Prompt Tech 提示技术
In-Context Learning 上下文学习
ICL概念原理
在前面讲GPT系列模型的时候,提到GPT使用的Few-shot Learning,这就属于ICL的一个部分。
In-Context Learning 允许模型在给定的上下文中进行学习和推理,而无需真正更新模型参数。这种方法充分利用了模型的预训练知识,并通过在推理阶段提供相关的上下文信息来生成或调整模型输出。
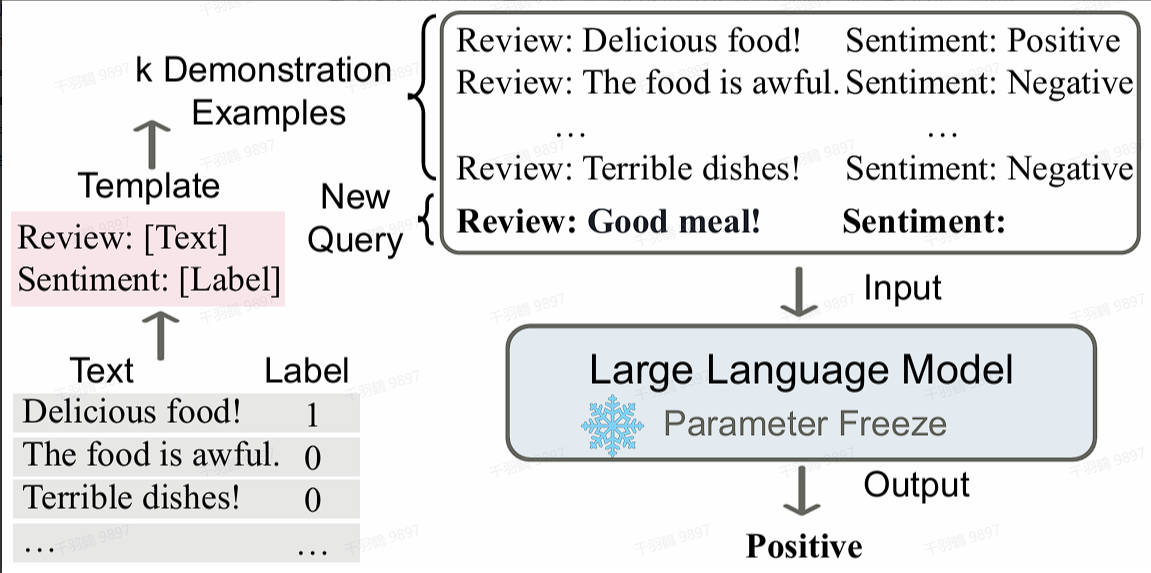
核心概念
上下文依赖
ICL的核心在于利用模型的上下文理解能力来完成任务。模型根据输入的上下文信息(包括示例和任务描述)进行推理,而不是依赖于显式的训练过程。
无参数更新
ICL不涉及对模型实际参数的修改,只是根据提供的上下文信息调整其生成或分类行为。
动态适应
模型在推理时会动态地适应给定的上下文,通过分析上下文中的示例或指示来生成合适的输出。这种适应能力来源于模型在预训练阶段学到的通用知识。
工作原理
提示词和示例
ICL常通过提示词来引导模型的生成过程。提示词通常包括任务描述、问题陈述或请求模型执行的操作。在少样本学习(Few-Shot Learning)中,提示词可能包括一些示例输入和输出,帮助模型理解如何处理类似的任务。
上下文提供
在ICL中,任务描述用于告诉模型要完成的任务,例如:生成一个关于人工智能的总结。提供几个示例输入和输出对,可以帮助模型理解特定任务的模式或要求,例如:给出一些翻译示例来帮助模型进行语言翻译。
推理和生成
模型根据提供的上下文进行推理,生成与上下文相关的响应或输出。在ICL中,生成的文本基于模型对上下文的理解,以及预训练中学到的知识。
ICL形式化定义
ICL可以形式化地定义为:
其中:
是任务定义, 表示示例, 是输入, 是要预测的答案, 是模型生成的预测输出。

ICL示例设计
