智能体系统分类
智能体系统分类
从架构上看,Agentic system 可以分为两大类系统:
工作流(Workflow)
工作流是通过预定义代码路径编排 LLM(大型语言模型)和工具的系统,适用于任务明确、步骤可预定义的场景。
自主智能体(Autonomous Agent)
自主智能体是由 LLM 动态控制决策和工具使用,自主规划任务的系统,适用于任务步骤难以预知、需长期自主规划的场景。
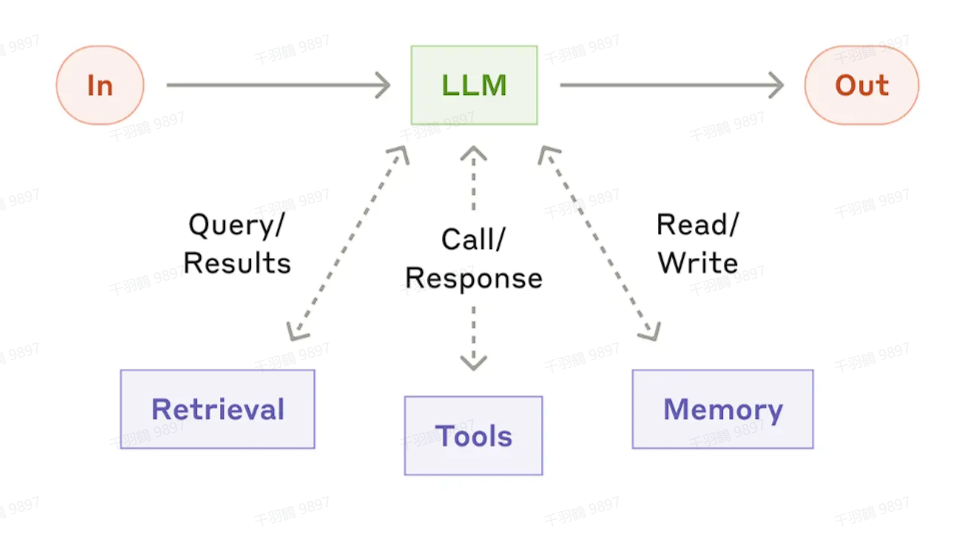
基础构建模块:增强型 LLM
无论是工作流还是自主智能体,其核心基础模块都是增强型 LLM,它们为任务执行提供强大的语言处理能力。
自主智能体(Autonomous Agent)
随着 LLM 在复杂输入理解、规划、工具使用和错误恢复能力上的成熟,自主智能体已经开始在实际生产中得到应用。自主智能体的工作流程可能以用户的一次指令或与用户的互动开始。一旦任务明确,自主智能体会独立规划并执行任务。以下是自主智能体的关键特征:
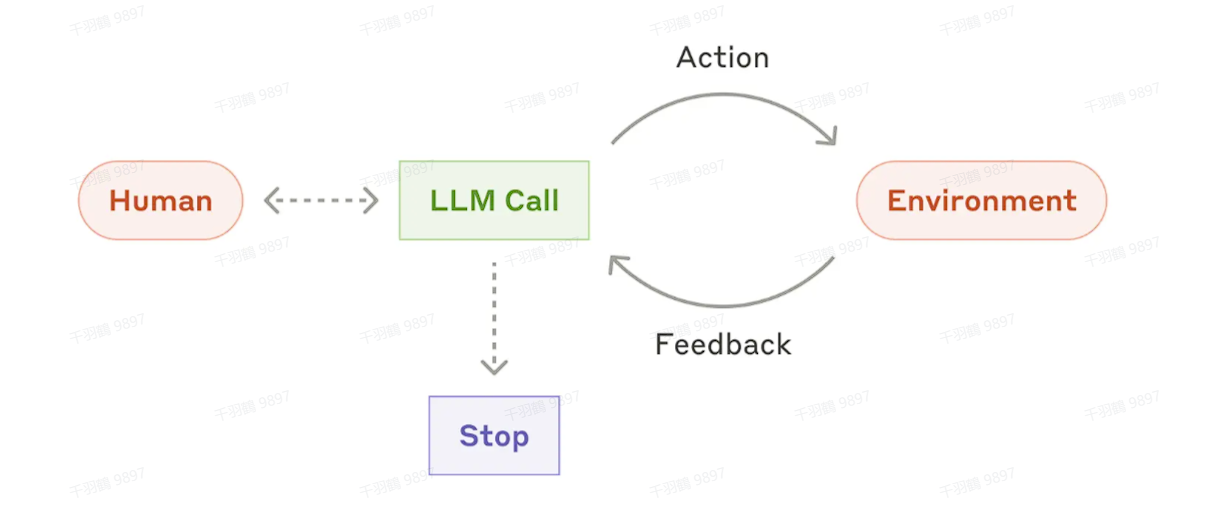
1. 执行过程中获取环境真实反馈
在任务执行过程中,自主智能体需要根据环境中获得的“真实反馈”来评估自身进度。例如,工具调用的结果或代码执行的情况会成为其判断下一步行动的重要依据。
2. 支持人工检查点干预
自主智能体可以在特定检查点或遇到阻碍时暂停执行,等待人类反馈。通过与用户沟通,它能够获取更多信息或进行关键决策。
3. 设置终止条件
自主智能体通常在任务完成时终止,但为了保证正常运行,也可以设置停止条件,例如最大迭代次数
