P-Tuning
P-Tuning: 提升GPT在NLU任务中的表现
元数据
- 分类:自然语言处理
- 标签:P-Tuning, GPT, NLU, Embedding, Prompt
- 日期:2025年4月12日
内容概述
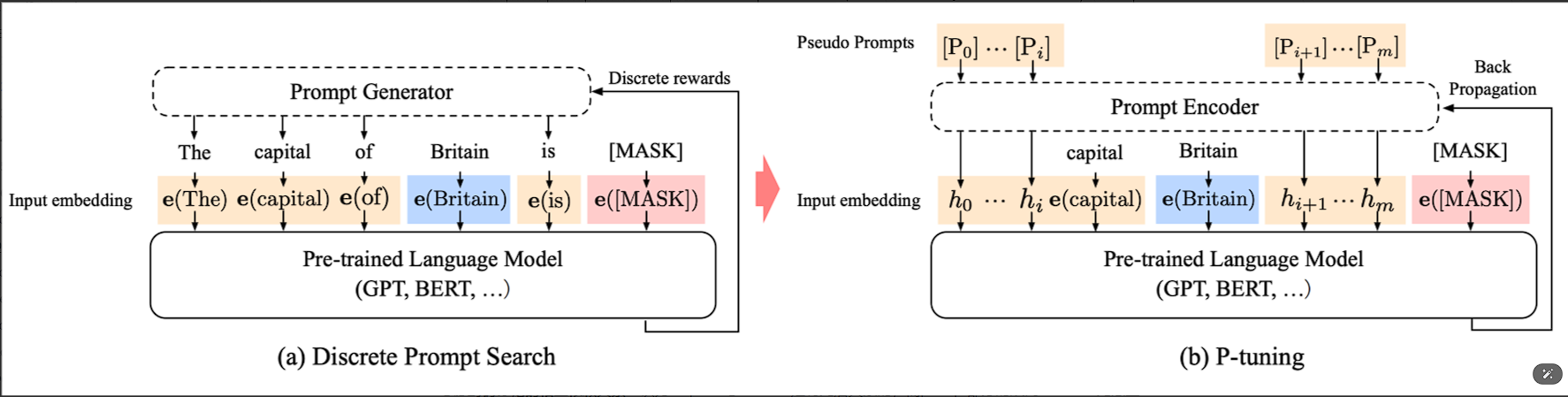
P-Tuning是一种通过优化embedding层来增强GPT在自然语言理解任务中的方法。该方法通过将prompt转换为可学习的embedding层,并利用MLP和LSTM对其进行处理,从而使GPT更好地应用于NLU任务。
主要观点
-
Prompt Encoder的引入:为了处理伪标记的相互依赖关系,P-Tuning采用了一层RNN作为Prompt Encoder,以编码prompt embedding序列。
-
上下文词的指定:在训练过程中,选择具有代表性语义的词作为伪标记的初始化,以确保模板在语义上与句子保持一致。
-
重参数化:在训练时使用Prompt Encoder来表征伪标记,并在推理阶段不再使用。
-
混合提示:结合连续提示与离散token,以提高模型的灵活性和适应性。
操作步骤
- ✅ 将Prompt转换为可学习的embedding层。
- ⚠ 使用MLP+LSTM对Prompt Embedding进行处理。
- ❗ 在训练过程中更新embedding层中virtual token的部分参数。
常见错误
- 随机初始化virtual token可能导致优化到局部最优值,应使用Prompt Encoder进行编码以加速收敛。
💡启发点
- P-Tuning通过优化embedding层而非整个模型,减少了需微调的参数量级,提高了训练效率。
行动清单
- 探索更多关于Prompt Encoder在不同任务中的应用。
- 实验不同的上下文词选择策略对模型性能的影响。
- 研究混合提示对其他语言模型的适用性。
数据转换
| 项目 | 描述 |
|---|---|
| Prompt Encoder | 使用RNN编码伪标记 |
| 上下文词选择 | 选择具有代表性语义的词进行初始化 |
| 重参数化 | 训练时使用,推理阶段不使用 |

公式显示
来源:原始文本内容来自于技术文档,详细探讨了P-Tuning的实现及其对GPT性能提升的作用。