智能体的分类
智能体分类
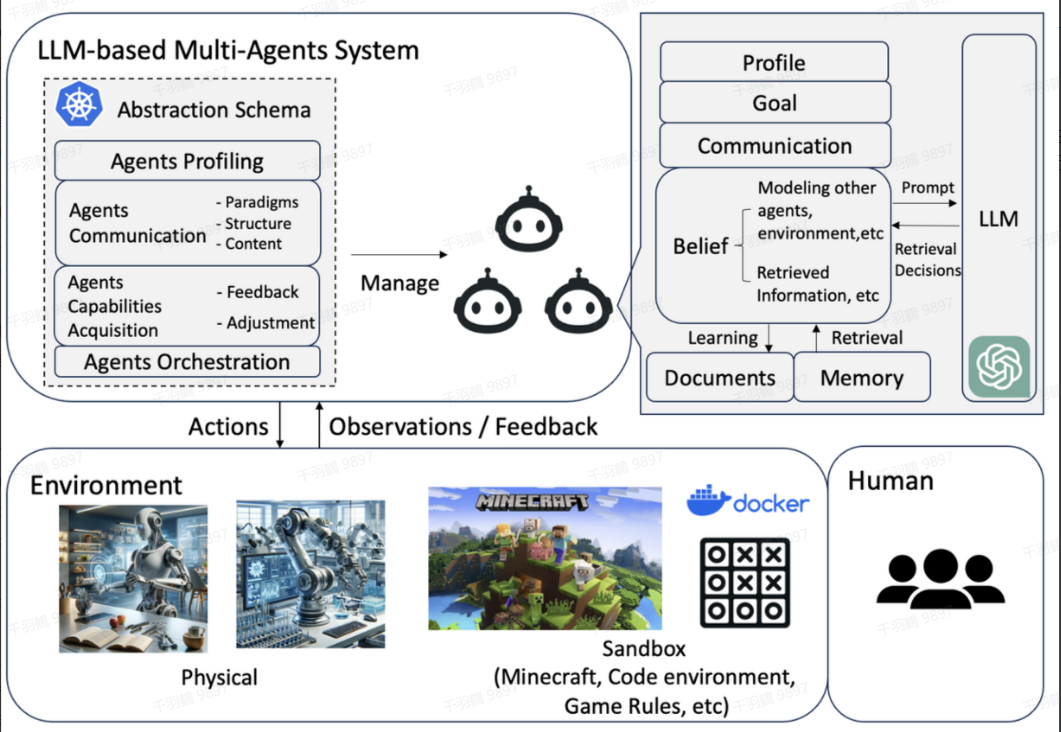
在人工智能领域,智能体(Agent)是一个非常重要的概念。智能体是能够感知环境并采取行动以实现特定目标的系统。根据智能体的数量和交互方式,我们可以对其进行分类。本文将从智能体数量的角度,探讨两种主要的智能体分类:单个智能体(SingleAgent)和多个智能体(MultiAgent)。
按照数量分类
SingleAgent:单个智能体进行任务规划与行动
单个智能体(SingleAgent)是指在特定任务中,仅有一个智能体负责感知环境、规划任务并采取行动。此类智能体通常独立完成目标,不涉及与其他智能体的交互。
单个智能体的特点包括:
- 独立性:智能体独自运行,无需与其他智能体协作。
- 任务清晰:目标通常是单一且明确的,任务复杂度相对较低。
- 应用场景:适用于简单的自动化任务,例如自动驾驶中的单车导航、家庭中的扫地机器人等。
由于单个智能体不需要处理复杂的交互逻辑,其设计和实现相对简单,但它的能力和适用范围也因此受到限制。
MultiAgent:多样化的智能体协作与集体决策
多个智能体(MultiAgent)系统则强调多样化的智能体特性,以及智能体之间的交流、相互作用和集体决策过程。相比于单个智能体,多个智能体系统更适合解决动态、复杂的任务。
多个智能体系统的核心特征
-
多样化的智能体特性
每个智能体都具有独特的策略和行为。这种多样性使得系统能够应对不同场景和问题。例如,在一个机器人团队中,有些机器人可能擅长感知环境,有些则擅长执行具体任务。 -
交流与相互作用