在自然语言处理(NLP)领域,示例选择(Demonstration Selection)是提升模型性能的重要环节之一。本文将详细介绍几种常见的示例选择方法,包括启发式方法、基于多样性的方法、基于LLM的方法、基于主动学习/强化学习的方法以及基于自生成的方法。
示例选择
启发式方法
基于语义相似度
在基于语义相似度的方法中,我们通常使用BERT类模型作为编码器,提取其CLS embedding的输出向量,作为训练样本的文本表征。通过KNN或欧式距离等算法,选取与当前测试句子(test sentence)语义最近的10个训练样本,作为demonstration。
这种方法的核心在于通过语义相似性度量,找到最接近测试样本的训练样本,从而帮助模型提高对测试样本的预测能力。
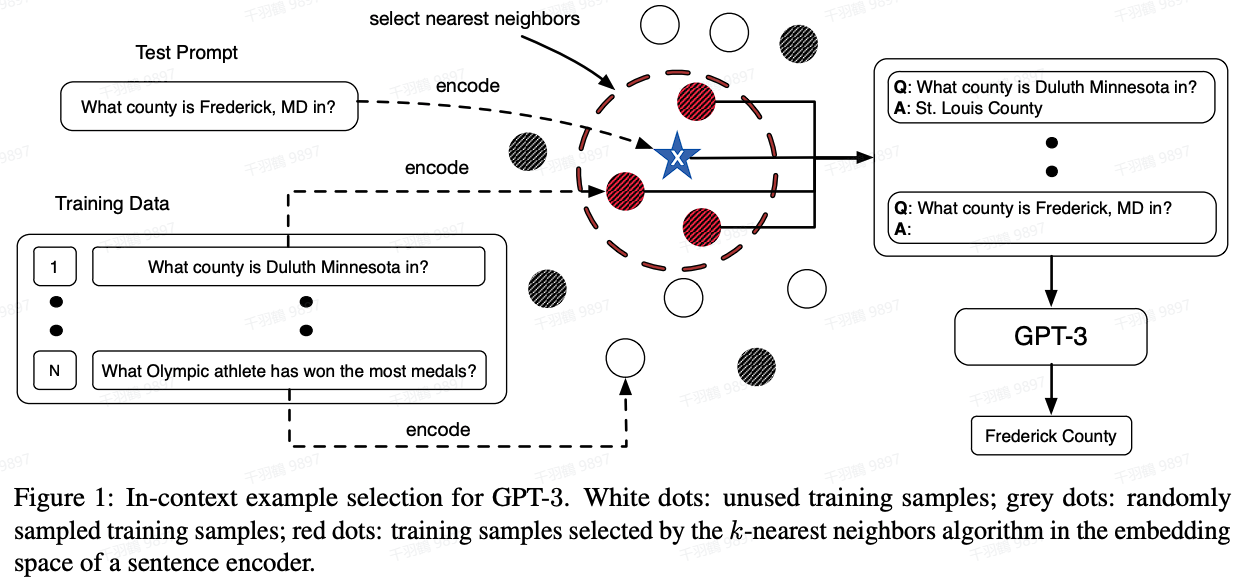
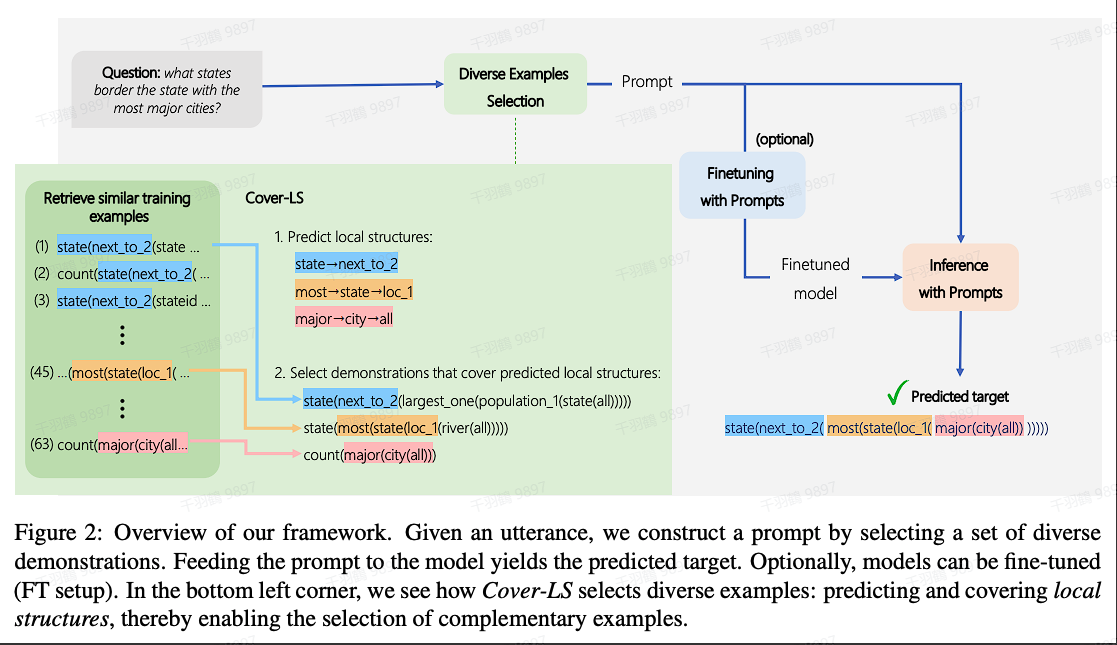
基于多样性
在某些情况下,训练数据和测试数据可能存在较大的分布差异,这使得基于相似度的方法难以挑选出合适的demonstration。此时,可以从多样性的角度出发进行选择。
具体来说,在原有的语义相似度基础上,进一步考虑不同demonstration之间的差异性。如果两个demonstration高度语义相似,则可以剔除其中一个,以确保最终选择的示例具有更高的多样性。
相关研究可以参考论文:
Diverse Demonstrations Improve In-context Compositional Generalization
LLM-based方法
直接用LLM生成Demonstration
此方法直接利用大语言模型(LLM)的生成能力,让其生成合适的demonstration。这种方法依赖于LLMs强大的语言理解和生成能力,可以减少对外部样本库的依赖。
基于Prompt召回
在这种方法中,将训练集中的每一个样本都当作示例,与输入一起输入模型。通过评估模型输出的概率大小来判断当前示例的好坏。为了降低因数据集过大而导致的计算成本,可以利用BM25或SBERT对训练集进行预筛选,召回候选示例集。
