DAPO
DAPO算法:大规模LLM强化学习系统的关键技术
元数据
- 分类:强化学习
- 标签:DAPO算法, 强化学习, 探索与利用, 奖励设计
- 日期:2025年4月12日
内容概述
在强化学习领域,探索与利用的平衡一直是一个重要的研究课题。探索鼓励智能体在环境中尝试不同策略,以期找到更优的解决方案,而利用则强调使用现有的较优策略来获得稳定的收益。奖励设计在此过程中扮演着关键角色,它直接影响策略学习的效率和效果。
DAPO算法的核心改进
💡 启发点:DAPO算法通过去掉KL散度约束项,解决了在训练长推理模型过程中策略偏离初始策略的问题。
关键技术改进
-
移除KL散度约束项:在GRPO算法中,KL散度约束用于限制策略偏离初始策略的幅度。然而,在长推理模型训练中,这种限制显得不再必要。DAPO通过移除这一约束,允许策略有更大的灵活性。
-
动态采样策略优化:DAPO引入了动态采样的方法,进一步提升了策略优化的效率。
-
奖励设计的创新:通过结合传统强化学习中的奖励设计方法,DAPO在任务相关性上取得了更好的平衡。
技术术语简化
- KL散度:一种衡量两个概率分布差异的指标。在这里用于限制策略变化。
- Long-CoT推理模型:一种需要长时间推理计算的模型类型。
- GRPO算法:一种基于深度强化学习的算法,用于大规模模型训练。
操作步骤
- ✅ 去除KL散度约束:允许策略更自由地演变。
- ⚠ 引入动态采样:根据实时反馈调整采样策略。
- ❗ 优化奖励设计:结合传统方法,提升任务相关性。
常见错误
⚠ 在移除KL散度约束时,需确保策略不会过于偏离合理范围,否则可能导致不稳定的学习过程。
行动清单
- 研究DAPO在不同任务上的适用性。
- 实施动态采样策略优化,观察其对效率的影响。
- 探讨奖励设计对不同类型任务的影响。
数据转换
| 技术改进项 | 描述 |
|---|---|
| 移除KL散度约束 | 提高策略灵活性 |
| 动态采样策略优化 | 提升策略优化效率 |
| 奖励设计创新 | 增强任务相关性 |
公式显示

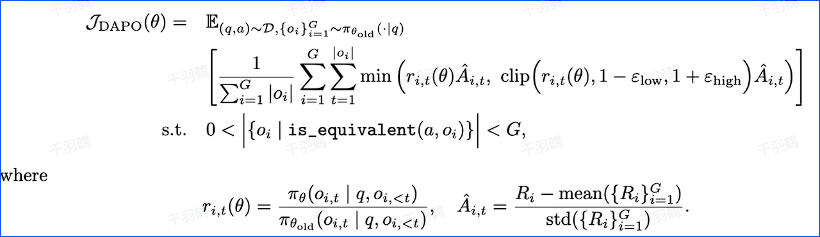
原文来源:[技术报告 DAPO: an Open-Source LLM Reinforcement Learning System at Scale]
Clip-Higher技术改进:提升低概率Token探索能力
元数据
分类:技术改进
标签:Clip-Higher, 权重裁剪, Token生成, 推理过程
日期:2025年4月12日
内容处理
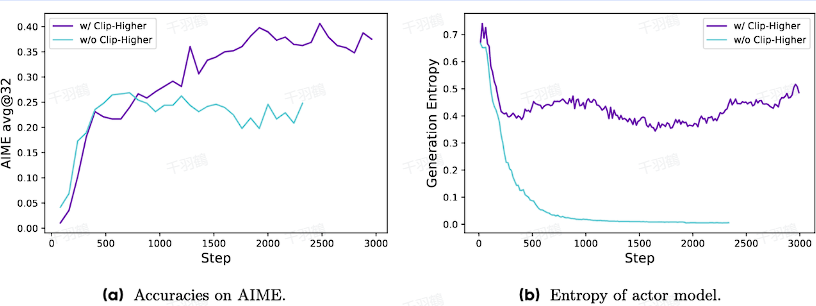
Clip-Higher是一个技术改进方法,旨在提高低概率token的探索能力。原有方法对重要性权重的裁剪阈值设置较低,限制了低概率token的生成概率增长。通过调整裁剪阈值,Clip-Higher促进学习长推理过程和新的推理范式。

核心观点