智能体之间通过通信机制共享信息。例如,某个智能体可能发现了一个新的环境变化,它可以通过通信将这一信息传递给其他智能体,从而提高整个系统的效率。 -
集体决策
多个智能体通过协作、辩论和讨论,共同制定决策。这种集体决策方式可以有效解决单个智能体难以应对的问题。例如,在灾难救援中,多个机器人可以分工合作,同时根据实时变化调整策略。
多个智能体系统的优势
- 更高的灵活性:由于多个智能体彼此协作,可以动态应对复杂环境中的变化。
- 任务分解与并行处理:复杂任务可以被拆解为多个子任务,由不同的智能体分别完成,从而提高效率。
- 容错性强:即使某些智能体出现故障,其他智能体仍然可以继续完成任务。
应用场景
多个智能体系统广泛应用于以下领域:
- 物流与运输:无人机群进行货物配送。
- 灾害救援:机器人团队在受灾区域搜索幸存者。
- 游戏与模拟:多人在线游戏中的虚拟玩家或对手。
按行为模式分类
Tool Use Agent
MRKL System:Modular Reasoning, Knowledge, and Language
MRKL系统(Modular Reasoning, Knowledge, and Language)是一种模块化推理、知识和语言的技术框架。在这种系统中,一个大型语言模型(LLM)被用作路由器(router),提供对多种工具的访问。路由器可以多次调用外部工具获取诸如时间、天气等信息,并结合这些信息生成最终回复。
以下是一些与MRKL系统相关的技术工作,这些方法与MRKL系统类似,并且大部分都包含了微调过程:
- Toolformer
- Gorilla