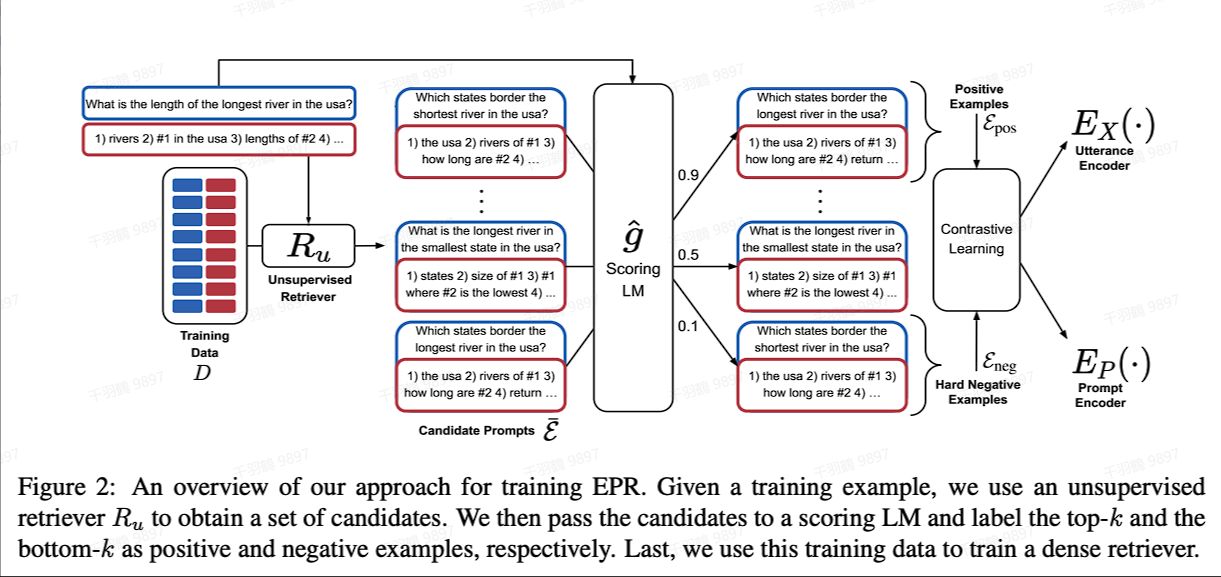

具体步骤如下:
- 召回候选集:利用BM25或SBERT筛选候选示例集。
- 评估示例质量:对候选示例集中的每个示例进行评估,选取最高分的
条作为正例集,最低分 条作为负例集。 - 训练Retriever:使用对比学习的方法,训练一个Retriever,同时生成针对输入编码的Utterance Encoder和针对示例编码的Prompt Encoder。
- 计算相似度:结合Faiss相似度计算框架,找出输入对应最佳的demonstrations。
这种方法通过结合检索和模型评估,有效地提高了示例选择的效率和质量。
基于主动学习/强化学习
主动学习思路
主动学习的目标是从样本库中选择适合的样本提供给标注者标注,而示例选择的问题与其类似。示例选择的目标是从样本库中挑选适合的示例提供给prompt,以提高测试样本的准确率。
强化学习方法
由于demonstrations的可选空间与样本库(通常是训练集)呈指数关系,要枚举所有可能的demonstrations组合几乎不可能。因此,可以将示例选择看作是一个序列决策问题,并基于马尔可夫决策过程(MDP)使用强化学习(RL)的方法进行优化。
具体定义如下:
- State:当前时刻的demonstration,即
。 - Action:样本库中的所有样本以及一个停止信号标识(
)。 - Reward:利用LLMs将state与当前action构成的新demonstrations,在验证集中的准确率。
Prompt由state和action构成的新demonstrations,再加上验证集中的样本输入组成。通过对比验证集标签与LLMs输出结果,可以计算准确率并作为奖励信号。接下来,只需选择一种RL算法即可完成任务。
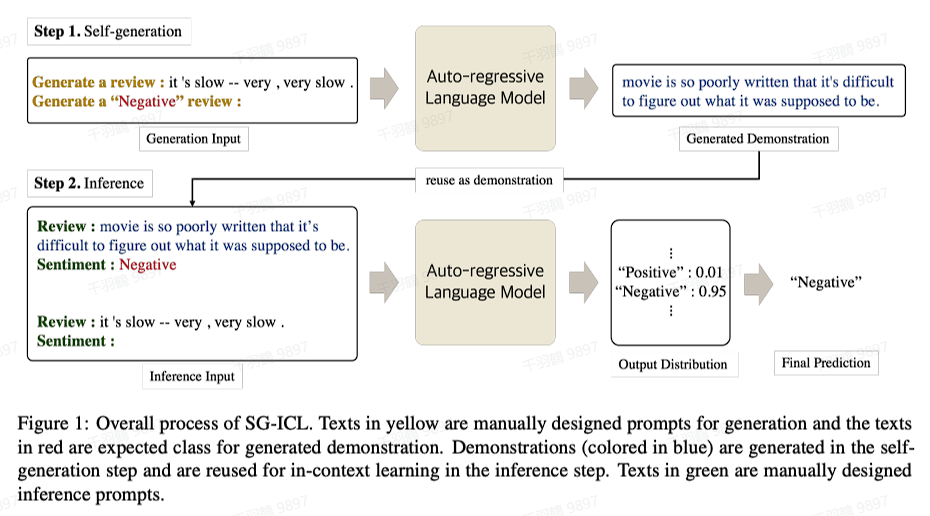
