基于大模型的智能体原理
基于大模型的智能体的原理
什么是LLM Agent?
LLM Agent是一种超越简单文本生成的人工智能系统。它以大语言模型(LLM)作为核心计算引擎,使其能够与用户进行对话、执行任务、进行推理,并展现出一定程度的自主性。简而言之,LLM Agent是一个具有复杂推理能力、记忆和执行任务能力的系统。
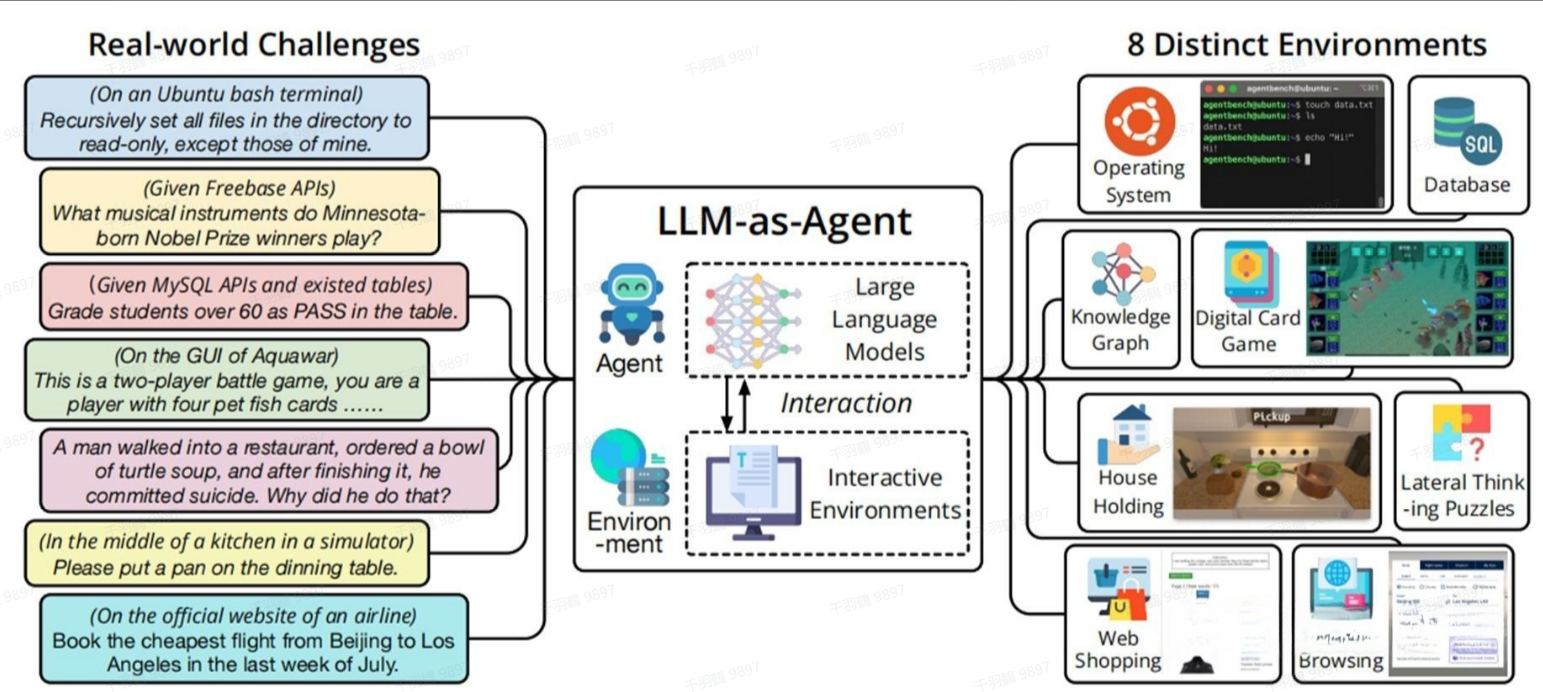
LLM Agent的定义可以概括为:通过与生成式人工智能(GenAI)本身之外的系统交互来服务于用户目标的GenAI系统。
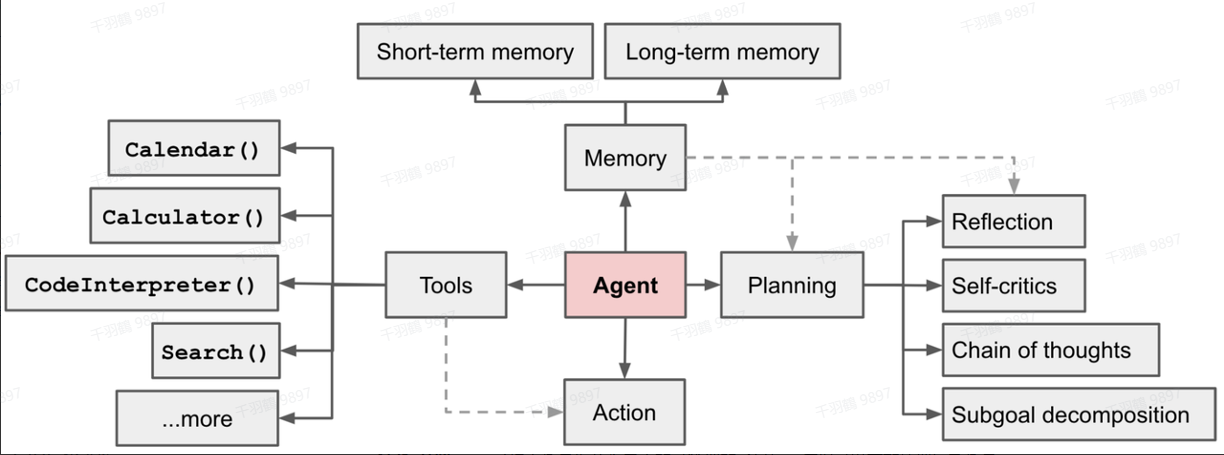
LLM Agent的核心组成
LLM Agent可能涉及单个外部系统(如计算器),也可能需要解决更复杂的路由问题,以决定需要使用哪种外部系统(通常包括记忆和规划功能)。总体而言,基于大模型的智能体(LLM-based Agent)的核心组成可以表示为:
规划(Planning)
子目标分解
在规划过程中,Agent会将一个复杂的大任务拆分为更小、更易于管理的子目标,从而能够更加高效地完成复杂任务。
目的
很多复杂任务通常由多个步骤组成,Agent需要清楚这些步骤是什么,并提前规划。例如,在前面提到的5.1.2章节中,CoT(Chain of Thought)以及其改进方法实际上就是在进行任务分解。
任务分解的实现方式
以下是实现任务分解的几种方式:
-
直接提示:给LLM一个简单的提示词,例如:
Steps for XYZ. 1.或者:
What are the subgoals for achieving XYZ? -
具体指令:针对特定任务提供明确指令。例如,对于写小说的任务,可以先给出“Write a story outline.”这样的指令。
-
用户输入:由使用者直接输入明确的任务需求。