- Act-1
- Hugging-gpt
- ToolkenGPT
这些技术框架的共同点在于通过集成外部工具的能力来增强模型的功能,使其能够更高效地完成复杂任务。
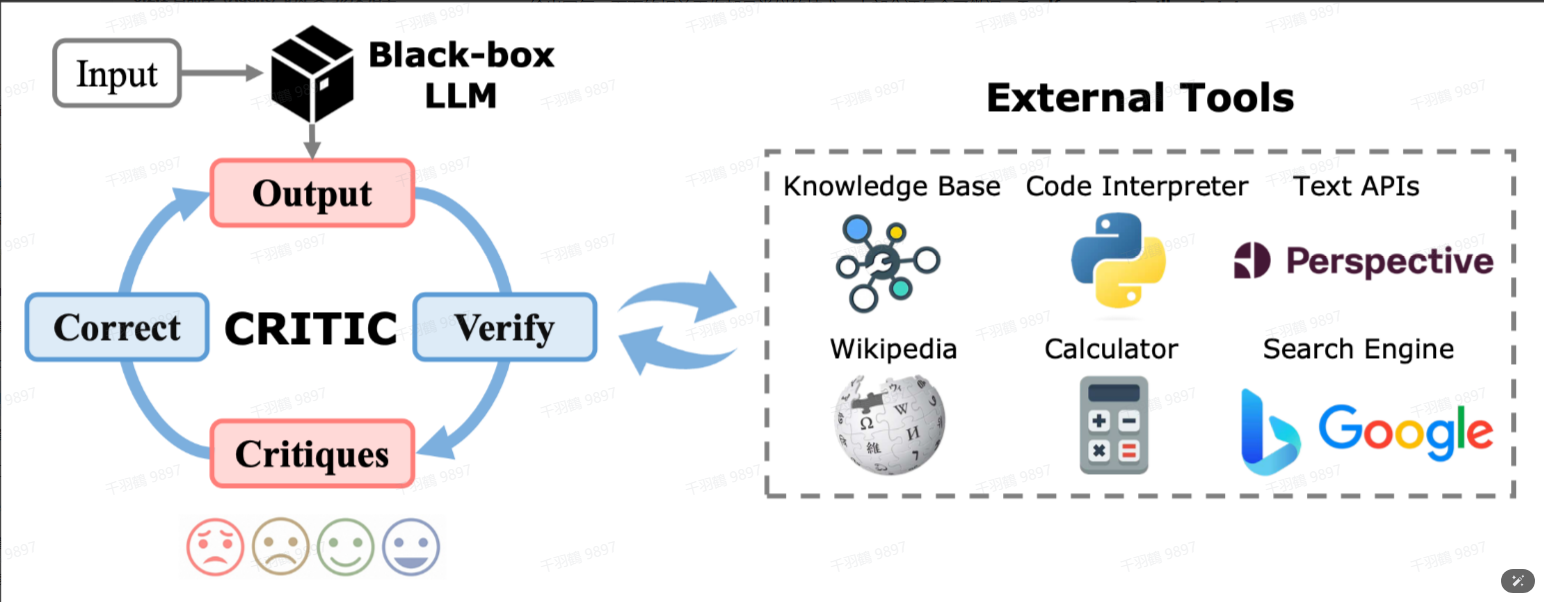
CRITIC:Self-Correcting with Tool-Interactive Critiquing
CRITIC是一种利用工具交互评价来自我修正的技术框架。其核心流程包括以下几个步骤:
- 根据给定的提示(prompt)生成初步回答。
- 使用与生成回答相同的LLM对回答中的潜在错误进行评估和批判(criticize)。
- 借助外部工具(如联网搜索、代码解释器等)验证或修正部分回答。
这种方法通过引入“批判”和“修正”的步骤,有助于提高回答的准确性和可靠性。
CRITIC的流程图如下:
注:
Code Generation Agent
代码编写和执行能力是Agent的一项重要能力,同时也可以被划分为Tool Use Agent的一类,因为代码解释器等工具本身可以看作是“工具”。
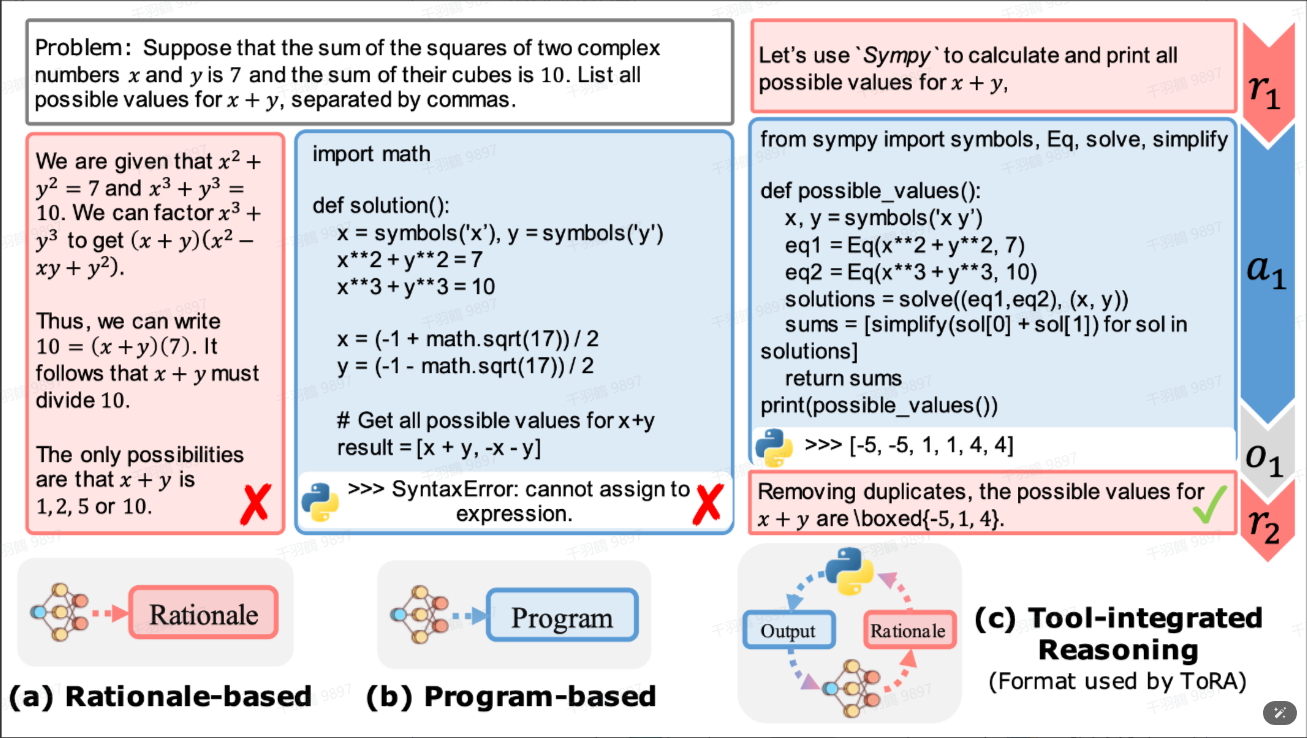
Program-aided LM
Program-aided LM是一种将问题直接转换为代码,然后利用Python解释器生成答案的方法。这种方式通过程序化的方式解决问题,充分发挥了代码生成和执行的能力。

Tool-Integrated Reasoning Agent