工作流(Workflow)
工作流系统通过将任务分解为预定义的步骤,使得每一步都可以由 LLM 或其他工具依次完成。以下是几种常见的工作流类型及其特点:
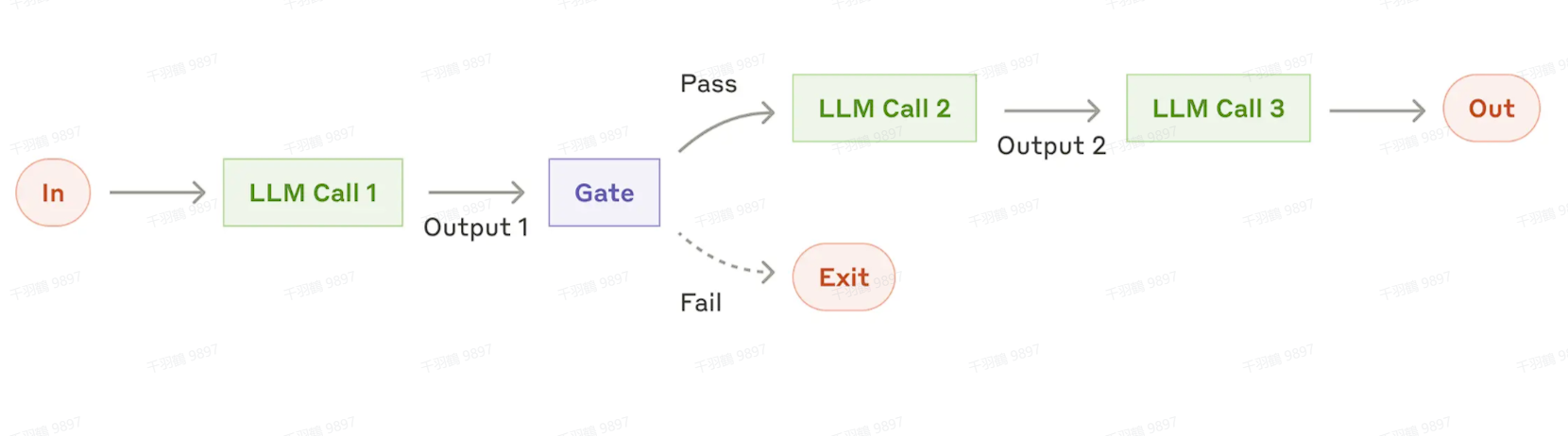
1. 提示链(Prompt Chaining)
定义
Prompt Chaining 是将任务分解为顺序执行的子步骤,每一步都由一个 LLM 调用来处理上一步骤的输出。在任意中间步骤,可以添加程序检查(如“gate”)以确保整个过程按计划执行。
适用场景
当一个任务可以被拆解为顺序执行的子步骤时,提示链是一种有效的工作流方式。它的主要目标是通过简化每次 LLM 调用为一个更容易处理的小任务,从而以牺牲延迟换取更高的准确性。
示例
- 市场营销文案生成:先生成市场营销文案,再将其翻译成另一种语言。
- 文档撰写:编写文档提纲,检验提纲是否符合某些标准,然后根据提纲写出完整文档。
2. 路由(Routing)
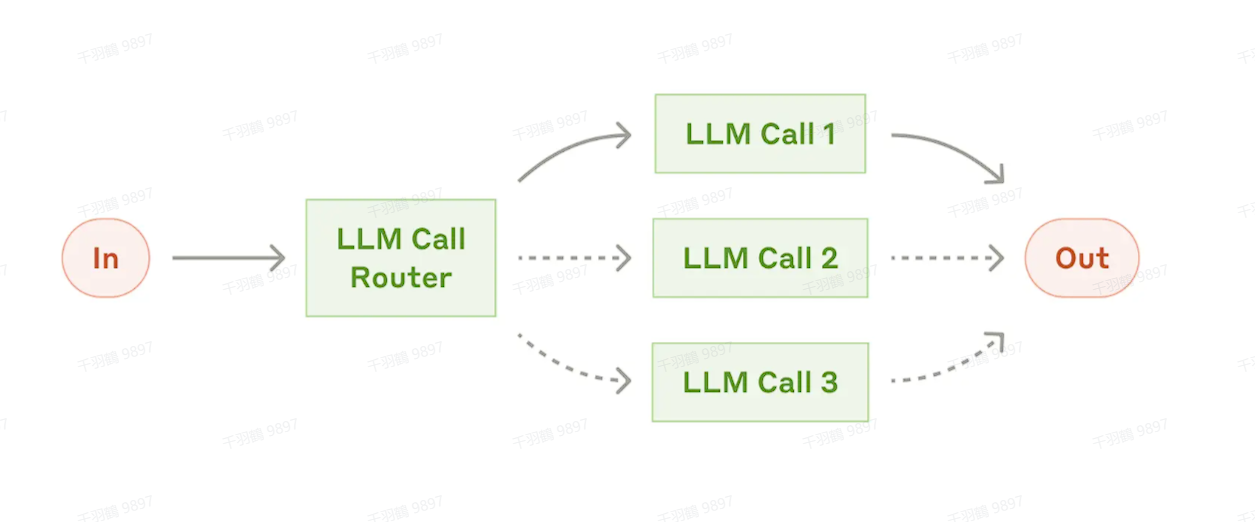
定义
Routing 是对输入进行分类,并将其分配到专门的后续任务中。这种机制能够实现任务分工,并针对不同类型的输入构建更为专门化的提示(prompt)。如果没有路由机制,针对某类输入的优化可能会损害其他输入的性能。
3. 并行化(Parallelization)
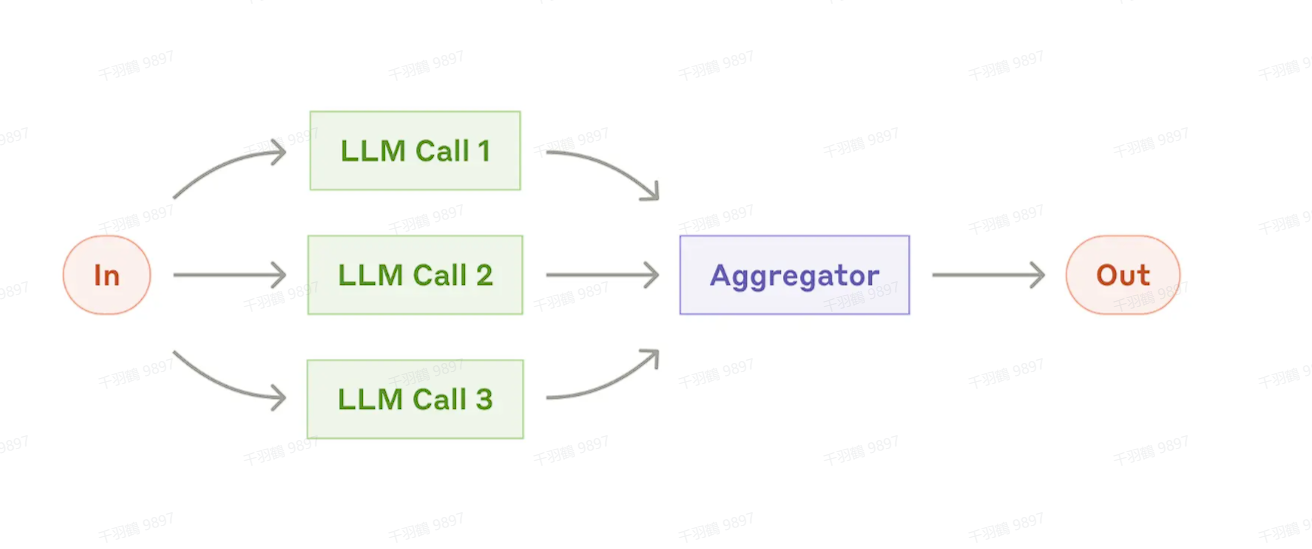
定义
并行化工作流允许 LLM 同时执行多个任务,然后将它们的输出以编程方式聚合在一起。并行化有两个主要变体:
