VeRA
VeRA:优化LoRA参数的创新方法
元数据:
- 分类:机器学习
- 标签:VeRA, LoRA, 参数优化, 随机矩阵
- 日期:2025年4月12日
核心观点
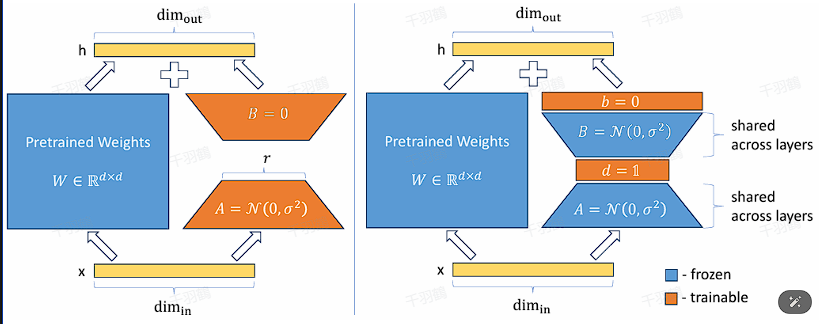
VeRA(Vector-based Random Matrix Adaptation)是一种创新方法,旨在通过引入共享的随机权值矩阵,显著减少LoRA(Low-Rank Adaptation)参数的大小。与传统方法不同,VeRA不直接训练矩阵A和B,而是用共享的随机权值初始化这些矩阵,并仅在微调时训练两个向量d和b。
重点段落
1. VeRA的创新机制
VeRA通过将所有层中的矩阵A和B初始化为相同的随机权值,从而减少了参数大小。这种共享权值的方法不仅降低了计算复杂度,还提高了模型的效率。
2. 微调过程
在微调过程中,VeRA只需训练两个新的向量d和b。这种简化的训练过程使得模型在保持性能的同时,大幅减少了计算资源的消耗。
3. 技术术语解释
- 随机矩阵:一种用随机数填充的矩阵,用于初始化模型参数。
- 微调:在已有模型上进行小幅度的训练,以适应新的数据或任务。
- 共享权值:指在不同层中使用相同的参数值,以减少模型复杂性。
操作步骤
- ✅ 初始化所有矩阵A和B为相同的随机权值。
- ⚠ 在微调阶段,仅训练向量d和b。
- ❗ 确保共享权值的一致性,以避免层间不匹配。
常见错误
警告:在初始化随机矩阵时,确保所有层使用相同的权值。如果不一致,可能导致模型性能下降。
💡启发点
VeRA通过共享权值和简化微调过程,为参数优化提供了新的思路,特别适合资源受限的环境。
行动清单
- 研究VeRA在不同模型架构中的应用效果。
- 测试VeRA在实际任务中的性能表现。
- 探索其他可能的参数共享策略。
原文出处: 引用自提供的文本内容。