连接获取最终输出。
常见错误
注意在选择专家组合时,确保门控机制的准确性,否则可能影响模型性能。
代码示例
# 示例代码展示如何使用门控机制选择专家
def select_experts(token, experts):
weights = softmax(top_k(token * W_g, k=2))
selected_experts = [experts[i] for i in range(2)]
return sum(weight * expert(token) for weight, expert in zip(weights, selected_experts))
💡启发点
Mixtral模型通过仅使用部分专家进行推理,大幅降低了计算成本,同时保持了高效性能。这种设计为未来agent技术的发展提供了重要启示。
行动清单
- 研究其他MoE模型的优化策略。
- 评估Mixtral在不同任务场景下的性能表现。
- 探索门控机制的进一步改进方法。
数据转换
| 参数总量 | 使用参数量 | 专家数量 |
|---|---|---|
| 46.7B | 12.9B | 8 |
公式显示
对于输入token
MOE推理优化
元数据
- 分类:深度学习优化
- 标签:推理优化、滑动窗口、注意力机制、模型深度
- 日期:2025年4月12日
核心观点总结
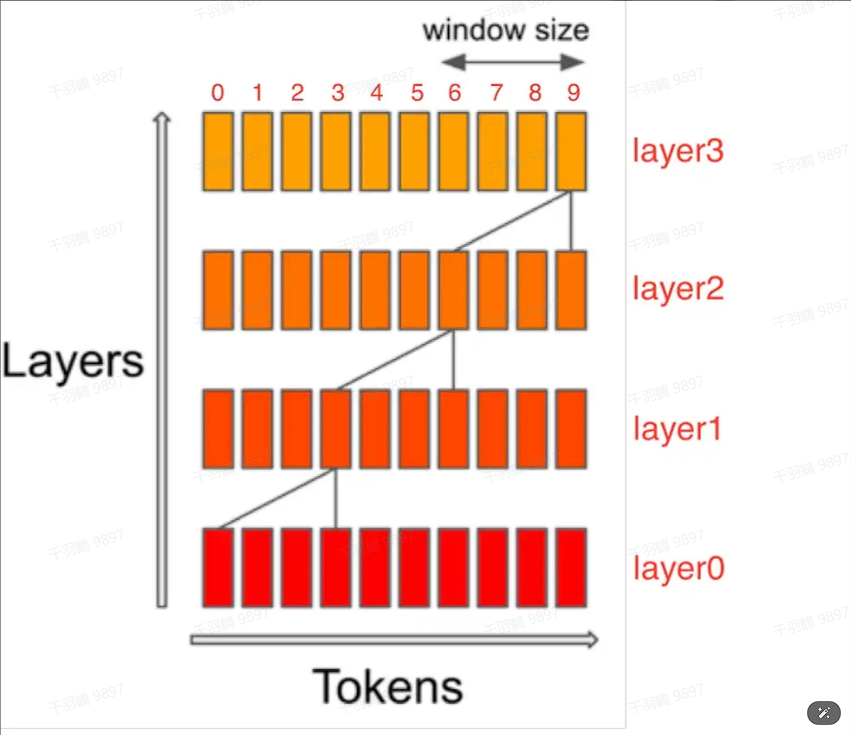
滑动窗口注意力机制通过限制每个token只与其前面固定数量的token进行注意力计算,从而减少缓存压力。虽然每层只能看到部分前置序列,但随着模型深度增加,最终可以覆盖所有前置tokens。这类似于CNN中的感受野概念。
重点段落
滑动窗口注意力机制
滑动窗口注意力机制旨在减少KV缓存的存储压力。传统的因果解码形式需要每个token与之前所有的token进行注意力计算,导致缓存与序列长度正相关。通过限制每个token仅与其前W个token做注意力计算,可以将缓存容量维持在W。
Rolling Buffer Cache
在Rolling Buffer Cache中,prompt中第i个token在KV缓存中的存储序号为

Chunking方法
Chunking方法通过将过长的prompt切成若干chunk,每次喂给模型一个chunk并更新KV缓存,解决显存压力问题。通常情况下,设定chunk_size等于cache_window等于sliding_window,所有尺寸保持一致,设为W。
步骤流程
- ✅限制每个token只与其前W个token进行注意力计算。
- ⚠使用Rolling Buffer Cache来管理KV缓存。
- ❗将长prompt切割成chunk以优化显存使用。
常见错误
在实现滑动窗口注意力机制时,容易错误地设置窗口大小W过小,导致信息无法充分流动。
💡启发点
滑动窗口注意力机制不仅优化了缓存,还通过模型深度实现了信息传递的完整性,这为大型模型的推理提供了一种高效解决方案。
行动清单
原始出处:[粘贴您选取的文本]