- 分段(Sectioning):将任务划分为可以并行运行的独立子任务。
- 投票(Voting):对同一任务进行多次执行,从而获得多样化的输出,以便进行对比或投票。
适用场景: 当将任务分解后,子任务可以并行执行以提高速度,或者当需要通过多角度、多次尝试来提高结果置信度时,并行化非常有效。对于包含多个考虑因素的复杂任务,当每个因素由独立的 LLM 调用处理时,模型通常能更专注地解决每个问题。 示例: Sectioning : 并行内容审核与主任务处理:一个模型实例负责处理用户查询,另一个模型实例同时对查询进行不恰当内容或非法请求筛查。相比让一个 LLM 同时处理主要回复及安全防护,这种做法表现更优。 自动化多维度模型评估:自动化评估(evals)LLM 的性能,每次调用一个 LLM 来评估模型在某个方面的表现。 Voting : 审查代码是否存在漏洞:多个不同提示审查代码,发现问题时进行标记。 评估某段内容是否不当:多个提示从不同角度评估,或设定不同的投票阈值以平衡误报与漏报。
4. 协调者-工作者 Orchestrator-Workers)
在现代人工智能任务中,复杂任务的拆解与执行是一个重要的研究课题。本文将介绍两种常见的工作流:协调者-工作者 (Orchestrator-Workers) 和 评估-优化循环 (Evaluator-Optimizer),并探讨它们的适用场景与示例。
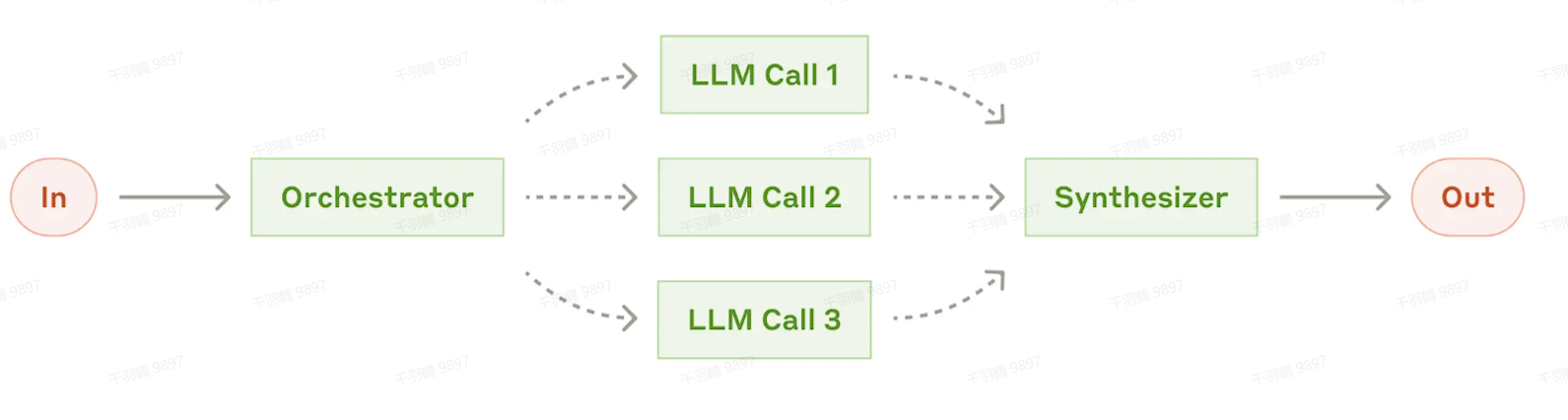
Orchestrator-Workers 工作流