无论是CoT还是ToT(Tree of Thought),其本质都是通过精心设计的Prompt,激发模型原有的元认知(Metacognition)。关键在于如何通过某条神经元的线索,更加精准地调动模型中最擅长规划(Planning)的部分。
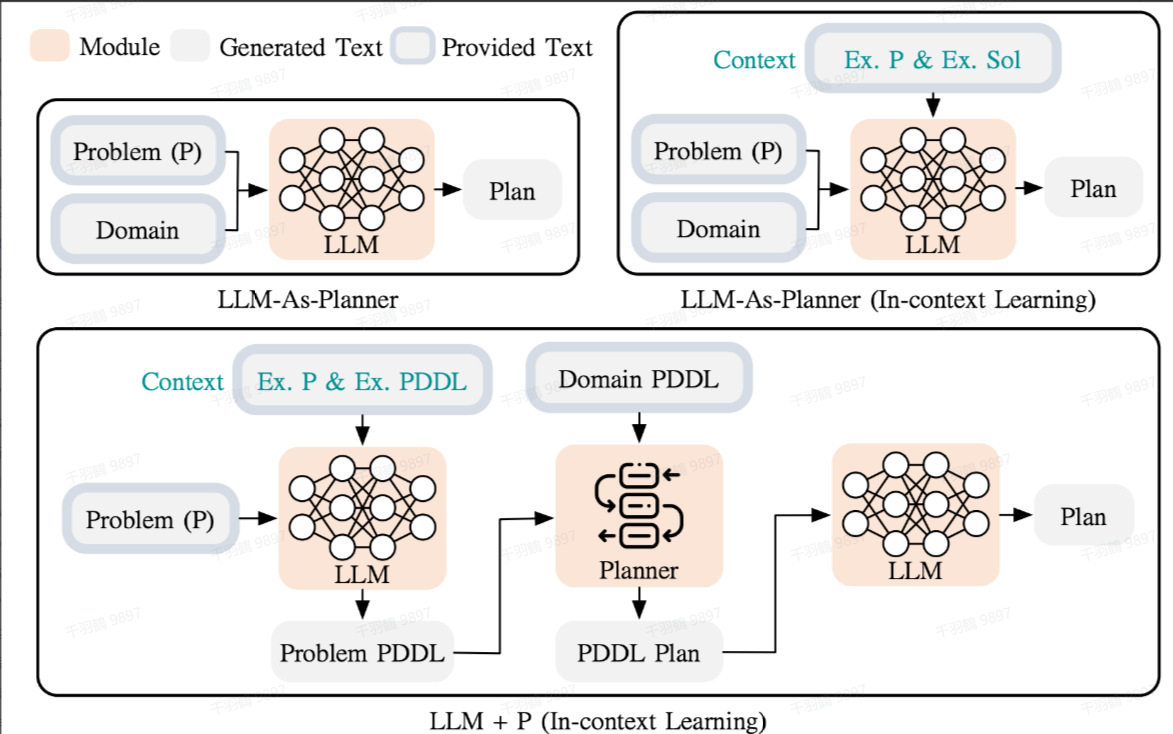
LLM与PDDL结合的规划方法
一种更为高级的规划方法是利用LLM进行长序列的整体规划。具体来说,这种方法使用规划域定义语言(PDDL,Planning Domain Definition Language)作为中间接口来描述规划问题。以下是具体步骤:
- 问题翻译:首先,LLM将问题翻译为PDDL格式的问题描述(问题PDDL)。
- 调用经典Planner:接着,请求经典Planner根据现有的领域PDDL生成一个PDDL计划。
- 自然语言翻译:最后,将PDDL计划翻译回自然语言,这一步由LLM完成。
从根本上讲,Planning步骤被外包给了外部工具。但这需要满足一个前提条件:必须有特定领域的PDDL定义和合适的Planner工具。
反思与完善
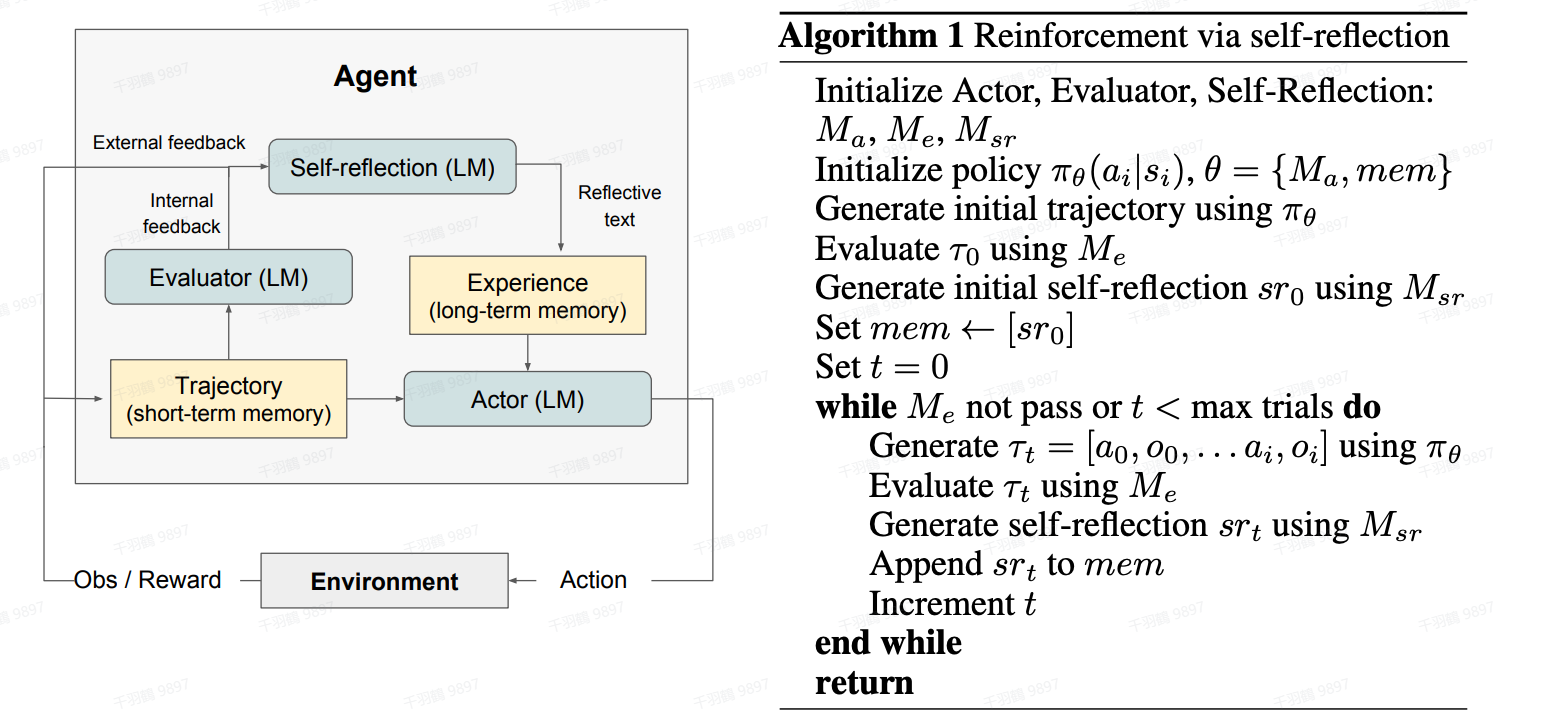
自我批评与反思
Agent能够对历史动作进行自我批评和反思,从错误中学习,并在后续步骤中不断完善,从而提高最终结果的质量。自我反思(Self-reflection)是一个非常重要的环节,它允许Agent通过完善过去的行动决策和纠正以前的错误来持续改进。
在现实世界中的任务中,试错往往是无法避免的,而自我反思在其中发挥着至关重要的作用。
ReAct:结合推理与行动
ReAct是一种被分类在5.2.3章节中的Observation-based Agent方法,其全称为Reason+Act。该方法通过将Action Space扩展为特定任务的离散动作和语言空间的组合,在LLM内部整合了推理(Reasoning)和行动(Action)。