基于自生成的:
- 借助预先设计的prompt,让LLMs生成
个合适的示例。 - 在原输入的基础上,加入第一阶段生成的示例,让LLMs预测最终结果。
这种方法不仅减少了对外部样本库的依赖,还能在一定程度上提高模型的生成效果。
示例格式
在完成demonstrations的选择后,下一步就是将这些demonstrations整合成一个自然语言Prompt。以下是一个具体示例:

Cross-task generalization via natural language crowdsourcing instructions
这篇论文提出了一个新的跨任务instruction数据集。他们使用总包的方式,按照规定的instruction格式,对多个开源数据集进行改造。针对每一个prompt,其格式包含以下几个部分:
-
title
包含一个high-level的任务描述,以及其相关技能,如question generation,answer generation等。 -
prompt
单独的文本命令,一般出现在输入示例之前。 -
definition
指令的补充内容,更加详细地描述指令的具体执行细节。 -
things to avoid
包含模型应该避免的内容或规则。 -
emphasis and caution
警告或反对的内容。 -
positive examples
提供一个类似系统期望的输入、输出例子,使得众包人员更好地理解任务。 -
negative examples
提供一个类似系统期望的输入、输出的负例,让众包人员尽量避免。 -
reason
解释为什么例子是positive或negative。 -
suggestion
包含一些建议,主要用于指导如何将负例改成正例。
通过这种格式化的设计,模型在经过上述instruction数据集微调后,能在unseen样本上达到较好的生成效果。在新样本推断时,将demonstrations加入到task instances中即可。
