固定长度分块
固定长度分块
最简单直观的文本分块方法
固定长度分块是一种最简单直观的文本分块方法。其核心思想是按照预先设定的固定长度,将文本划分为若干块。这种方法实现起来非常容易,但在实际应用中需要注意以下几个方面的问题和挑战。
问题与挑战
上下文割裂
简单按照固定字符数截断文本,可能会打断句子或段落,导致上下文信息丢失。这种情况下会直接影响后续的文本向量化效果和语义理解。
语义完整性受损
由于文本块可能包含不完整的句子或思想,这会影响检索阶段的匹配精度,同时也会降低大语言模型生成回答的质量。
改进方法
为了解决上述问题,可以采用以下改进方法:
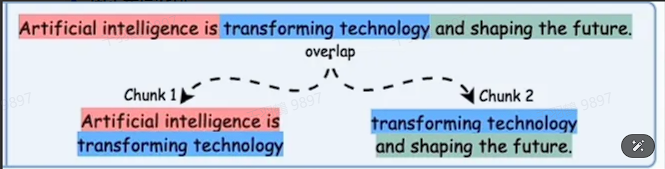
1. 引入重叠
在相邻文本块之间引入一定的重叠部分,确保上下文的连贯性。例如,每个文本块与前一个块有 50 个字符的重叠。这种方式可以帮助保留句子的完整性和段落的连贯性。此外,在问答场景下,如果答案跨越块边界,重叠部分也可能帮助捕获完整答案。
2. 智能截断
在切分文本时,尽量选择在标点符号或段落结束处进行截断,而不是严格按照字符数进行切分。这样可以避免打断句子,从而保持语义的完整。
LangChain 的优化方案
RecursiveCharacterTextSplitter
LangChain 提供了 RecursiveCharacterTextSplitter,优化了固定大小文本切块方法的缺陷,是一种推荐用于通用文本处理的工具。在实践中,固定长度 + 重叠 是一种常用且有效的策略。以下是具体建议:
- 针对中文内容,可以设定每块大约包含 300-500 个字符,重叠 50-100 个字符。
- 这种长度通常足够包含一个完整的细节或论点,同时又不会太长导致嵌入模型难以表示。
- 开发者可以通过调整块大小和重叠长度,在召回粒度(过短的块容易需要多个块才能拼凑完整答案)和检索精准(过长的块可能包含无关信息)之间取得平衡。
使用示例
以下是一个使用 RecursiveCharacterTextSplitter 的代码示例:
# 定义切分参数
chunk_size = 200
chunk_overlap = 50
length_function = len
separators = ["\n", "。", ""]
# 待处理的文本
text = "..."
# 创建文本块
texts = text_splitter.create_documents([text])
# 打印每个文本块
for doc in texts:
print(doc)
参数说明
1. chunk_size
chunk_size 定义了文本块的最大长度。例如,设置为 200 时,每个文本块最多包含 200 个字符。
2. chunk_overlap
chunk_overlap 定义了相邻文本块之间的重叠长度。例如,设置为 50 时,相邻文本块将共享 50 个字符。
3. length_function
length_function 是一个用于计算文本长度的函数,默认值为 len。
4. separators
separators 定义了一组分割符列表,用于在切分文本时优先选择合适的位置。例如,可以设置为 ["\n", "。", ""],表示优先按段落分隔符、句号等位置切分。
工作原理
RecursiveCharacterTextSplitter 的工作原理如下:
-
按照分割符顺序递归切分
- 根据
separators中定义的分割符顺序(如段落、章节分割等),递归地对文本进行切分。
- 根据
-
初步切分
- 使用第一个分割符(如
"\n",表示段落分隔)对文本进行初步切分。
- 使用第一个分割符(如
-
检查块大小
- 如果得到的文本块长度超过了
chunk_size,则使用下一个分割符(如"。", 表示句子分隔)继续切分。
- 如果得到的文本块长度超过了
-
重复递归
- 持续递归,直到所有文本块都满足
chunk_size的限制。
- 持续递归,直到所有文本块都满足
通过这种递归切分方法,可以有效避免语义割裂,同时确保每个文本块的长度适中。
