发展历史
常见大型语言模型综述:BERT、GPT、Llama及其他
分类:人工智能
标签:大型语言模型, BERT, GPT, 深度学习
日期:2025年4月12日
核心观点总结
大型语言模型(LLM)的发展迅速,众多模型如BERT、GPT、Llama等在学术界和工业界中广泛应用。这些模型不仅推动了自然语言处理技术的进步,也成为面试中的常见考点。
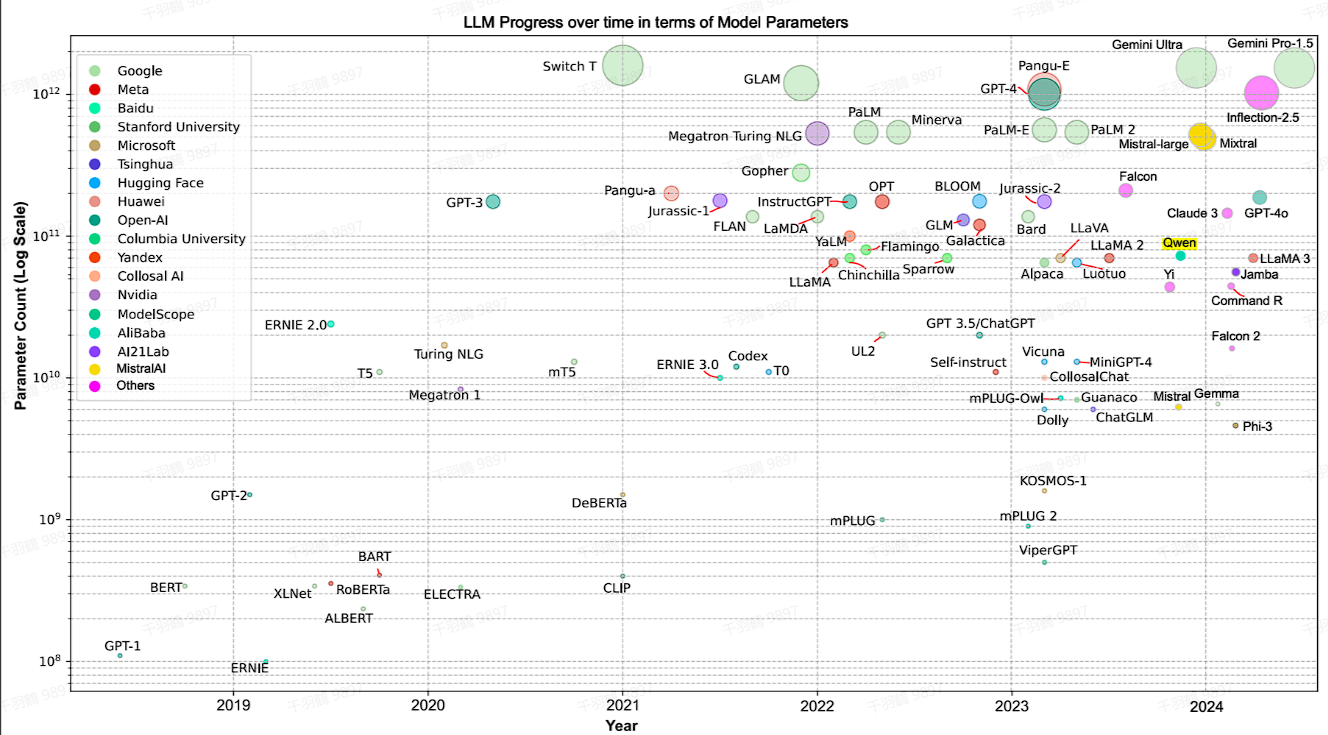
重点段落
-
BERT及其变体:
BERT(Bidirectional Encoder Representations from Transformers)是Google在2018年提出的预训练语言模型,通过双向编码器架构实现上下文信息的捕捉。其变体包括RoBERTa、DistilBERT等,进一步优化了训练效率和性能。 -
GPT系列:
GPT(Generative Pre-trained Transformer)由OpenAI开发,以生成式任务为主。GPT系列模型通过无监督学习进行预训练,并在特定任务中进行微调,展现了强大的文本生成能力。 -
Llama系列:
Llama系列是另一类重要的语言模型,以其高效的参数使用和出色的性能而闻名。它们在处理多任务和大规模数据集时表现出色。
操作步骤
- ✅ 选择适合的语言模型(如BERT、GPT)进行初步研究。
- ⚠ 分析模型的优缺点及适用场景。
- ❗ 在实际项目中应用并调整模型参数以优化性能。
行动清单
- 研究最新的LLM论文,保持技术前沿。
- 在项目中实施并测试不同的模型架构。
- 关注LLM在不同领域的应用案例,扩展知识面。
来源:本文内容基于“Survey of different Large Language Model Architectures: Trends, Benchmarks, and Challenges”论文。链接:arxiv.org/pdf/2412.03220