示例顺序
在整合prompt的时候,各个示例放入的顺序也非常关键。排序的方法多种多样,主要包括以下几种:
-
无需训练的方法
示例顺序可以随机排列或按照固定规则排列,无需额外训练模型。 -
基于距离排序
根据示例与当前输入之间的距离远近进行排序,从而提高模型对当前输入的适配性。 -
基于熵指标重排
通过自定义熵指标对示例进行重排,以优化示例顺序对模型推断结果的影响。
合理选择和组织示例顺序能够显著提升模型推断时的效果和效率。
ICL 的挑战
尽管基于自生成的方法在许多任务中表现良好,但仍然存在一些不可忽视的挑战:
1. 长上下文问题
大规模语言模型对上下文长度有一定限制。如果上下文过长,可能会导致模型在处理时性能下降。因此,在实际操作中需要合理控制上下文长度。
2. 选择适当的上下文
确定哪些信息应该包含在上下文中,以及如何组织这些信息,是ICL(In-Context Learning)的关键挑战之一。上下文设计直接影响到模型生成结果的质量。
3. 输出一致性
在不同上下文中,模型生成的内容可能会有所不同。如何确保生成结果的一致性和准确性,是需要特别关注的问题。
Chain-of-Thought 思维链
CoT 概念原理
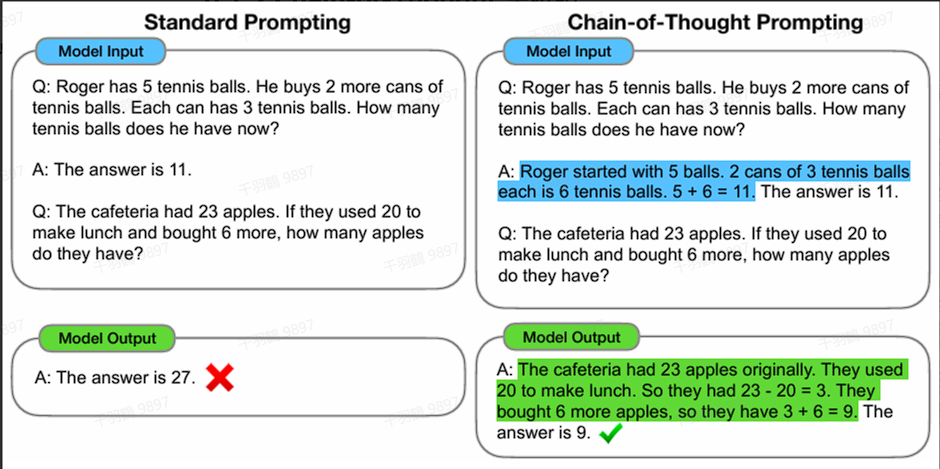
Chain-of-Thought (CoT) 是一种改进的 Prompt 技术,旨在提升大语言模型 (LLMs) 在复杂推理任务上的表现。对于复杂问题,尤其是复杂的数学题,大模型往往难以直接给出正确答案,例如算术推理 (arithmetic reasoning)、常识推理 (commonsense reasoning)、符号推理 (symbolic reasoning) 等。
CoT 通过要求模型在输出最终答案之前,显式输出中间逐步的推理步骤,从而增强大模型的算术、常识和推理能力。这种方法简单但有效。通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解,可以显著提升大模型的性能。
