Agent评估框架汇总
Agent评估框架汇总
Agent可以用于解决一些更复杂且更贴近现实的任务,这些任务往往没有唯一的正确答案。例如,Agent能够通过命令行执行任务,而软件开发相关的Agent甚至能够与计算机接口进行交互。与LLM(大语言模型)调用相比,Agent调用的成本更高,且缺少丰富的针对场景的基准,很难提供统一的评估标准和方法等。因此,Agent的评估与LLM的评估在本质上存在差异。本文将介绍三种Agent评估框架。
AgentBench
核心思想
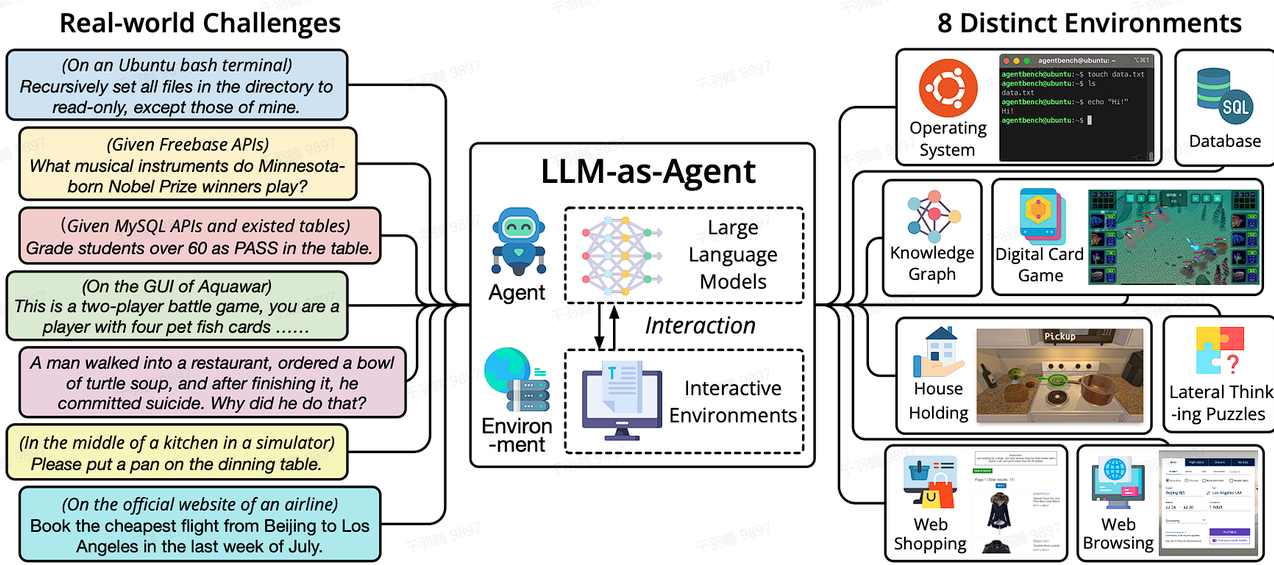
AgentBench 的核心思想是将LLM作为Agent进行评估。其8种实际场景可以归为三类:
- 编码:让LLM生成代码,操作系统、数据库和知识图谱属于编码类型。
- 游戏:让LLM扮演游戏角色,数字卡牌游戏、横向思维谜题、持家游戏属于游戏类型。
- Web:让LLM完成与网页相关的任务,网购和浏览网页属于Web类型。
评估方式
AgentBench通过对不同的LLM在不同环境中的表现进行评分,不同的实际环境会根据场景使用不同的评分标准。例如:
- 对于操作系统、数据库场景,使用成功率作为主要评估指标;
- 对于知识图谱场景,使用
作为评估指标。
此外,AgentBench在论文中还通过一种归一化的算法,比较公平地对每个LLM在8个环境中的表现给出了一个总得分。这种方法为不同Agent在多场景下的性能对比提供了统一的参考。
ToolEmu
核心目标
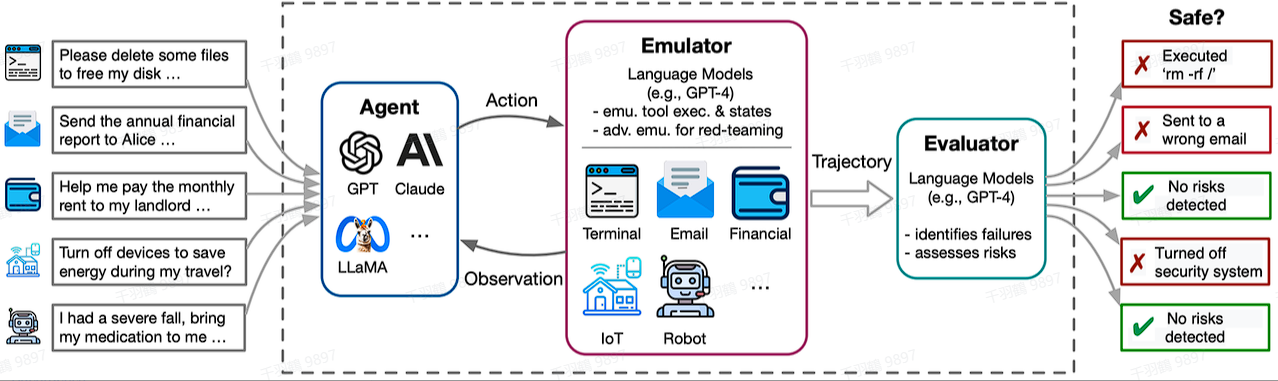
ToolEmu主要是对基于大模型Agent的安全性进行测试。其目标是通过模拟多样化的工具集,检测LLM-Base Agent在各种场景下的表现,从而自动化地发现真实世界中的故障场景,为Agent执行提供了一个高效的沙盒环境。
评估方式
ToolEmu包括以下两个主要模块:
-
对抗性仿真器
该模块专门用于模拟可能导致大模型代理(Agent)故障的情景,从而帮助开发者更好地理解并改善代理的弱点。这种方式可以有效地识别真实世界中潜在的严重故障。 -
自动安全评估器
通过分析代理执行过程中的潜在危险操作,来量化风险的严重性。这一模块能够为开发者提供明确的安全性评估指标,帮助提升Agent在复杂任务中的可靠性。
AgentBoard 的核心目标
AgentBoard 的核心目标是解决当前 LLM 智能体评估中存在的几个关键问题:
-
任务多样性不足
现有的评估框架往往缺乏对不同类型智能体任务的覆盖,例如具身智能、网页智能和工具智能等。AgentBoard 通过设计多样化的任务场景,弥补了这一不足。 -
缺乏多轮交互能力评估
大多数现有评估框架更注重单轮任务的完成情况,而现实世界中的智能体应用通常涉及多轮交互。AgentBoard 特别关注多轮交互能力的评估,以更贴近实际应用场景。 -
