Qwen1
Qwen模型技术报告:增强Transformer的性能与外推能力
元数据
- 分类:机器学习
- 标签:Transformer, Qwen模型, 自回归语言模型, 注意力机制
- 日期:2025年4月12日
核心观点总结
Qwen模型是一种基于Transformer改进的语言模型,采用了类似LLaMA的结构。通过一系列技术优化,Qwen在模型性能和外推能力上取得了显著提升。其关键特点包括未绑定的嵌入方式、RoPE位置编码和Flash Attention技术等。
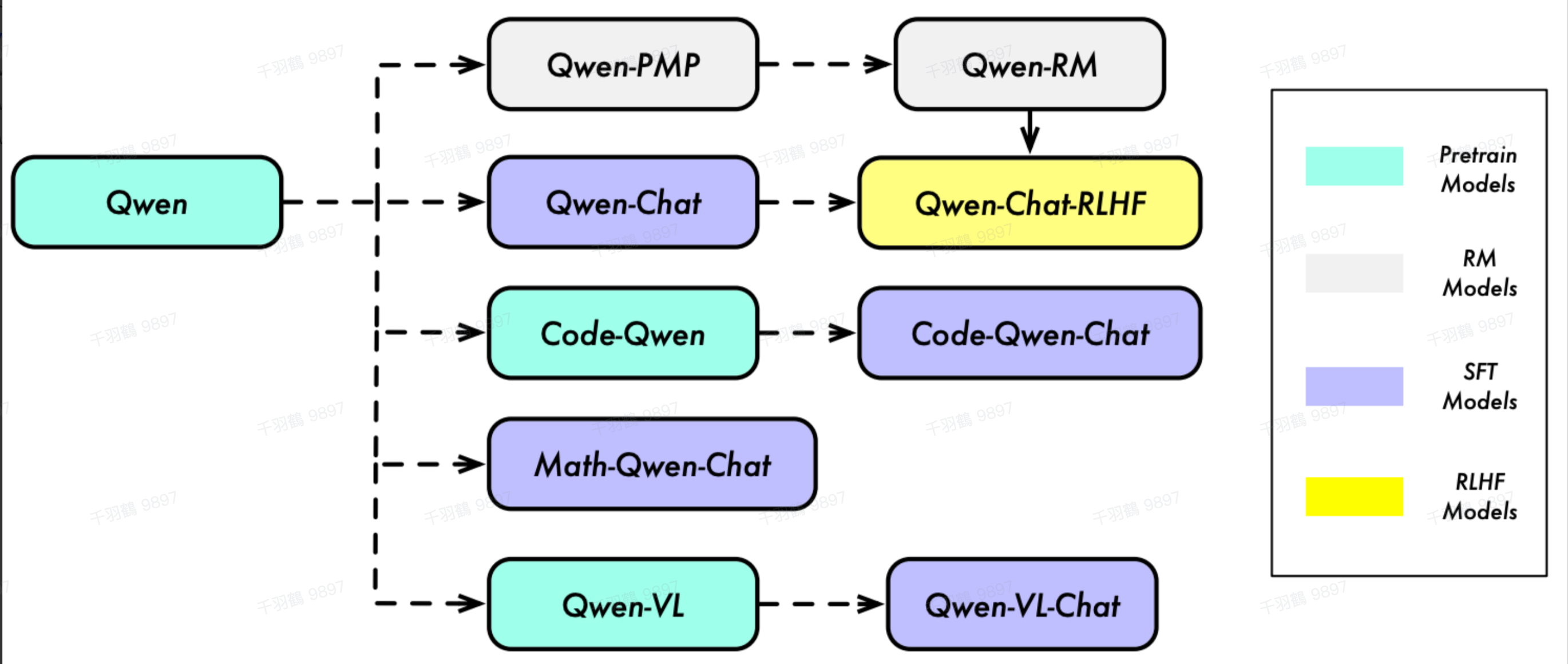
重点段落
模型结构与创新之处
Qwen模型在结构上进行了多项改进:
- 未绑定嵌入:输入和输出嵌入不共享权重,尽管增加了内存消耗,但显著提升了性能。
- RoPE位置编码和Pre-RMSNorm:增强了模型的表达能力。
- 偏置项的选择性保留:在大多数层移除偏置,但在注意力的QKV层保留,以提升外推能力。
模型训练方法
训练采用标准自回归语言模型目标:
- 上下文长度:训练时为2048,通过动态NTK插值和LogN-Scaling等技术,推理时可扩展至8192。
- 优化器与学习率:使用AdamW优化器,超参数设置为
、 和 ,并采用余弦学习率计划。
外推能力扩展技术
- 动态NTK插值:通过位置编码优化提升长度外推能力。
- LogN-Scaling:根据熵不变性对注意力值进行缩放,确保稳定性。
- 分层窗口Self-Attention:限制注意力范围,防止关注过远内容。
操作步骤
- ✅ 选择未绑定嵌入以提升性能。
- ⚠ 保留注意力QKV层偏置以增强外推能力。
- ❗ 使用Flash Attention技术提高计算效率。
常见错误
⚠ 在实现未绑定嵌入时,需注意内存消耗可能增加,应根据硬件条件合理配置。
💡 启发点
Qwen模型通过未绑定嵌入和多种注意力机制的创新组合,实现了在外推能力上的突破性进展。
行动清单
- 研究未绑定嵌入对不同任务性能的影响。
- 探索RoPE位置编码在其他模型中的应用潜力。
- 实验不同上下文长度对模型性能的影响。
数据转换
| 技术 | 描述 |
|---|---|
| 未绑定嵌入 | 输入和输出不共享权重 |
| RoPE位置编码 | 增强表达能力 |
| Flash Attention | 提高计算效率 |
公式显示
来源:QWEN TECHNICAL REPORT