- 推理:使得LLM能够与环境交互。
- 行动:通过提示词,使得LLM用自然语言生成整体推理过程。
ReAct提示词模板包含特定设计,以支持这种推理与行动结合的方法。
记忆(Memory)
短期记忆与长期记忆
短期记忆:上下文学习
短期记忆指的是利用模型的短期记忆进行学习的能力。在上下文学习中,模型能够在短时间内获取、存储并处理信息,从而完成任务。
长期记忆
长期记忆为智能体(agent)提供保留和召回长期信息的能力。通常,这种能力通过外部向量存储和检索来实现。长期记忆的特点在于它能够支持信息的长时间保存与高效访问。

记忆的定义与分类
记忆可以定义为一种用于获取、存储、保留和随后检索信息的过程。在人脑中,记忆可以分为以下几种类型:
感官记忆
感官记忆是记忆的最早期阶段,它指的是对原始刺激的感官印象(如视觉、听觉等)的保留能力。这类记忆通常只能持续几秒钟,包含以下三种类型:
- 图标记忆:与视觉相关的记忆。
- 回声记忆:与听觉相关的记忆。
- 触碰记忆:与触觉相关的记忆。
短时记忆(STM)或工作记忆
短时记忆存储我们当前意识到的信息,以及执行复杂认知任务(如学习和推理)所需的信息。短时记忆的容量通常为 7 个项目左右,并能够持续 20-30 秒。
长时记忆(LTM)
长时记忆能够将信息存储很长时间,从几天到几十年不等,其存储容量基本上是无限的。长时记忆可进一步分为以下两种类型:
-
显性/陈述性记忆
显性记忆是对事实和事件的记忆,指那些可以有意识地回忆起的内容,包括:- 外显记忆:关于事件和经历的记忆。
- 语义记忆:关于事实和概括的记忆。
-
隐性/程序性记忆
隐性记忆是无意识的,涉及自动执行的技能和例行程序,例如骑自行车或在键盘上打字。
最大内部产品搜索(Maximum Inner Product Search, MIPS)