与传统 Prompt 从输入直接映射到输出
CoT 和普通提示的区别
一个完整的包含 CoT 的 Prompt 往往由以下三部分组成:
- 指令 (Instruction):用于描述问题并告知大模型的输出格式。
- 逻辑依据 (Rationale):指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤,以及与问题相关的任何外部知识。
- 示例 (Exemplars):通过少样本的方式为大模型提供输入输出对的基本格式。每一个示例都包含:问题、推理过程与答案。

Zero-Shot-CoT 与 Few-Shot-CoT
根据是否包含示例,可以将 CoT 分为 Zero-Shot-CoT 和 Few-Shot-CoT 两种形式。
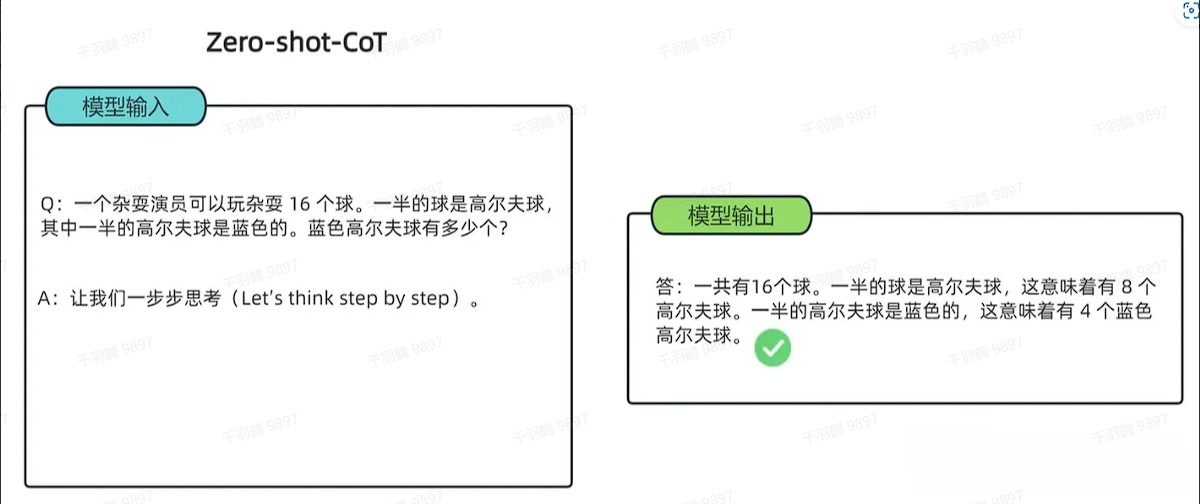
Zero-Shot-CoT
Zero-Shot-CoT 不添加示例,仅在指令中添加一行经典的提示语——“Let’s think step by step”,即可“唤醒”大模型的推理能力。实际上,Zero-Shot-CoT 是一个 pipeline(流水线)。具体过程如下:
- 通过提示语 “Let’s think step by step”,引导 LLM 尽可能生成一些思考过程。
- 将生成的推理过程 (rationale) 和问题 (question) 拼接在一起,再配合一个新的 Prompt,例如 “The answer is”,来激励模型生成答案。
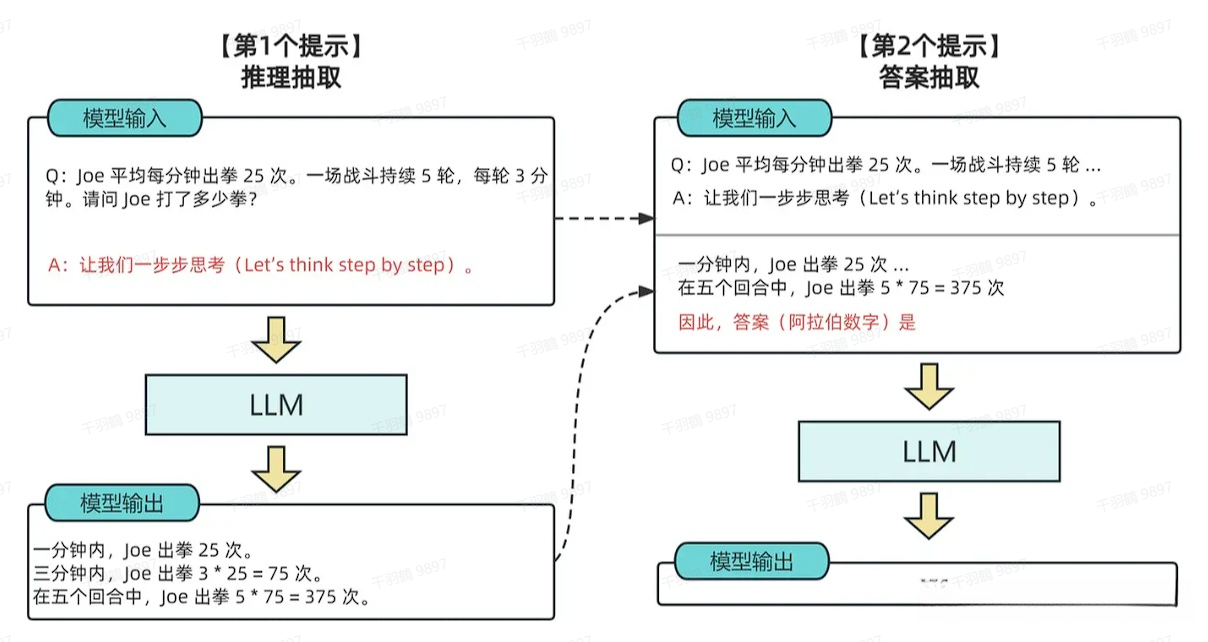
从技术上讲,完整的 Zero-Shot-CoT 过程涉及两个单独的提示/补全步骤:
- 第一个提示生成一个思维链。
- 第二个提示接收第一个提示(包括第一个提示本身)的输出,并从思维链中提取最终答案。