Tool-Integrated Reasoning Agent是一种与PAL(Program-Aided Language Models)类似的方法,但不同之处在于它允许代码生成与推理多步交叉,直到问题得到解决。而PAL方法则仅支持单个代码生成步骤。
以下是CoT(Chain of Thought)、PAL以及Tool-Integrated Reasoning Agent之间的对比图:
注:
TaskWeaver
TaskWeaver同样是一种类似PAL的方法,但它具有更强的扩展性,因为用户可以定义并利用插件来完成任务。这种方法通过引入用户定义的插件,进一步增强了模型的灵活性和适应性。
注:
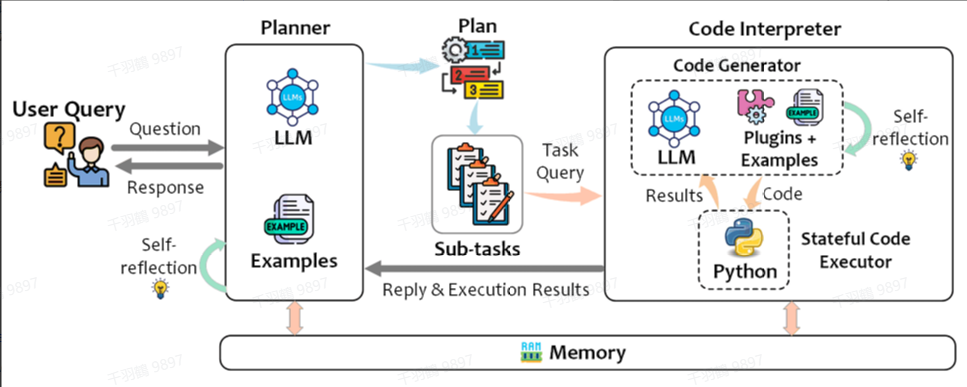
Observation-based Agent
具体方法
Reasoning and Acting
传统的CoT(Chain-of-Thought)方法存在幻觉和错误传播问题,而仅基于Act-only的方法又不能充分利用LLM(Large Language Model)在高层目标规划上的推理能力。
为了解决这些问题,提出了一种结合LLM推理和生成动作能力的方法。具体而言,这种方法交替生成推理轨迹和特定任务的动作,重复以下流程:
- 产生一个thought(推理步骤)。
- 采取一个动作。
- 接收一个观测。
然后将所有的信息加入到Prompt中,等同于保存了过去经历的记忆。此外,该方法支持外部工具的访问。ReAct方法仅需学习1到6个context examples即可泛化到新任务实例。
流程及与CoT和Act-only方法的对比

Reflexion