在 Orchestrator-Workers 工作流 中,“协调者” LLM 的核心作用是动态拆解任务,并将这些子任务分配给多个“工作者” LLM 来执行。随后,“协调者”会综合各个工作者的结果,最终完成整个任务。
适用场景
这种工作流非常适合处理子任务不可预知的复杂任务。例如,在编程领域中,每次需要修改的文件数量以及每个文件的修改方式可能因具体任务而异。因此,任务的拆解与分配需要具备高度的灵活性。
与并行化操作相比,Orchestrator-Workers 工作流的关键区别在于灵活性:
- 并行化:子任务是预定义的,固定且可预测。
- Orchestrator-Workers 模式:子任务由中心 LLM 根据输入动态决定。
示例
-
多文件代码修改
在编程产品开发中,可能需要对多个文件进行复杂且不同的改动。例如,一个功能更新可能涉及多处代码修改,而每处修改都需要根据上下文动态决定。这种场景非常适合采用 Orchestrator-Workers 工作流。 -
多源信息搜索分析
当需要在多个信息源中搜索并分析可能相关的信息以完成搜索任务时,Orchestrator-Workers 工作流可以发挥其动态分配和综合结果的优势。例如,研究人员可能需要从不同数据库中提取相关数据,并将最终分析结果整合成一份完整报告。
5. 工作流:评估-优化循环 Evaluator-Optimizer
与 Orchestrator-Workers 工作流不同,Evaluator-Optimizer 工作流 更关注任务的迭代优化。在这一工作流中,一个 LLM 负责生成响应,而另一个 LLM 负责评估该响应并给出反馈。两者通过循环往复的方式不断优化最终结果。