需要注意的是,“Let’s think step by step” 是经过验证有效的提示语,其他类似提示效果通常不如这一句。
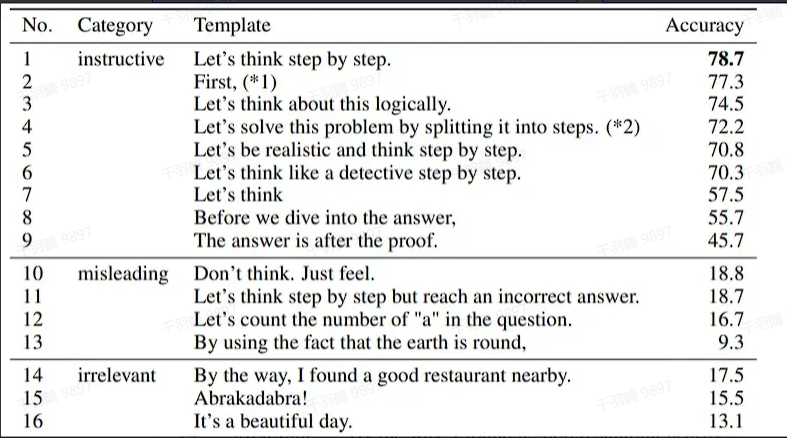
Few-Shot-CoT
Few-Shot-CoT 则在 Prompt 中详细描述了解题步骤,通过提供示例让模型“照猫画虎”地学习推理能力。这种方法通过提供样本问题、对应的推理过程和答案,使得模型能够更好地理解复杂问题的解决路径。
CoT 改进方法
在自然语言处理领域,思维链(Chain-of-Thought, CoT)方法是一种有效提升大语言模型(LLM)推理能力的技术。随着研究的深入,学者们提出了多种针对 CoT 的改进方法,包括 Self Consistency(CoT-SC)、Tree-of-Thoughts(ToT)和 Graph-of-Thoughts(GoT)。本文将详细介绍这些改进方法的核心思想及其实现方式。
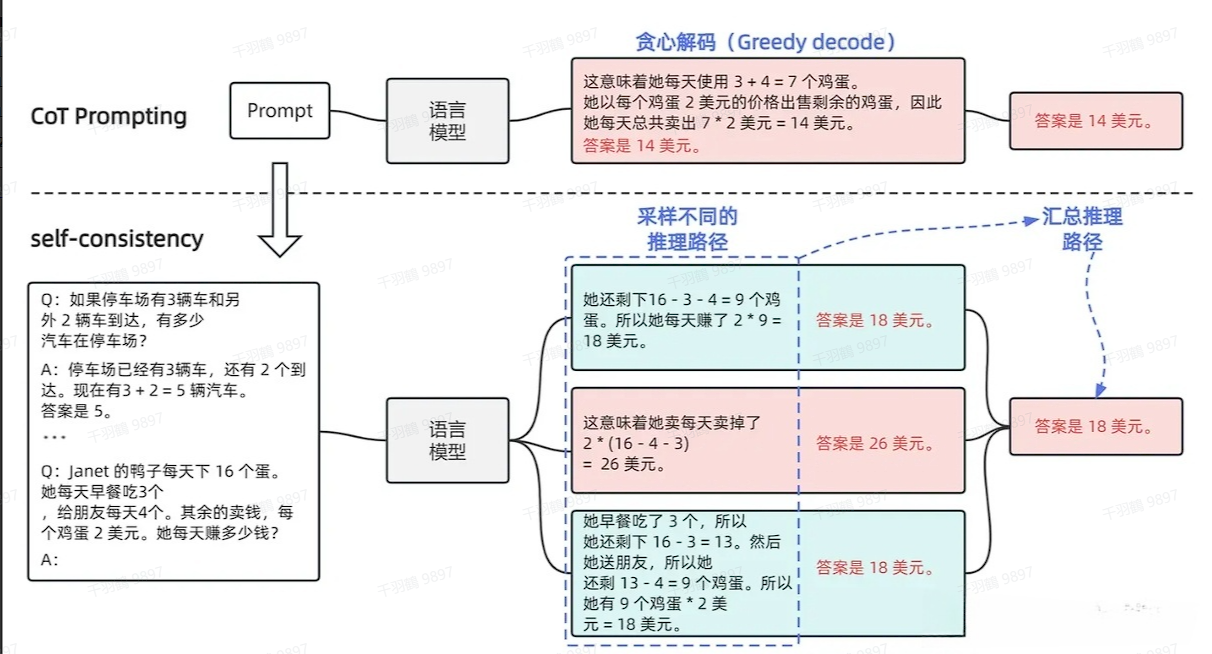
CoT-SC:Self Consistency
CoT-SC 的核心改进在于引入了多数投票(majority vote)机制。具体来说,它通过生成多个思路链,从中提取答案并取多数答案作为最终答案。这种方法显著提高了思维链方法的性能。
在 CoT-SC 中,提示(prompt)依然是使用少样本思维链范例编写的。通过这个提示,独立生成多个思维链,并从每个思维链中提取答案。最终答案的计算过程基于“边缘化推理路径”,即通过统计多个推理路径中最常见的答案来决定最终结果。
这种方法的优势在于,它利用了模型在不同推理路径中的多样性,从而有效地提升了答案的鲁棒性和准确性。
ToT:Tree-of-Thoughts
ToT 方法通过树(tree)的结构来建模 LLM 的推理过程。这种方法允许模型使用不同的思维路径,并引入了一些全新的功能,比如基于不好的结果进行反向回溯推理。
