基于语义分块
基于语义分块的文本处理方法
什么是基于语义分块?
基于语义分块是一种利用自然语言处理方法,根据语义或句子边界对文本进行切分的技术。这种方法通过在句子结尾或标点处分块,或者通过模型预测段落边界,将文档分段为有意义的单元(如句子、段落或主题部分)。其目标是尽量保证每个分块的语义独立完整。
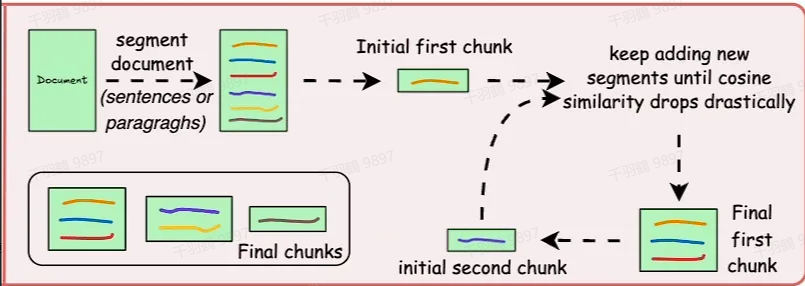

做法
- 语义切分:在句子结尾、标点处或通过模型预测段落边界进行分块。
- 创建 Embedding:为每个分段创建 embedding(嵌入向量)。
- 相似度计算:比较相邻分段的 embedding。如果两个分段的余弦相似度较高,则将它们合并为一个分块。
- 新片段开始:当余弦相似度显著下降时,开始一个新的片段,并重复上述步骤。
优势
- 上下文相关性:每个分块的语义完整性更高,有助于上下文理解。
- 灵活性:适用于不同语言和文本类型。
- 提高检索准确性:内容更丰富,能够帮助语言模型(LLM)生成更连贯、更相关的回应。
局限性
- 复杂性:实现过程较为复杂。
- 处理时间长:由于需要计算余弦相似度和多次迭代,处理速度较慢。
- 计算成本高:需要更多的计算资源。
- 阈值调整:余弦相似度的阈值可能因文档而异,需要手动调整。
NLTK 的文本切分功能
NLTK(Natural Language Toolkit)是一个广泛使用的 Python 自然语言处理库,提供了丰富的文本处理功能。其 sent_tokenize 方法可以自动将文本切分为句子。
原理
sent_tokenize 方法基于论文《Unsupervised Multilingual Sentence Boundary Detection》的研究成果,使用无监督算法为缩写词、搭配词和句子开头的词建立模型,然后利用这些模型识别句子边界。这种方法在多种语言(主要是欧洲语言)上都取得了良好效果。
中文支持现状
- 预训练模型缺失:NLTK 官方并未提供中文分句模型的预训练权重,因此需要用户自行训练。
- 训练接口可用:NLTK 提供了训练接口,用户可以基于自己的中文语料库训练分句模型。
在 LangChain 中的应用
LangChain 集成了 NLTK 的文本切分功能,用户可以直接调用这些功能来实现文本切分。以下是一个示例代码:
使用示例
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
text = "..." # 待处理的文本
texts = text_splitter.split_text(text)
for doc in texts:
print(doc)
扩展:基于 spaCy 的文本切块
spaCy 是另一款强大的自然语言处理库,具备更高级的语言分析能力。LangChain 同样集成了 spaCy 的文本切分方法。
使用方法
只需将 NLTKTextSplitter 替换为 SpacyTextSplitter 即可:
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpacyTextSplitter()
text = "..." # 待处理的文本
texts = text_splitter.split_text(text)
for doc in texts:
print(doc)
提示
使用 spaCy 时,需要先下载对应语言的模型。例如,对于中文处理,可以下载 spaCy 的中文语言模型。