LLM快速从trial-and-error中学习仍然是一个很大的挑战,因为传统的强化学习方法需要大量的训练样本和昂贵的模型微调。但Reflexion方法引入了三个不同的模型来解决这一问题:Actor、Evaluator和Self-Reflection。
- Actor:生成文本和动作,并在环境中接收观察结果。
- Evaluator:评估Actor产生的轨迹质量,并计算一个奖励分数以反映其性能。
- Self-Reflection:对反馈内容进行反思(如“做了什么”、“什么出错了”),然后将反思结果加入Prompt作为记忆,在任务中不断迭代优化,从而提高决策能力。
流程图
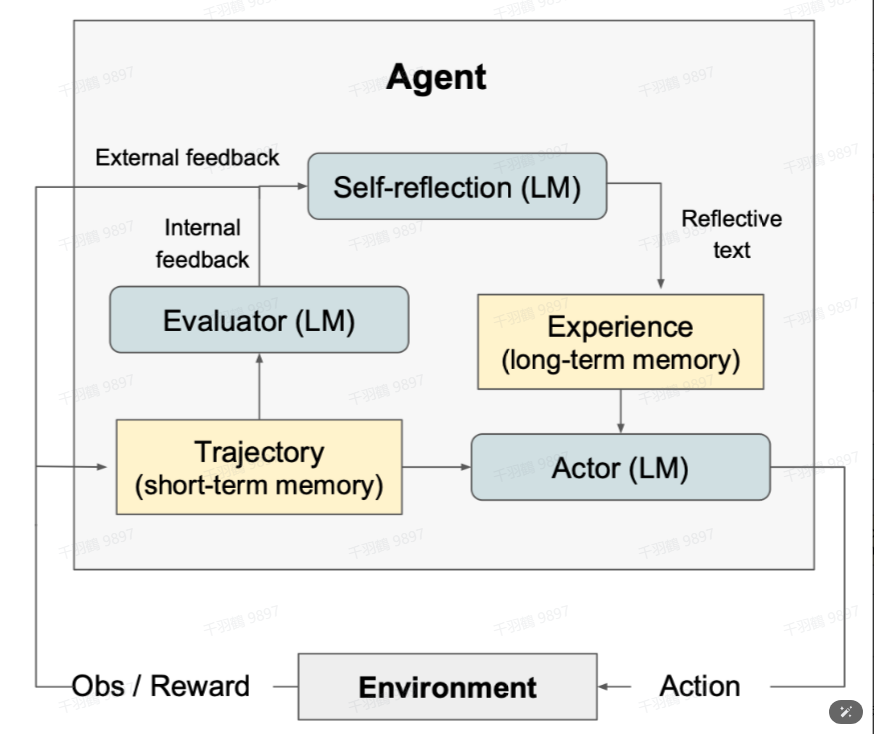
内部反馈与外部反馈
- 内部反馈是Evaluator给出的反馈。
- 外部反馈是环境给出的标量奖励之类的反馈。
Lifelong Learning Agents
Lifelong Learning Agents是能够在需要终身学习的真实世界任务中进行探索的智能体(如MC等任务环境)。
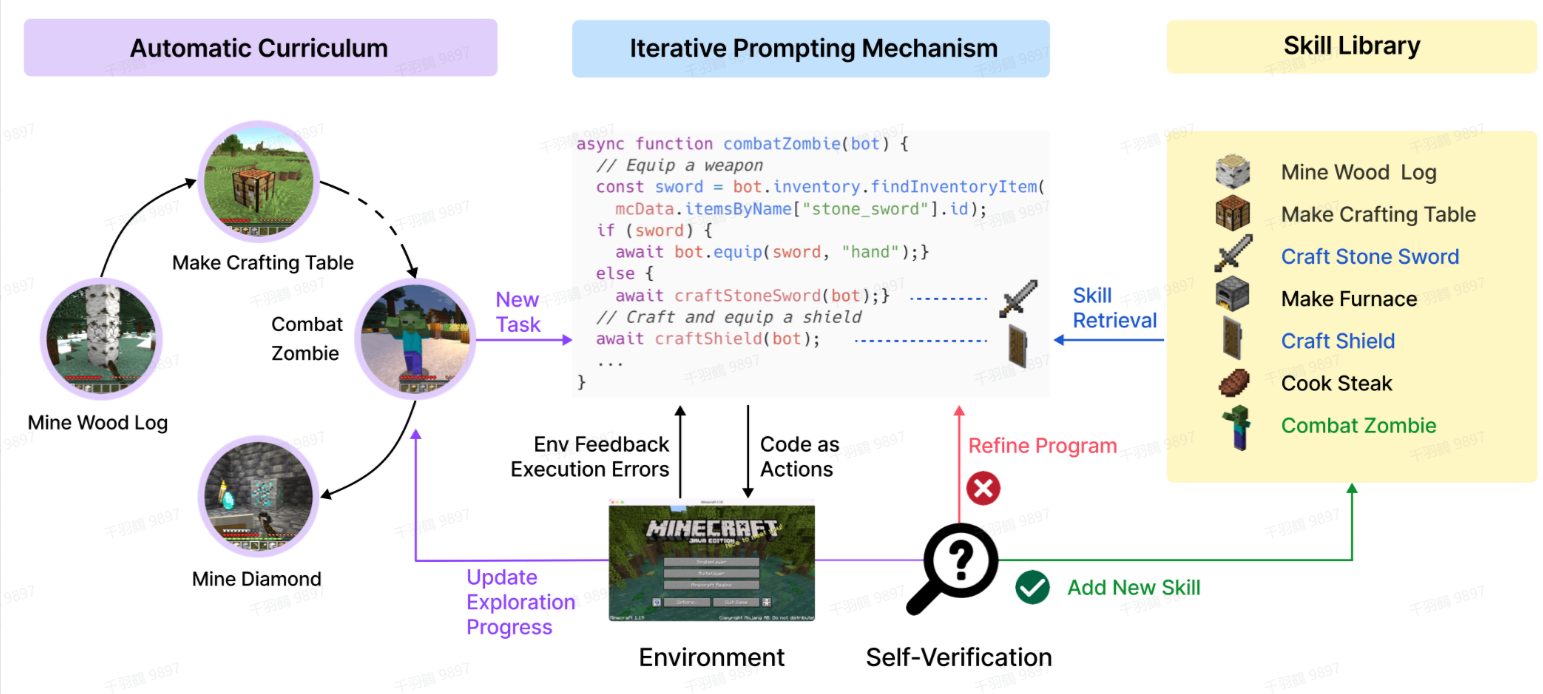
Voyager
Voyager主要包含以下三个部分:
- 自动课程任务生成:用于探索开放世界。
- 迭代式生成代码:与环境交互并执行动作。
- Self-Verification:将新技能加入技能库(skill library)以便技能召回。
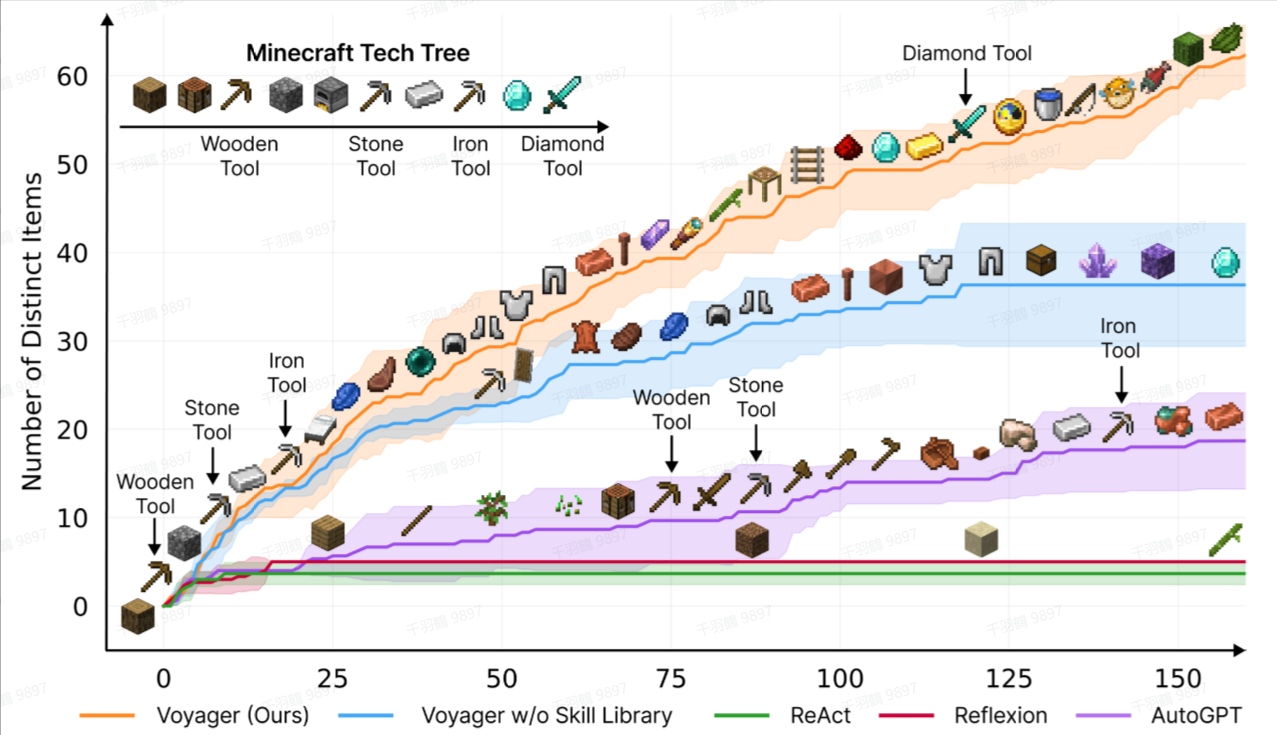
在实验中,Voyager对比了ReAct、Reflexion和AutoGPT,结果显示其性能大幅领先。
