PLaM2
PaLM 2 技术报告分析与优化策略
元数据
- 分类:大语言模型
- 标签:PaLM 2, 预训练, 模型优化, 多语言能力, 谷歌
- 日期:2025年4月12日
内容概述
PaLM 2 是谷歌推出的一种新型大语言模型,采用了 UL2 的思想,通过混合不同的预训练目标来增强模型对语言的理解,特别是在多语言能力方面表现突出。本文将探讨 PaLM 2 的一些关键技术点和优化策略。

模型结构与预训练
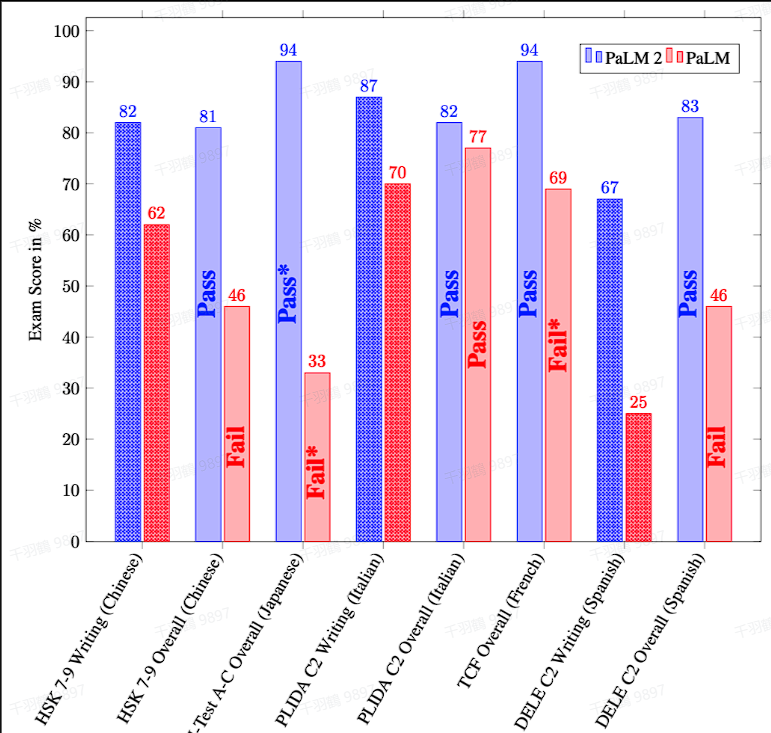
PaLM 2 的技术报告中并未详细说明模型结构,但指出其采用了 UL2 的思想。UL2 是谷歌尝试的一种与 GPT-3、PaLM 不同的大语言模型路径,使用不同的预训练目标的混合方法。这种方法能够训练模型理解语言的不同方面,尤其是在多语言能力上表现出色。