然而,ToT 方法也存在明显的局限性。由于其为思维过程强加了严格的树结构,这种约束会极大限制 prompt 的推理能力。因此,尽管 ToT 提供了一种新的思维建模方式,但其实际应用范围可能受到一定限制。
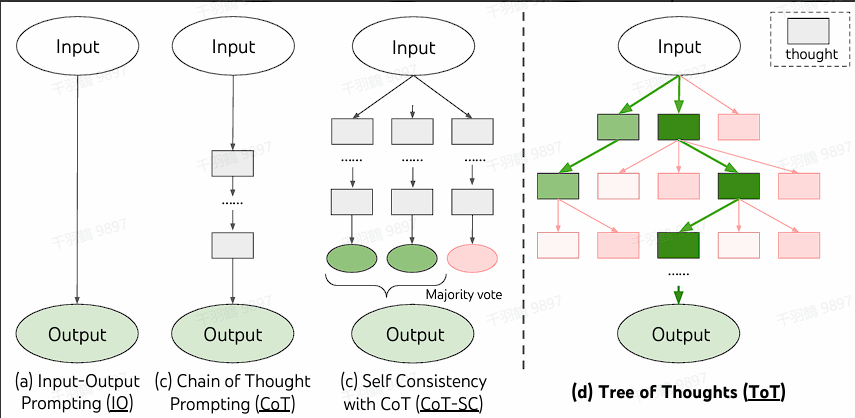
GoT:Graph-of-Thoughts
GoT 方法进一步改进了 ToT 的局限性,通过引入图(graph)的概念,将 LLM 的思维建模为图结构。在 GoT 中,一个 LLM 的思维被建模为一个顶点,而顶点之间的依赖关系则被建模为边。
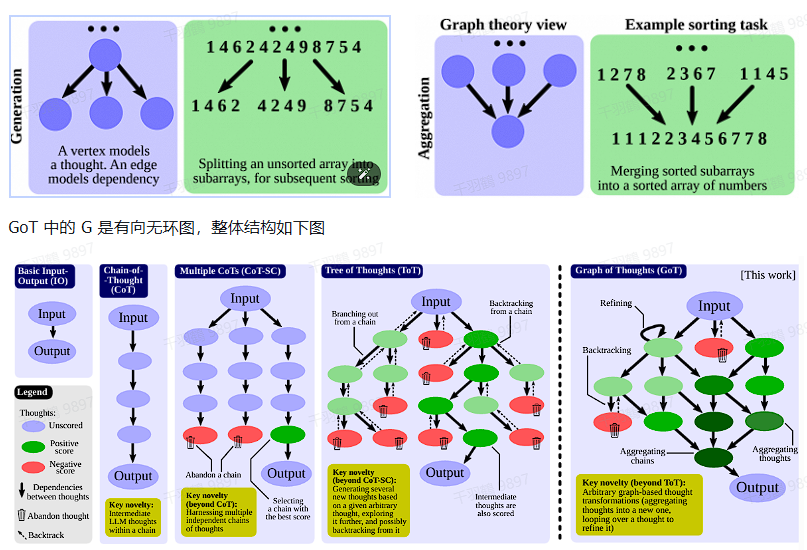
GoT 的核心特点
- 聚合操作:通过构建具有多条输入边的顶点,可以将任意思维聚合起来。这使得 GoT 能够无缝地将 CoT 和 ToT 泛化到更复杂的思维模式,并且无需更新模型。
- 分治思想:相比于 ToT,GoT 增加了聚合操作,能够更灵活地实现分治策略,从而提升推理效率和效果。
GoT 中的图是一个有向无环图(Directed Acyclic Graph, DAG)。其整体结构如下图所示:
注:由于附件不支持打印,图示内容请参考相关资料。
GoT 的模块组成
GoT 的实现由一组交互式模块构成,具体包括以下部分:
- Prompter:负责准备用于 LLM 的消息。
- Parser:解析器,用于提取 LLM 答复中的信息。
- 评分模块:验证 LLM 答复并对其评分。
- Controller:控制器,负责协调整个推理过程,并决定如何推进推理。
Controller 的两个重要组件
-
操作图(GoO):
GoO 是一个静态结构,其指定了对给定任务的图分解。这意味着 GoO 规定了应用于 LLM 思维的变换及其顺序和依赖关系。 -
图推理状态(GRS):
GRS 是一个动态结构,用于维持正在进行的 LLM 推理过程的状态,包括其思维及其状态的历史记录。