流程图
实验结果
Ghost in the Minecraft (GITM)
GITM通过LLM将一开始的目标(goal)分解为子目标(subgoals),然后迭代地进行计划(plan)和执行结构化文本(action)。此外,GITM还使用了外部知识库来辅助目标分解以及存储经验。
流程图
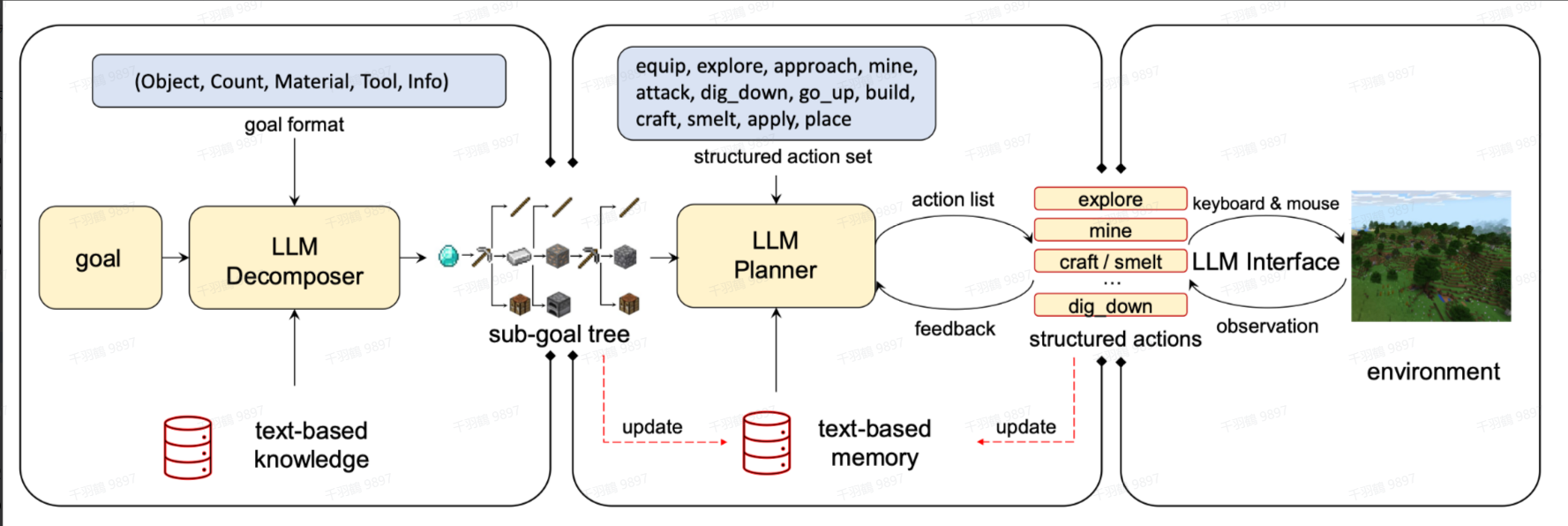
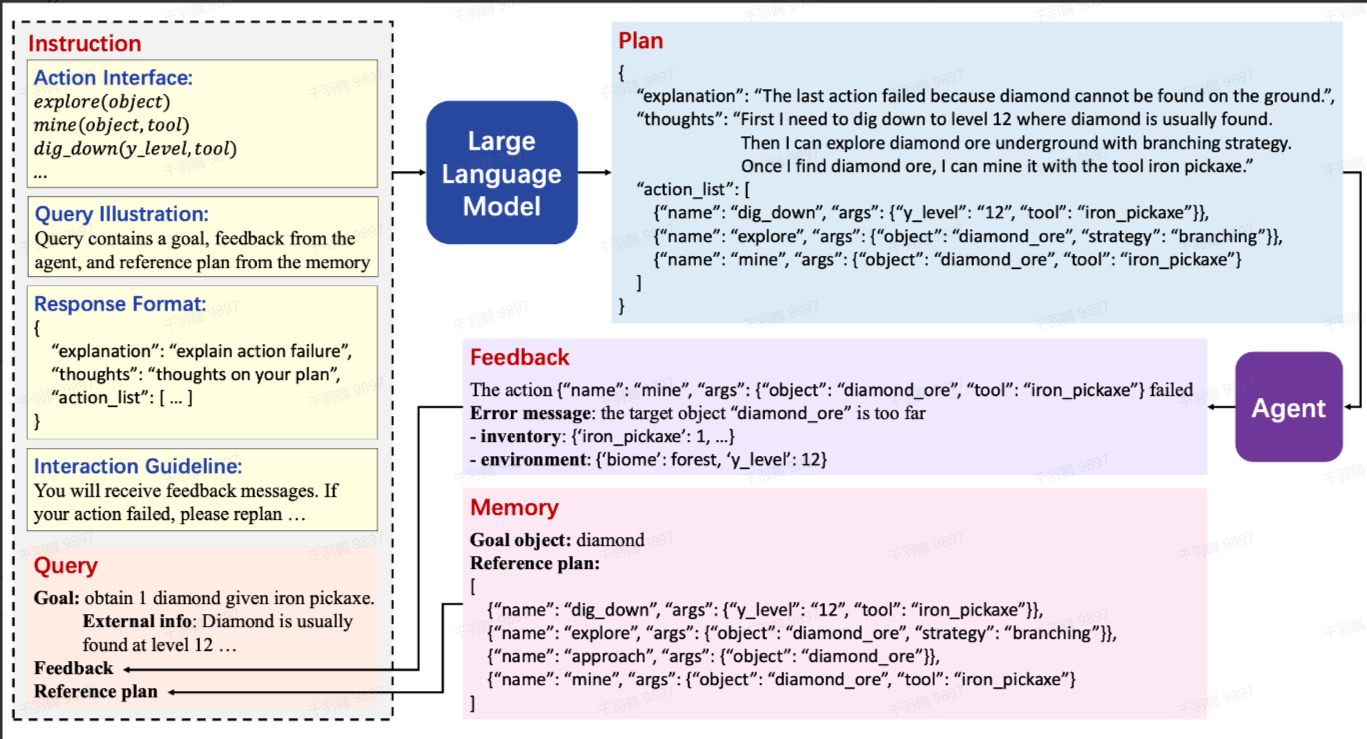
LLM Planner 示例
RAG Agent
从外部来源检索信息的范式
RAG(Retrieval-Augmented Generation)是一种通过从外部来源(如本地知识库、向量数据库等)检索信息并将其插入到提示(prompt)中的技术范式。它的出现显著提升了知识密集型任务的性能。实际上,RAG 可以被视为一种特殊的 Agent,通常通过调用外部数据库或向量库作为工具来实现信息的补充与增强。
具体方法
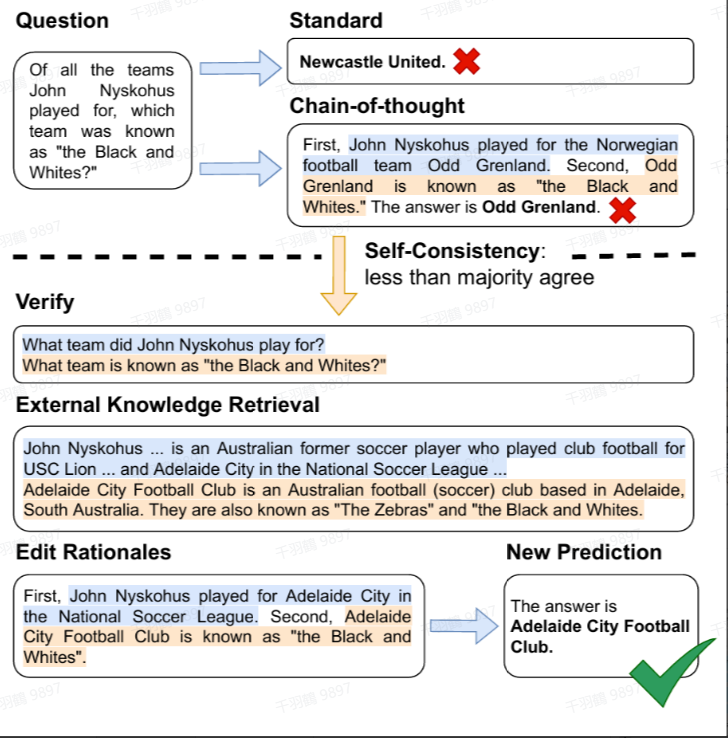
Verify-and-Edit
方法简介
CoT 技术通过生成可解释的推理链来提升复杂推理任务的性能,但在知识密集型任务中,仍然会出现事实性问题。为了解决这一问题,Verify-and-Edit 方法提出了以下改进:
- 生成多条推理链(CoT)。
- 选择一些推理链进行编辑。
- 编辑过程通过对外部信息进行检索,然后允许 LLM(大语言模型)对这些信息进行增强。
流程图