Scaling Law 与优化
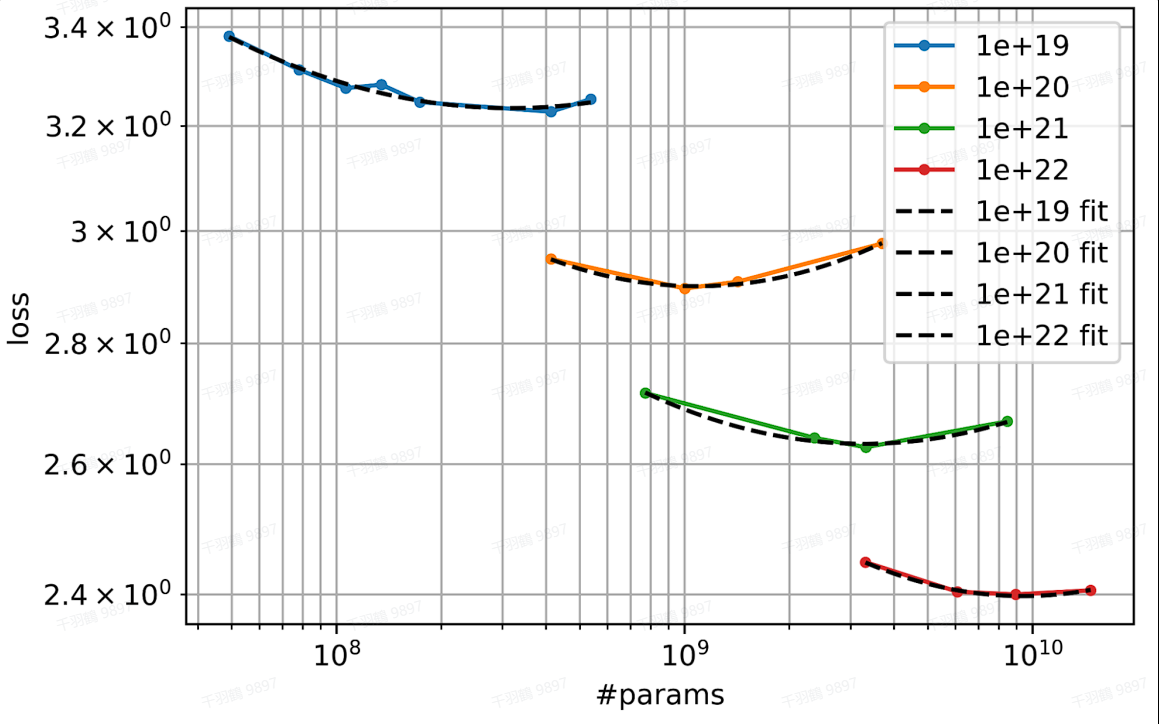
PaLM 2 在模型训练中应用了 Scaling Law,通过对不同规模的模型和参数样本进行训练,并通过损失函数(loss)评估最佳结果。研究结果显示,损失函数与参数规模呈现等比关系。
FLOPs 计算成本
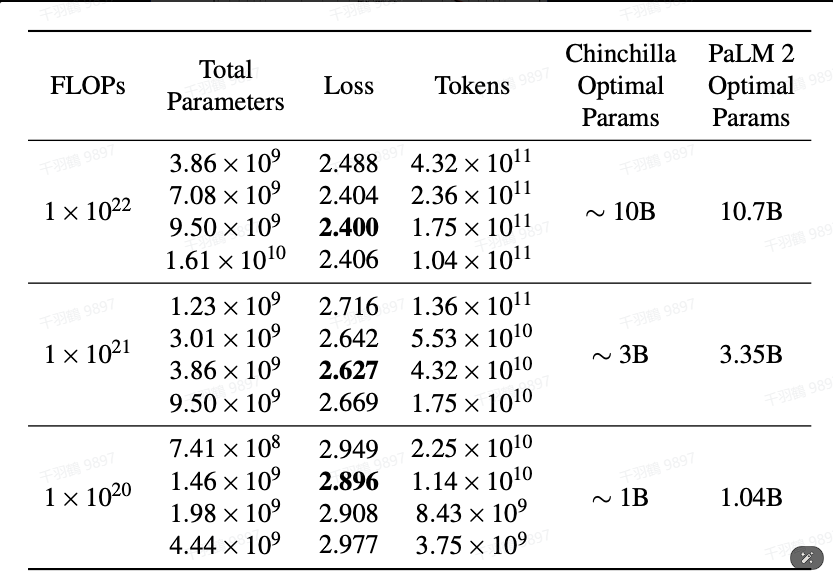
在计算 FLOPs 成本时,选择最佳参数数量和训练令牌数量对结果影响显著。在损失最小(2.400)时,参数与令牌的关系被进一步阐述,这为模型的炼丹炉和炼丹材料的最适大小提供了指导。
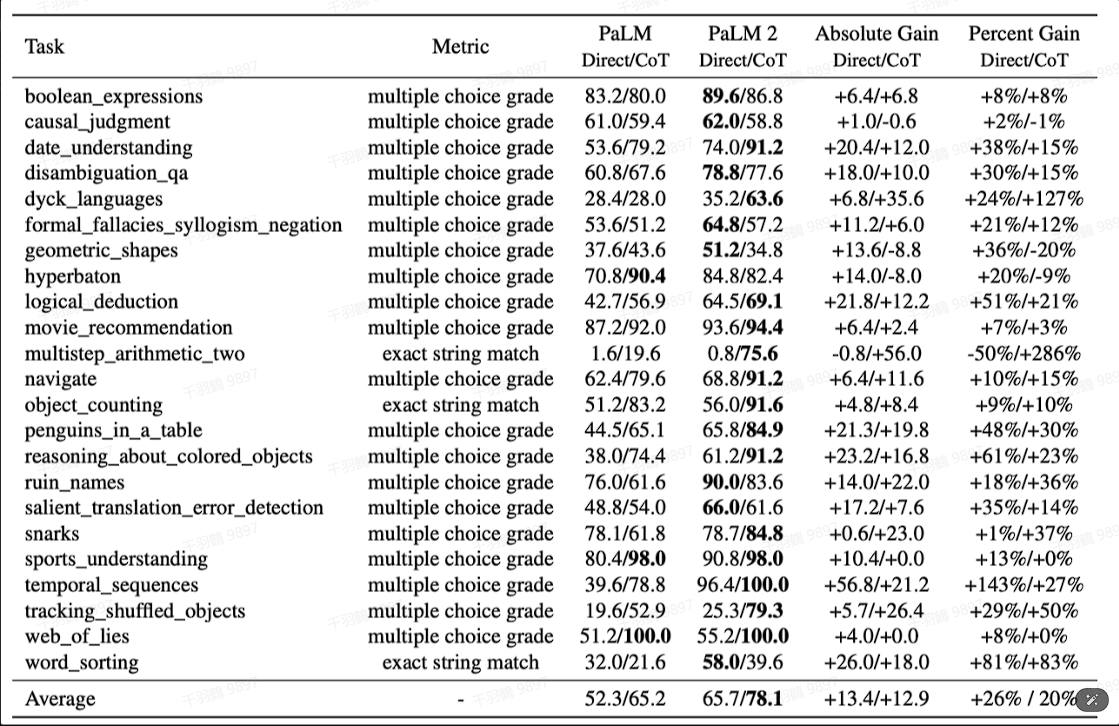
Reasoning 能力优化
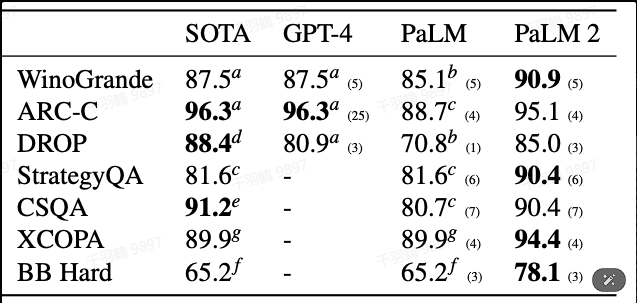
PaLM 2 针对 LLM 在数学和科学工程问题上的痛点进行了专门调整,以优化在这些领域的性能。
常见错误
⚠ 在选择参数规模时,可能会忽略损失函数与参数规模之间的等比关系,从而导致模型性能下降。
💡 启发点
- 将不同预训练目标混合以增强多语言能力。
- 使用 Scaling Law 优化模型训练效率。
数据表格
| 参数 | 令牌数量 | 损失 |
|---|---|---|
| x | y | 2.400 |
行动清单
- 进一步研究 UL2 模型方法对 PaLM 2 的影响。
- 探索更多关于 Scaling Law 的应用案例。
- 优化 PaLM 2 在特定领域(如数学、科学工程)的问题解决能力。
本文内容来源于 PaLM 2 技术报告分析。
参考DataLearner关于UL2的模型卡信息