Prefix-Tuning
Prefix Tuning与Prompt Tuning的比较与应用
元数据
- 分类:人工智能技术
- 标签:Prefix Tuning、Prompt Tuning、Transformer、机器学习
- 日期:2025年4月12日
核心观点总结
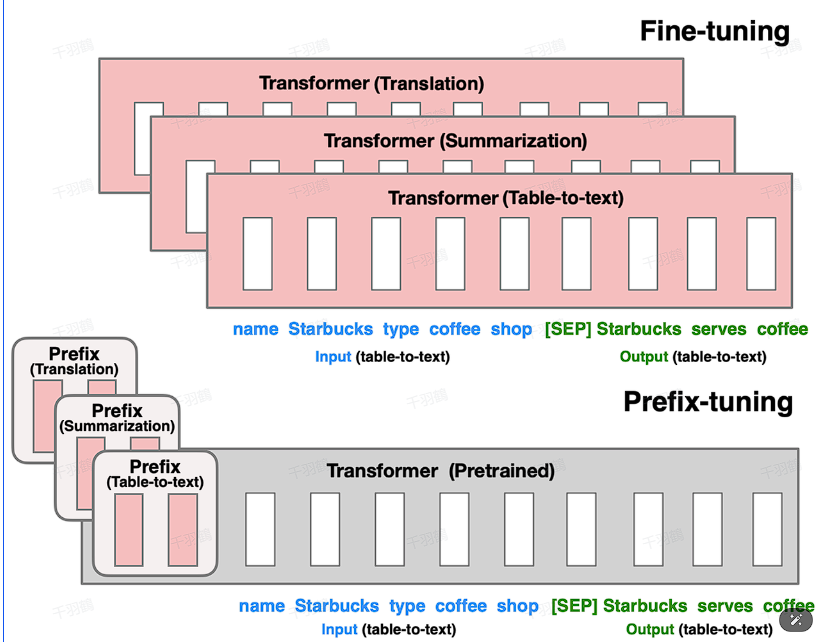
Prefix Tuning是一种通过在输入token前构造任务相关的连续virtual tokens作为Prefix的方法。它在训练过程中只更新Prefix部分的参数,而保持LLM其他部分参数不变。此方法对于不同模型结构需要构造不同的Prefix,并在每层都加上prompt的参数以提高性能。
重点段落
Prefix Tuning的实现
Prefix Tuning通过在输入token前构造任务相关的连续virtual tokens作为Prefix。这些virtual tokens不对应于真实tokens,而是自由参数。在训练过程中,仅更新这些Prefix的参数,保持LLM其他部分参数固定。
应用于不同模型结构
- 自回归架构模型: 在句子前面添加前缀,形成 z = [PREFIX; x; y]。合适的上文能够在固定LM的情况下引导生成下文。
- 编码器-解码器架构模型: Encoder和Decoder都增加了前缀,形成 z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder端增加前缀是为了引导后续token的生成。

防止训练不稳定
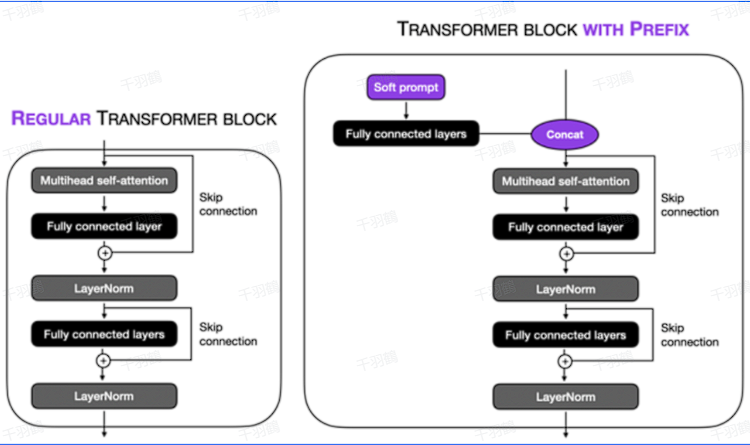
为了防止直接更新Prefix参数导致训练不稳定和性能下降,在Prefix层前面加了MLP结构。在训练完成后,仅保留Prefix的参数。此方法通过消融实验验证,仅调整embedding层表现力不够,会导致性能显著下降,因此在每层都加了prompt的参数。
技术术语通俗解释
- Prefix: 在输入数据前添加的一段可调整的虚拟数据,用于优化模型性能。
- MLP结构: 多层感知器结构,用于处理复杂数据关系。
- 消融实验: 一种实验方法,通过去除某个组件来评估其对系统整体性能的影响。
操作步骤
- ✅ 构造任务相关的连续virtual tokens作为Prefix。
- ⚠ 在训练过程中仅更新Prefix部分参数。
- ❗ 在每层都加上prompt的参数以提高性能。
常见错误
注意:直接更新Prefix参数可能导致训练不稳定和性能下降,应在Prefix层前面加MLP结构。
💡启发点
通过消融实验验证,仅调整embedding层表现力不够,会导致性能显著下降,因此在每层都加了prompt的参数。
行动清单
- 研究不同模型结构下Prefix Tuning的具体实现。
- 进行消融实验以评估各组件对系统性能的影响。
- 探索其他可能的优化策略以提高模型性能。
原始出处:[原文内容]
注意:所有公式或公式字母(如