- Clip-Higher的作用:提高了重要性权重的上裁剪阈值,促进低概率token的探索。
- 原有问题:原始裁剪阈值设置为
,导致低概率token几乎没有增长。 - 改进措施:调整裁剪阈值为
和 。
技术术语转述
- 重要性权重(
):影响token生成概率的参数。 - 优势值(
):用于决定是否提高当前response中token的生成概率。 - 策略概率(
):控制token生成的概率。
操作步骤
- ✅ 确定当前优势值是否为正。
- ⚠ 如果优势值为正,考虑提高当前response中token的生成概率。
- ❗ 调整裁剪阈值以促进低概率token的探索。
常见错误
原始裁剪阈值设置过低,导致低概率token生成受限。注意调整阈值以提高探索能力。
💡启发点
通过调整裁剪阈值,Clip-Higher不仅提高了token生成的灵活性,还促进了复杂推理过程的学习。
行动清单
- 研究其他可能影响token生成的参数。
- 评估Clip-Higher在不同应用场景中的效果。
- 开发新的推理范式以进一步提升模型能力。
数据转换
| 参数 | 原始值 | 调整后值 |
|---|---|---|
| 0.2 | 0.28 |
引用来源:原始内容来自技术文档关于Clip-Higher的描述。
动态采样技术在机器学习中的应用与挑战
分类:机器学习
标签:动态采样、梯度消失、训练稳定性
日期:2025年4月12日
核心观点总结
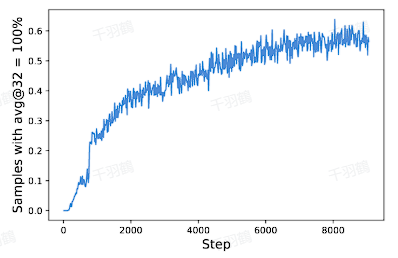
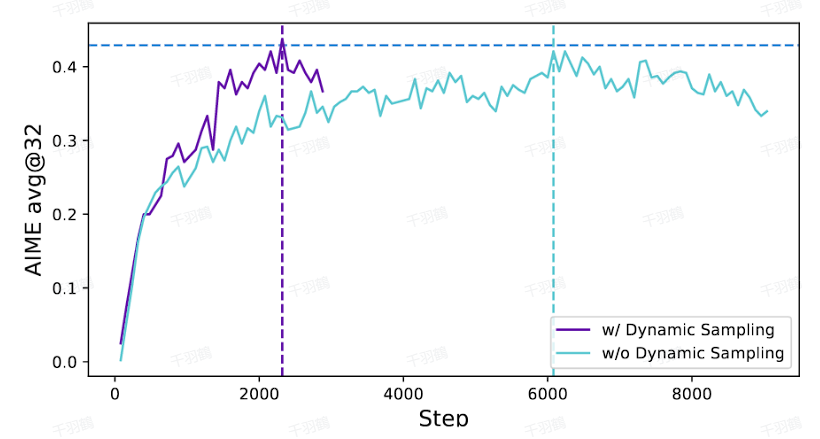
动态采样是一种在机器学习训练过程中,通过过滤掉准确率为1和0的样本,来避免梯度消失和提高训练稳定性的方法。随着训练的进行,准确率为1的样本会增多,若不加以处理,会导致梯度消失问题。

动态采样的操作步骤
- ✅ 每次训练前进行采样:在每个训练步骤开始前,对数据集进行动态采样。
- ⚠ 过滤准确率为1和0的样本:确保每个批次(batch)的样本准确率介于0到1之间。
- ❗ 避免梯度消失:通过过滤,确保在训练过程中不会因为某一组内的输出准确率为1而导致优势为0。
常见错误
警告:忽视动态采样可能导致梯度消失问题,尤其是在训练步数增加后,准确率为1的样本比例上升时。
💡 启发点
动态采样不仅能提高训练的稳定性,还能有效避免因某些样本过于简单而导致的模型退化问题。
行动清单
- 检查现有模型是否存在梯度消失问题。
- 评估动态采样对模型性能的影响。
- 实施动态采样策略,观察训练过程中的变化。
来源:[原始文本来源未提供]
Token-Level Loss 优化策略:提升深度学习模型的训练效果
元数据
- 分类:深度学习
- 标签:Token-Level Loss, 深度学习模型, 策略优化, 训练稳定性
- 日期:2025年4月12日
核心观点总结
