X-LoRA
X-Lora:动态缩放的多领域预训练模型集成
元数据
- 分类:机器学习
- 标签:X-Lora, 预训练模型, 动态缩放, 低秩适应
- 日期:2025年4月12日
核心观点
X-Lora通过结合多个不同领域的预训练的Lora模型,并通过一个可训练的缩放头来动态调整每个Lora模型的贡献。这种方法允许在不同任务中灵活应用多个低秩适应技术,以提高模型的效率和性能。
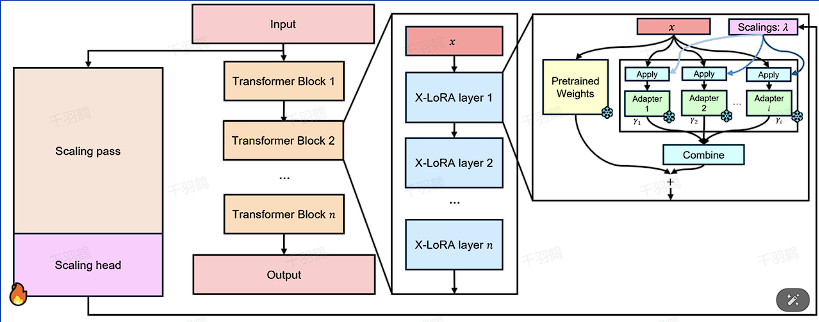
重点内容
动态缩放机制
X-Lora使用一个动态缩放机制来调整每个Lora模型在最终输出中的贡献。这个过程包括:
- 获取缩放值:从给定的缩放矩阵中提取特定层的缩放值。
- 选择Top-K缩放:根据配置,选择贡献最大的Top-K个缩放值。
- 应用Softmax:如果启用,使用Softmax函数对非零缩放值进行归一化处理。
XLoraLinearLayer的前向传播
在XLoraLinearLayer类中,前向传播过程如下:
- 检查目标是否已合并。
- 遍历每个活跃的适配器,获取相应的Lora权重和缩放参数。
- 根据需要应用缩放调整。
- 计算结果并返回。
代码示例
def get_maybe_topk_scalings(self, scalings) -> torch.Tensor:
xlora_scalings = scalings[:, :, self.layer_number, :]
if self.config.top_k_lora is not None:
_, topk_indices = torch.topk(xlora_scalings, k=self.config.top_k_lora, dim=-1)
mask = torch.zeros_like(xlora_scalings, dtype=torch.bool)
mask.scatter_(-1, topk_indices, True)
xlora_scalings = xlora_scalings * mask.to(xlora_scalings.dtype)
if self.config.enable_softmax_topk:
nonzero_mask = xlora_scalings != 0
softmax_res_nonzero = torch.softmax(xlora_scalings[nonzero_mask], dim=-1)
xlora_scalings[nonzero_mask] = softmax_res_nonzero
return xlora_scalings
💡 启发点
这种方法不仅提高了模型在特定任务上的适应能力,还可以在不显著增加计算成本的情况下,利用多个领域的知识。
警告区块
⚠️ 常见错误:确保在应用缩放时,非零掩码和Softmax函数正确配置,否则可能导致缩放不准确。
行动清单
- 探索更多的低秩适应技术与X-Lora结合的可能性。
- 评估X-Lora在不同领域任务中的性能表现。
- 优化动态缩放头的训练策略以提高模型效率。