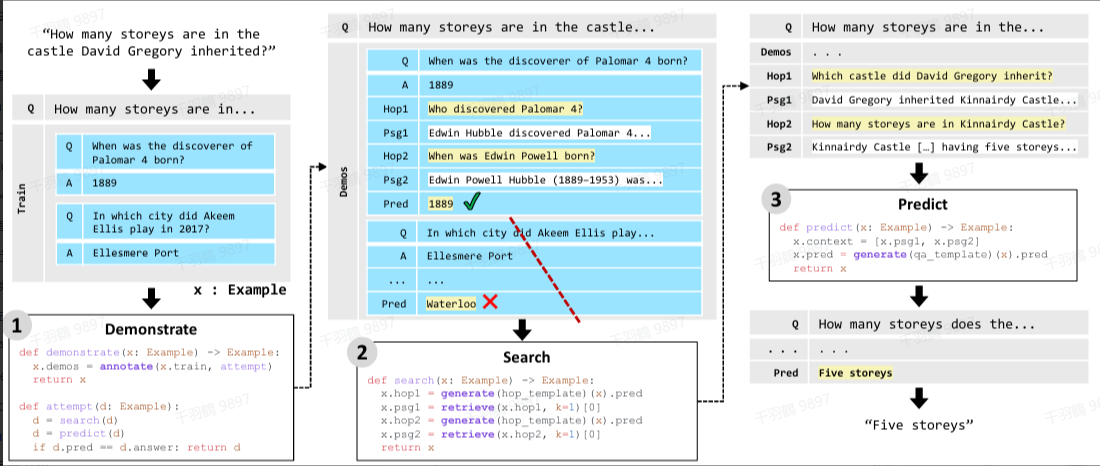
Demonstrate-Search-Predict
方法简介
现有的一些工作简单地将检索模块(RM)嵌入到语言模型(LM)的 prompt 中,但在多跳问题(multi-hop question)中效果并不理想。为了解决这一问题,Demonstrate-Search-Predict 方法采用以下策略:
- 利用少样本学习(few-shot learning)将一个复杂的问题分解为多个子问题。
- 对每个子问题进行回答,并将这些回答组合为最终答案。
示例流程
类似于 Verify-and-Edit 方法,附件中未显示具体流程图,但可以想象这是一个从分解到聚合的过程:问题被拆解为子问题,子问题逐一解决后再合并为完整答案。
Iterative Retrieval Augmentation
方法简介
传统的检索增强语言模型(Retrieval-Augmented LM)存在以下两方面的限制:
- 一次性生成文本在长文本生成任务中容易产生幻觉。
- 使用概括性的主题作为查询(query),导致无法查询到相关细节内容。
为此,FLARE 提出了迭代的检索生成方法:
- 先生成一个临时句子。
- 检查句子中是否包含低可信度的 token。
- 如果存在低可信度 token,则进行检索,并重新生成句子。
- 重复上述步骤,直到完成生成。
示例检索 Query 生成
FLARE 的 Query 生成分为隐式和显式两种方式:
- 隐式 Query:通过 mask 掉临时句子中概率低于阈值的 token 来生成。
