QLoRA
QLoRA微调方法:降低内存需求与保持性能的创新
元数据
- 分类:机器学习技术
- 标签:QLoRA, LoRA, 微调, 内存优化, 人工智能
- 日期:2025年4月12日
内容摘要
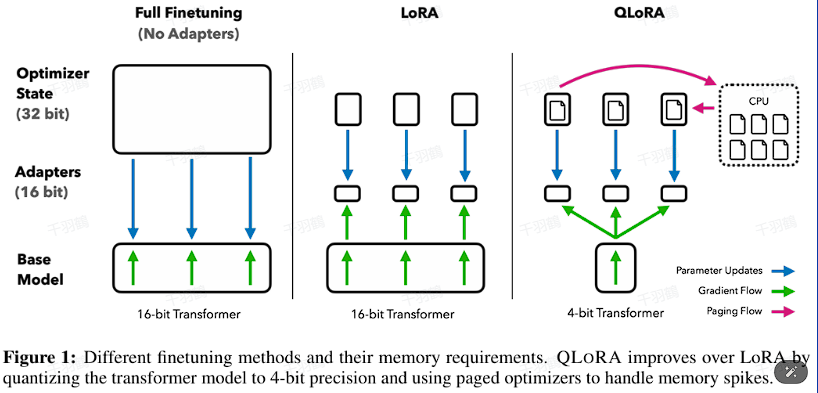
QLoRA是一种基于LoRA的微调方法,通过引入4-bit NormalFloat、双重量化和Paged Optimizers等技术,显著降低了模型的内存使用,同时保持了高性能。这种创新方法使得在单GPU上微调最大的公开可用模型成为可能。
核心观点
QLoRA通过在每个网络层添加适配器,避免了以前微调方法中几乎所有的准确性折衷。这种方法将拥有65B参数的模型内存需求从>780GB降低到<48GB。
技术术语通俗解释
- LoRA:一种用于减少模型参数的技术,通过在深度学习模型中添加适配器来优化内存使用。
- 4-bit NormalFloat:一种数据表示方式,使用较少的比特来存储浮点数,从而节省内存。
- 双重量化:一种技术,通过对数据进行两次量化来进一步减少存储需求。
操作步骤
- ✅ 在每个网络层添加适配器以优化内存使用。
- ⚠ 引入4-bit NormalFloat以减少浮点数存储空间。
- ❗ 使用双重量化技术以进一步降低内存需求。
常见错误
⚠ 在实施QLoRA时,确保适配器正确集成到每个网络层,否则可能导致模型性能下降。
💡启发点
QLoRA的创新在于其能够在不牺牲性能的情况下显著降低内存需求,使得大型模型的微调在单GPU上成为可能。
行动清单
- 研究QLoRA在其他类型模型中的应用潜力。
- 探索更多关于4-bit NormalFloat和双重量化的技术细节。
- 实验QLoRA与其他微调方法的性能比较。
数据转换
| 参数模型 | 原始内存需求 | 优化后内存需求 |
|---|---|---|
| 65B | >780GB | <48GB |
来源:原始内容来自用户提供的文本。