DPO介绍及RLHF-PPO缺点
直接偏好优化:语言模型的奖励模型潜力
元数据
- 分类:机器学习
- 标签:偏好优化、RLHF、PPO、强化学习
- 日期:2025年4月12日
内容概述
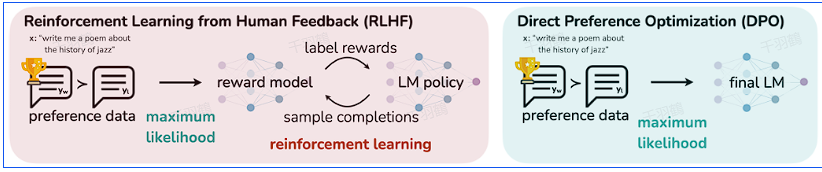
直接偏好优化(Direct Preference Optimization, DPO)是一种新的方法,旨在克服传统RLHF-PPO(通过人类反馈的强化学习-近端策略优化)中的一些缺点。本文讨论了DPO的潜在优势,并指出了现有方法中存在的挑战。
核心观点
RLHF-PPO存在的两个主要缺点:
- 信息损失:RLHF过程分为两个阶段,首先使用偏好数据训练奖励函数模型,然后利用PPO或其他算法训练策略。如果奖励函数模型与人类偏好对齐不佳,后续策略可能会次优。
- 资源需求:PPO算法需要大量计算资源,因为它引入了四个模型(Actor、Critic、Reward、Reference),这些模型都基于大型语言模型(LLM)初始化或改进。
技术术语通俗解释
- RLHF:通过人类反馈的强化学习,是一种利用人类偏好数据训练机器学习模型的方法。
- PPO:近端策略优化,是一种强化学习算法,专注于策略的稳定性和收敛性。
- LLM:大型语言模型,通常用于自然语言处理任务。
操作步骤
- ✅ 训练奖励函数模型:使用偏好数据训练奖励函数。
- ⚠ 使用PPO优化策略:确保奖励模型与人类偏好对齐,否则策略可能次优。
- ❗ 管理计算资源:注意PPO引入的四个模型对计算资源的需求。
常见错误
警告:在训练奖励函数模型时,如果偏好数据不准确或不全面,可能导致后续策略优化失败。
💡启发点
直接偏好优化可能减少信息损失和资源需求,为语言模型提供更好的奖励对齐方式。
行动清单
- 研究DPO在不同任务中的应用效果。
- 探索减少PPO计算资源需求的方法。
- 开发更有效的奖励函数模型对齐技术。
原始出处:Direct Preference Optimization: Your Language Model is Secretly a Reward Model