- 显式 Query:要求语言模型生成问题,这些问题以临时句子中概率低于阈值的 span 为答案。然后,将这些问题作为 Query 进行检索,并将检索到的文档加入 prompt 中重新生成句子。
流程图
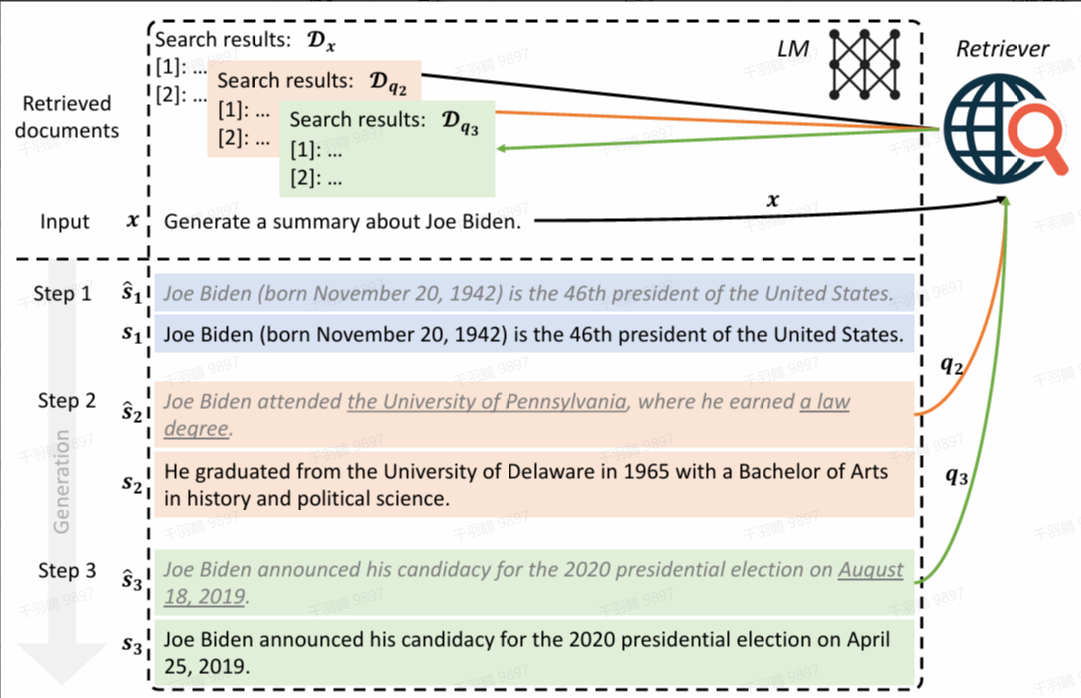
IRP:说明性文本生成任务
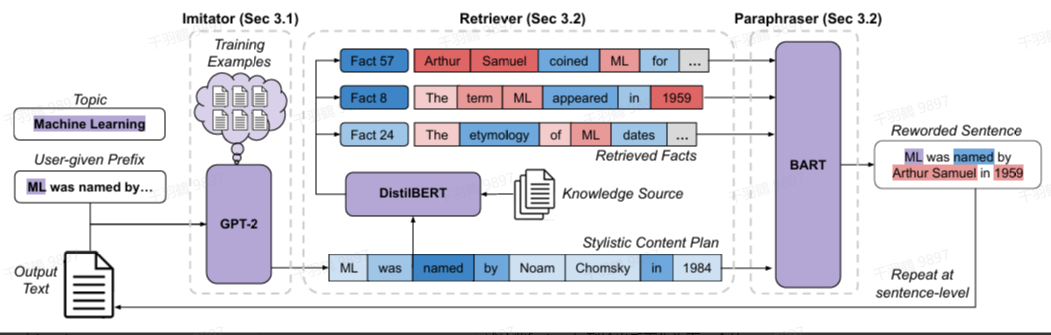
方法简介
IRP(Iterative Retrieval Paraphrasing)是针对说明性文本生成任务提出的一种方法。它包含以下三个组件:
- Imitator:首先生成一个风格化的内容计划(stylistic content plan),概述下一句需要包含的事实。
- Retriever:根据内容计划在语料库中检索相关事实。
- Paraphraser:以内容计划的风格重新表述这些事实,并将其加入输出,作为下一句的前缀。
IRP 是一种逐句生成(sentence-by-sentence generation)的方法。
流程细节
-
Imitator 部分训练
Imitator 使用训练集中说明性文本的专家内容计划(expert content plan)进行训练。 -
Retriever 部分优化
为了减轻幻觉事实对模型检索能力的影响,Retriever 使用 DistilBERT 在训练集上进行分类任务微调。具体来说,模型预测文本中句子的索引位置(即第几个句子)。因为来自不同文本的同一索引位置的句子的事实相关实体通常不同,这种方式降低了模型对事实实体 token 的归因分数。