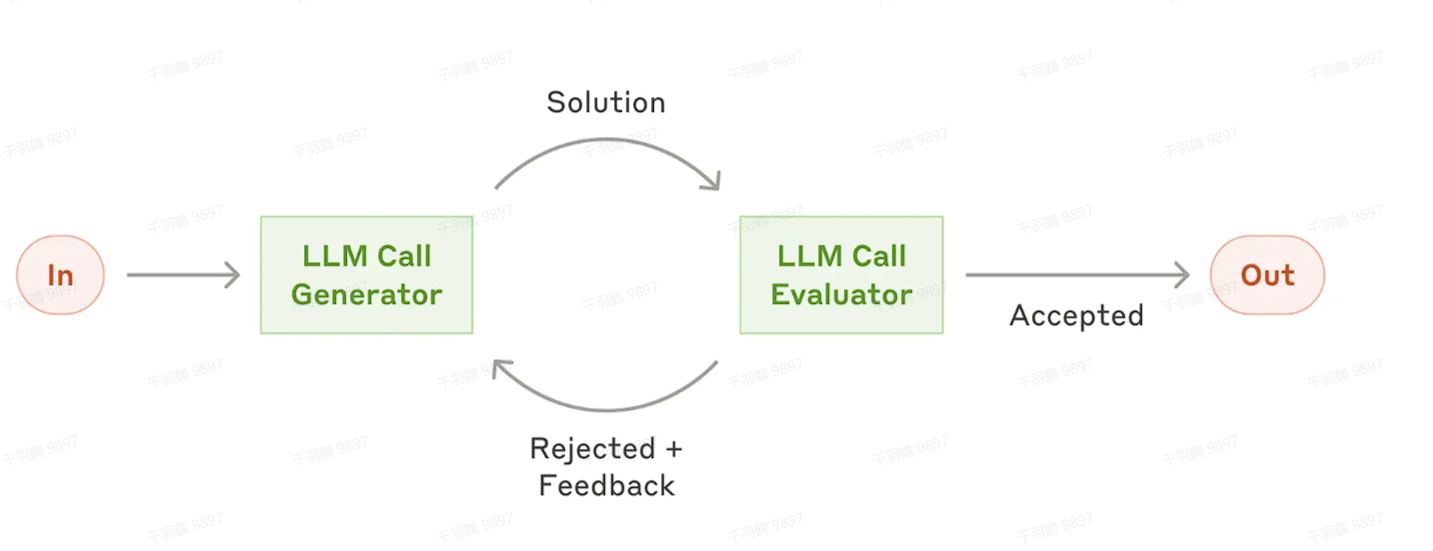
适用场景
Evaluator-Optimizer 工作流适用于以下两种情况:
- 存在明确的评估标准。
- 迭代优化有效。
判断是否适用这一工作流的两个重要标准是:
- 当人类提供反馈时,LLM 的输出能显著改进。
- LLM 自身也具备生成这类反馈的能力。
这种工作流类似于一个人在编写文档时反复修改、润色的过程,通过多次优化达到更高质量的输出。
示例
-
文学翻译润色
文学作品的翻译往往需要对语言细节进行反复推敲。一些细微的语言差异可能在初稿中未被充分体现,而评估者 LLM 可以指出这些不足,并提供改进建议,从而使译文更加贴合原文意境。 -
复杂搜索任务的多轮优化
在某些复杂搜索任务中,为了收集全面的信息,可能需要多轮搜索和分析。评估者 LLM 可以判断当前结果是否足够全面,并决定是否需要进一步搜索,从而不断优化最终输出。
总结
通过本文介绍的两种工作流——Orchestrator-Workers 和 Evaluator-Optimizer,我们可以发现它们分别适用于不同类型的任务:
- 如果任务具有较高的不确定性和动态性,适合采用 Orchestrator-Workers 工作流;
- 如果任务能够通过明确标准进行迭代优化,则更适合采用 Evaluator-Optimizer 工作流。
这两种工作流不仅为人工智能任务提供了高效解决方案,也为复杂问题的分解与优化提供了新的思路。在未来的发展中,它们将进一步推动人工智能在各个领域中的应用与创新。