LoRA
LoRA: 高效微调大模型的低秩适应方法
分类:机器学习
标签:LoRA, 微调, 低秩矩阵, 大语言模型
日期:2025年4月12日
文章概述
LoRA(Low-rank Adaption)是一种高效的微调大模型方法,通过使用低秩矩阵来编码参数增量,实现了在减少资源消耗的情况下对大模型的有效微调。LoRA的核心思想是利用预训练模型的内在低维度特性,通过低秩分解来更新参数矩阵,从而降低显存使用和训练耗时。
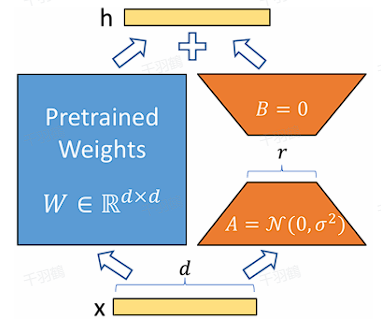
核心观点
-
高效微调原理:LoRA通过加载预训练参数进行初始化,并在训练过程中仅微调一部分参数,减少了资源消耗。
-
低秩矩阵编码:在训练过程中,LoRA使用低秩矩阵来表示参数增量,这些矩阵仅放大对下游任务有用的特征。
-
内在维度与低秩:大语言模型拥有极小的内在维度,LoRA通过低秩分解来更新参数,充分利用了这一特性。
重点段落
1. LoRA的实现
LoRA通过使用低秩矩阵来编码参数增量
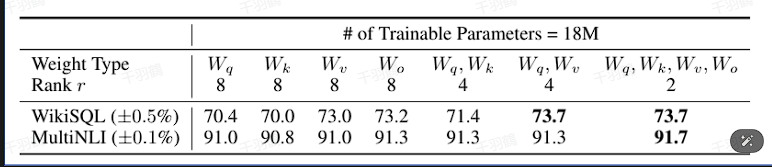
2. 参数更新与内在秩
LoRA认为在参数更新过程中存在一个内在秩,对于预训练权重矩阵可以用一个低秩分解来表示参数更新:
其中,
3. 矩阵初始化策略
下采样矩阵
操作步骤
- ✅ 初始化预训练参数:加载并初始化预训练模型参数。
- ⚠ 设置低秩矩阵:定义并初始化低秩矩阵
和 。 - ❗ 冻结主参数:在训练过程中冻结主参数
,仅训练 和 。 - ✅ 并行推理:在前向过程同时计算
和 ,提高推理效率。
常见错误
在微调过程中,将所有可微调参数集中到attention的某一个参数矩阵可能导致效果不佳。建议将可微调参数平均分配到
和 。
💡 启发点
LoRA展示了如何通过低秩分解和内在维度的利用,减少大模型微调所需的资源消耗,同时保持良好的性能。
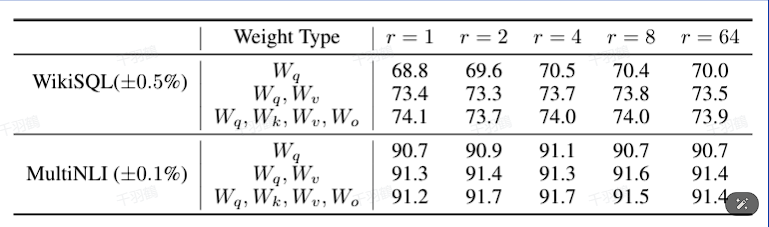
行动清单
- 探索不同任务下LoRA的适用性和性能表现。
- 实验不同的矩阵初始化策略对微调效果的影响。
- 研究LoRA与其他微调方法(如Adapter)的组合使用效果。
原始出处:[原文链接或出处信息]
LoRA 微调的初始化影响与核心代码分析
元数据:
- 分类:机器学习
- 标签:LoRA微调、初始化、特征学习、代码分析
- 日期:2025年4月12日
核心观点总结
在LoRA微调过程中,初始化策略对模型的训练动态有显著影响。通过实验对比,发现不同的初始化策略会影响特征学习效率和训练稳定性。本文将深入分析LoRA微调中的初始化影响,并探讨其核心代码实现。
重点分析
初始化策略对比
- Init[A]:具有更高的特征学习效率,但可能导致训练不稳定。通常情况下,表现优于Init[B]。
- Init[B]:提供稳定的训练过程,但特征学习效果稍逊。
💡启发点:选择何种初始化策略需权衡特征学习效率与训练稳定性。
LoRA 微调核心代码
LoRA的核心在于LoraModel类,该类通过拷贝原始的nn.Linear的属性,创建了一个新的Linear类。
class Linear(nn.Linear, LoraLayer):
def __init__(
self,
adapter_name: str,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.0,
fan_in_fan_out: bool = False,
is_target_conv_1d_layer: bool = False,
**kwargs,
):
init_lora_weights = kwargs.pop("init_lora_weights", True)
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoraLayer.__init__(self, in_features=in_features, out_features=out_features)
self.weight.requires_grad = False
nn.Linear.reset_parameters(self)
self.update_layer(adapter_name, r, lora_alpha, lora_dropout, init_lora_weights)
LoRA 设置降维和升维矩阵
在LoraLayer类中,使用update_layer函数设置降维矩阵
self.lora_A[adapter_name] = nn.Linear(self.in_features, r, bias=False)
self.lora_B[adapter_name] = nn.Linear(r, self.out_features, bias=lora_bias)
常见错误
⚠️ 在实现LoRA微调时,需注意初始化策略的选择,以避免不必要的训练不稳定性。
行动清单
来源:本文内容基于实验文献《The Impact of Initialization on LoRA Finetuning Dynamics》和相关代码分析。