Self-Reward
自我奖励语言模型:提升指令遵循与奖励评估能力
分类:机器学习
标签:语言模型、指令遵循、奖励评估、自我训练
日期:2025年4月12日
核心观点总结
自我奖励语言模型(Self-Rewarding Language Model)是一种通过自我训练过程提升语言模型指令遵循能力和奖励评估能力的方法。该方法利用预训练语言模型及少量标注数据,通过迭代训练不断优化模型输出,避免传统模型中固定奖励机制的局限性。实验结果表明,自我奖励训练有效提高了模型的性能。
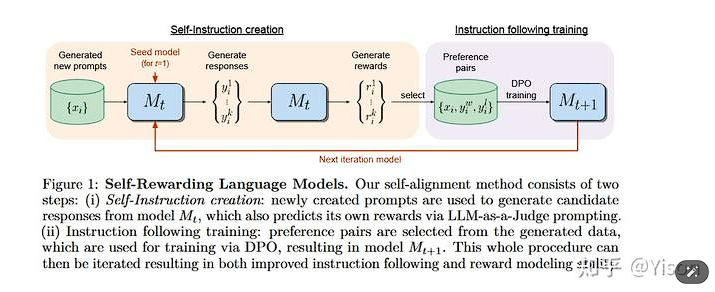
实现方法
初始化与种子数据
✅ 首先,需要一个预训练的基础语言模型(如Llama 2 70B)和一小部分人类标注的种子数据。
✅ 种子数据包括指令跟随数据(Instruction Fine-Tuning, IFT)和评价指令跟随数据(Evaluation Fine-Tuning, EFT)。
自我指令创建
⚠ 使用少量提示(few-shot prompting)从种子IFT数据中生成新的指令提示。
⚠ 模型为给定的新指令生成多个候选响应。
⚠ 模型通过LLM-as-a-Judge机制评估这些候选响应的质量,即模型扮演自己的奖励模型角色。
指令遵循训练
❗ 从自我指令创建过程中生成的数据中选择偏好对(preference pairs),这些是由模型生成的最高分和最低分响应构成的。
❗ 使用直接偏好优化(Direct Preference Optimization, DPO)方法训练模型,得到下一代模型(Mt+1)。
迭代训练
💡 这个过程是迭代的,每次迭代都旨在改进前一次的结果。
💡 模型使用自己的输出来细化和提高其指令遵循和奖励评估能力。
💡 通过这种方式,模型在LLM对齐过程中不断更新,避免了传统模型中奖励模型固定不变的瓶颈。
实验结果与分析
| 指标 | 结果 |
|---|---|
| 指令遵循能力 | 胜率逐步提升 |
| 奖励模型能力 | 与人类评级相关性提高 |
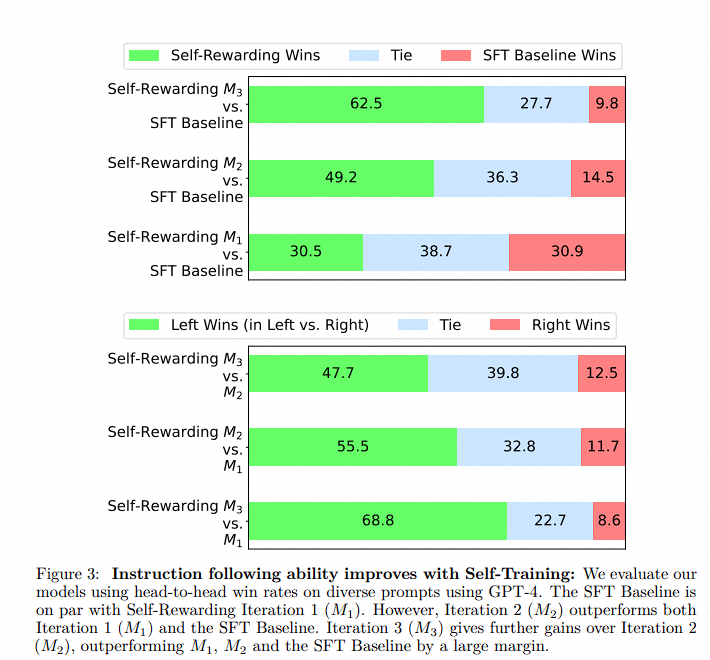
实验结果显示,通过自我奖励训练,模型在指令遵循能力和奖励模型能力上都得到了提升。在AlpacaEval 2.0排行榜上,自我奖励模型的迭代训练结果显示胜率逐步提升。
常见错误
警告:在自我指令创建过程中,可能会出现生成质量不佳的候选响应。需注意评估机制的准确性,以确保生成的偏好对能够有效提升模型性能。
行动清单
- 探索自我奖励语言模型在其他领域的应用潜力
- 研究不同预训练语言模型对自我奖励训练效果的影响
- 开发更精确的LLM-as-a-Judge评估机制以提高候选响应质量