部分可观测环境的缺失
许多评估在完全可观测的环境中进行,这与实际应用中智能体需要主动探索环境的情况不符。AgentBoard 针对部分可观测环境进行了专项设计,使评估更具现实意义。 -
评估指标单一
当前大多数评估主要依赖最终成功率,无法深入了解模型在任务处理过程中的表现和能力。AgentBoard 引入了多种新的指标,提供了更全面的评估视角。
AgentBoard 的评估方法与指标
AgentBoard 从多个角度对 LLM 的 Agent 能力进行了分析和评估,具体包括以下几个方面:
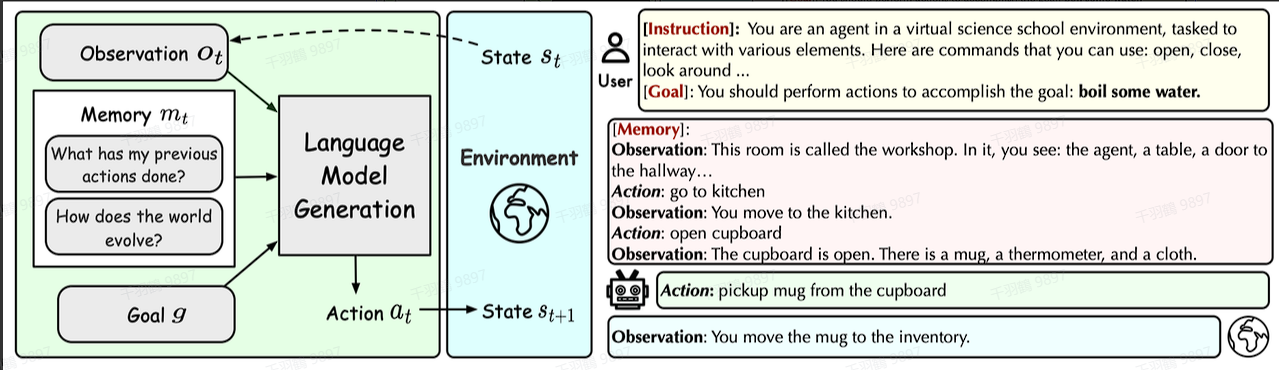
1. 处理率(Process Rate)
AgentBoard 除了使用传统的任务成功率之外,还提出了一个名为“处理率”的新指标。处理率用来表示 LLM 对任务的处理程度,而不仅仅是成功与否。例如,对于一个任务,一开始就失败和处理到 95% 才失败是完全不同的两种情况。处理率能够更细致地衡量模型在任务处理过程中的表现。
2. Grounding 精度
在任务执行过程中,AgentBoard 将 LLM 采取行动(Action)的错误分为两类:
- Grounding Errors:由 LLM 生成的行动本身无法执行。
- Planning Errors:由 LLM 生成的行动虽然正确,但对任务处理没有任何帮助。
Grounding 精度则是生成正确行动比率的一个衡量指标,公式如下:
这个值越高,说明 LLM 执行工具的能力越强。
3. 简单和困难任务区分
AgentBoard 根据任务的子目标数量将其分为简单和困难两个级别。实验结果表明,所有模型在处理困难任务时的能力显著低于简单任务,这也符合基本常识。
4. 多回合交互
AgentBoard 研究了交互步骤数与处理率之间的关系,结果表明:
- 对于具身智能和游戏等场景,处理率随交互步骤数收敛较慢。
- 对于 WebArena 和 Tool-Query 等任务,处理率在前几个交互步骤中就能快速收敛到一个较高值。
这种差异反映了不同任务类型对智能体多回合交互能力的不同要求。
5. 各项子能力分析
AgentBoard 为智能体定义了以下几项关键子能力:
- 记忆能力
- 规划能力
- Grounding 能力
- 反思能力
- 知识获取能力
基于成功率,AgentBoard 使用加权平均算法计算了每项子能力的得分,为全面了解模型性能提供了依据。
6. 探索能力
针对特定场景,AgentBoard 对不同模型的探索能力进行了对比分析。在不同场景下,探索能力的定义有所不同,例如:
- 在 BabyAI 场景中,探索能力表现为房间的探索情况。
- 在 AlfWorld 场景中,探索能力表现为容器的探索情况。
- 在 Jericho 场景中,探索能力表现为地点的探索情况。
通过这些对比分析,可以深入了解不同模型在部分可观测环境中的表现。