在深度学习模型的训练中,传统的损失计算方式可能会导致长样本的贡献被低估,影响策略学习。因此,采用Token-Level Loss的计算方法可以有效地提升长样本对模型训练的影响,使得训练过程更加稳定。
重点段落
Token-Level Loss的优势
Token-Level Loss通过对每个token单独计算损失,确保长样本中的每个部分都对总损失有足够的贡献。这种方法解决了传统Sample-Level Loss可能导致的长样本贡献不均衡的问题。
训练过程的稳定性
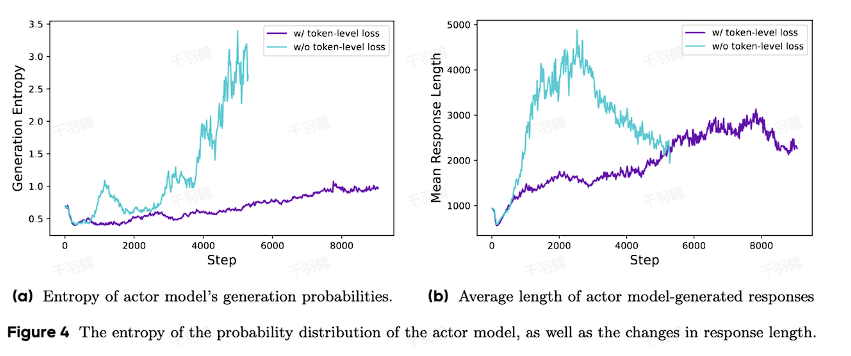
采用Token-Level Loss后,训练过程变得更加稳定,并且可以更好地控制熵值(entropy),避免策略过于随机或探索不足的问题。
问题解决与策略调整
通过将Sample-Level Loss转换为Token-Level Loss,DAPO(Deep Adaptive Policy Optimization)能够更有效地从长样本中学习关键推理模式,同时减少低质量样本对策略的负面影响。
操作步骤
- ✅ 计算每个token的loss:确保每个token对总损失有均等的贡献。
- ⚠ 控制熵值:避免策略过于随机或探索不足。
- ❗ 调整策略学习:通过Token-Level Loss,提升长样本在策略学习中的影响力。
常见错误
⚠ 在使用传统Sample-Level Loss时,长样本的贡献可能被低估,导致策略偏离高质量样本的关键推理模式。
💡 启发点
Token-Level Loss不仅提升了训练过程的稳定性,还通过更精细的损失计算方法,增强了模型对长样本的学习能力。
行动清单
- 研究更多关于Token-Level Loss在不同模型中的应用案例。
- 测试不同熵值控制策略对模型性能的影响。
- 评估Token-Level Loss对其他深度学习任务的适用性。
原始出处:[原始文档内容未提供具体出处信息]
Token-Level Loss 优化策略:提升深度学习模型的训练效果
元数据
- 分类:深度学习
- 标签:Token-Level Loss, 深度学习模型, 策略优化, 训练稳定性
- 日期:2025年4月12日
核心观点总结
在深度学习模型的训练中,传统的损失计算方式可能会导致长样本的贡献被低估,影响策略学习。因此,采用Token-Level Loss的计算方法可以有效地提升长样本对模型训练的影响,使得训练过程更加稳定。
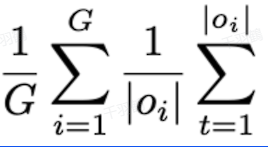
重点段落
Token-Level Loss的优势
Token-Level Loss通过对每个token单独计算损失,确保长样本中的每个部分都对总损失有足够的贡献。这种方法解决了传统Sample-Level Loss可能导致的长样本贡献不均衡的问题。
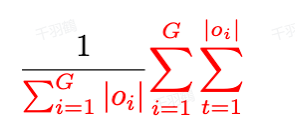
训练过程的稳定性
采用Token-Level Loss后,训练过程变得更加稳定,并且可以更好地控制熵值(entropy),避免策略过于随机或探索不足的问题。