在利用外部存储器缓解关注范围有限的问题时,最大内部产品搜索(MIPS)是一种有效的方法。为了优化检索速度,常采用近似最近邻(ANN)算法。这些算法通过牺牲少量精度来显著提升速度,并返回近似的前
LSH (局部敏感哈希)
LSH 引入了一种哈希函数,该函数能够最大限度地将相似的输入项映射到同一个桶中。桶的数量远小于输入内容的数量,从而实现快速检索。
ANNOY (Approximate Nearest Neighbors Oh Yeah)
ANNOY 的核心数据结构是随机投影树,这是一种二叉树集合。具体而言:
- 每个非叶子节点表示将输入空间划分为两半的一个超平面。
- 每个叶子节点存储一个数据点。
这些树是独立随机构建的,在某种程度上模拟了哈希函数的作用。在搜索过程中,ANNOY 会在所有树中迭代地搜索最接近查询点的一半,然后聚合结果。其思想与 KD 树非常相关,但具有更强的可扩展性。
HNSW (Hierarchical Navigable Small World)
HNSW 的设计思想来源于小世界网络。在小世界网络中,每个节点只需通过很少的步数即可连接到其他任何节点,例如社交网络中的“六度分隔”理论。
- HNSW 构建了多层的小世界网络结构,其中底层包含实际的数据点。
- 中间层创建了一些“快捷键”,以加速搜索过程。
通过这种分层结构,HNSW 能够在大规模数据集上实现高效搜索。
工具使用(Tool Use)
在人工智能领域,模型的能力在很多情况下可能受到权重丢失信息的限制。为了弥补这一不足,智能体(Agent)可以通过调用外部API获取额外的信息。这些信息包括但不限于:
- 当前的实时信息
- 代码执行能力
- 专有信息源的访问
这种工具的使用,使得智能体能够更好地应对复杂的任务,同时提升其处理问题的灵活性和准确性。
智能体与LLM的区别
与LLM的交互方式
