基于文档结构分块
基于文档结构分块
在处理文档内容时,如何有效地分块是一个重要的问题。特别是在需要将文档输入大语言模型的场景下,合理的分块方式不仅能够提高模型的处理效率,还能更好地保持内容语义的完整性和连贯性。本文将探讨一种基于文档结构分块的方法,并结合递归式分块策略,解决可能出现的问题。
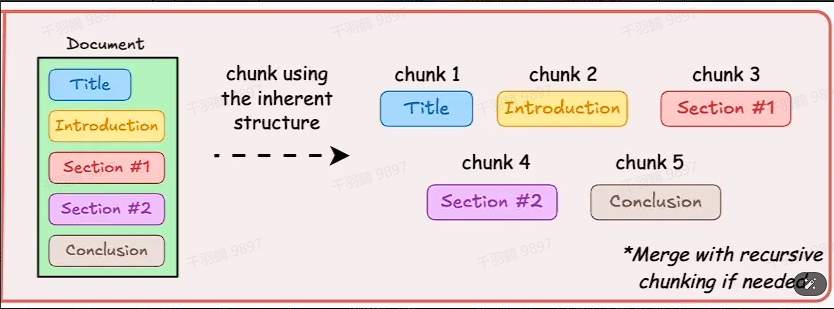

利用文档内部结构进行分块
一种自然且有效的分块方式是利用文档内部已经存在的内在结构,例如标题、章节、段落等。这种方式的优点在于能够保持文档的自然结构,使得分块后的内容更加贴近原文的逻辑。
优点
- 保持文档逻辑:基于标题和章节的分块方式,可以很好地保留原始文档的逻辑顺序。
- 自然语义完整性:每个分块对应一个完整的逻辑单元(如一段话或一个小节),语义上更加连贯。
前提条件
然而,利用文档内部结构进行分块有一个重要的前提:文档本身需要具有清晰的结构。如果文档结构混乱或者没有明确的章节划分,这种方法可能会失效。
不同长度的问题
基于文档结构分块虽然自然,但它可能会导致生成的块(chunk)长度不一致。例如,有些章节可能较长,而另一些章节则较短。在处理长内容时,这种长度的不一致可能带来以下问题:
- 过长的chunk:某些chunk可能超出大语言模型的上下文长度限制。
- 信息丢失风险:为了适配模型上下文长度,需要对过长chunk进行截断或进一步处理。
解决方案:结合递归式分块
针对上述问题,可以引入递归式分块策略。具体来说:
- 初次分块:按照文档的自然结构(如章节、段落等)进行初次分块。
- 递归细化:对于长度超出限制的chunk,进一步递归地将其拆分为更小的部分,直到每个chunk都在模型允许的上下文长度范围内。
递归式分块的方法能够在保持原始结构的基础上,进一步解决chunk长度不均的问题,从而更好地适配大语言模型的输入要求。