问题解决与策略调整
通过将Sample-Level Loss转换为Token-Level Loss,DAPO(Deep Adaptive Policy Optimization)能够更有效地从长样本中学习关键推理模式,同时减少低质量样本对策略的负面影响。
操作步骤
- ✅ 计算每个token的loss:确保每个token对总损失有均等的贡献。
- ⚠ 控制熵值:避免策略过于随机或探索不足。
- ❗ 调整策略学习:通过Token-Level Loss,提升长样本在策略学习中的影响力。
常见错误
⚠ 在使用传统Sample-Level Loss时,长样本的贡献可能被低估,导致策略偏离高质量样本的关键推理模式。
💡 启发点
Token-Level Loss不仅提升了训练过程的稳定性,还通过更精细的损失计算方法,增强了模型对长样本的学习能力。
行动清单
- 研究更多关于Token-Level Loss在不同模型中的应用案例。
- 测试不同熵值控制策略对模型性能的影响。
- 评估Token-Level Loss对其他深度学习任务的适用性。
原始出处:[原始文档内容未提供具体出处信息]
优化过长回答的奖励机制:提升模型性能
分类:机器学习优化
标签:奖励机制,模型训练,性能提升
日期:2025年4月12日
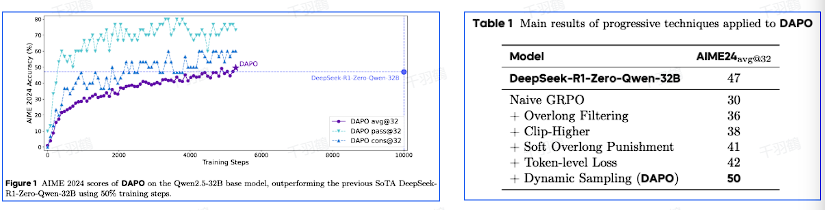
在机器学习模型的训练过程中,如何有效地处理过长回答的问题是一个关键挑战。本文探讨了一种通过奖励修改来优化过长回答的方法,并在Qwen2.5-32B模型上进行了实验验证。
核心观点
这篇文章介绍了一种称为“soft punishment”的方法,用于对过长的回答进行惩罚,并将其叠加到准确率奖励上,从而稳定训练过程并提升模型性能。实验结果表明,在数学任务AIME2024上,该方法仅用50%的训练步数就超过了传统的GRPO方法。
重点内容
-
奖励修改方法
使用一种软惩罚机制对过长回答进行处理,具体公式为: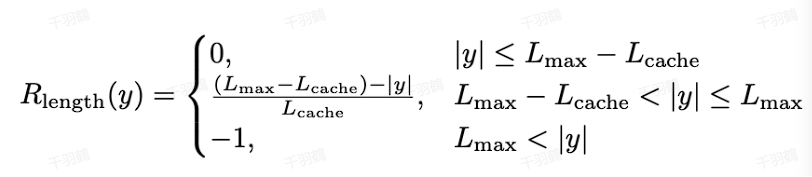
-
这种方法能够有效稳定训练过程,提高模型性能。
-
实验结果
在Qwen2.5-32B模型上进行的实验表明,该方法在数学任务AIME2024上的表现,仅用50%的训练步数就超过了GRPO。
-
💡启发点
通过调整奖励机制,可以在保持准确率的同时,减少训练时间和资源消耗。
操作步骤
- ✅ 确定过长回答的阈值。
- ⚠ 实施soft punishment机制,并计算惩罚值。
- ❗ 将惩罚值与准确率奖励结合,应用于模型训练。
常见错误
⚠ 在设置过长回答阈值时,需根据具体任务调整,以避免对模型性能产生负面影响。
行动清单
- 研究其他任务中soft punishment机制的适用性。
- 探索不同参数设置对模型性能的影响。
- 记录并分析不同训练步数下的模型表现。
原始出处:本文内容基于某项目中的实验记录与总结。