与大语言模型(LLM, Large Language Model)的交互非常直接——你只需要输入一个提示,大模型会基于输入生成一个回答。这种交互模式简单直观,但往往缺乏深入的思考和迭代过程。

与Agent的交互方式
与智能体(Agent)的交互则更加复杂和动态。它不仅仅是简单地生成回答,而是模拟一种助手的行为。以下是一个典型的Agent交互流程:
- 你提出一个问题或任务。
- Agent会先询问是否需要进行一些网络研究。
- 在必要时,Agent会主动获取相关信息,写下初稿。
- Agent会回顾初稿,并思考哪些部分需要修改。
- Agent对草稿进行修改。
- 这个过程会不断进行思考和迭代,直到最终得到满意的结果。
这个流程可以总结为一个 思考 + 迭代 的过程,体现了Agent在解决问题时的主动性和灵活性。

与强化学习智能体的区别
强化学习智能体
强化学习(Reinforcement Learning, RL)智能体的输入和输出通常局限于特定的环境中。具体来说:
- 输入:强化学习智能体接收的是预设好的向量化环境状态,或者是图像等结构化数据。
- 策略:策略通常由简单的神经网络结构初始化,并通过不断训练进行优化。
- 输出:输出动作多为底层控制,例如移动、攻击等。
这种智能体主要应用于特定的任务场景,例如游戏AI、机器人控制等。
基于大模型的智能体
相比于传统强化学习智能体,基于大语言模型(LLM)的智能体具有更广泛的适用场景和更高层次的处理能力:
- 输入:基于大模型的智能体接受的是文字输入。在多模态场景下,还可以处理视觉、语音等信息。
- 策略:策略基于预训练的大语言模型,这些模型具备丰富的世界知识。
- 输出:输出形式为文本,但可以通过结构化输出和提取实现
function_call,从而与现实环境进行进一步交互。
这种智能体不仅能处理复杂的文字任务,还能通过调用函数或API,与外部世界互动。例如,它可以通过命令控制外部设备,或者从数据库中提取信息,从而实现更高效的信息处理和决策支持。