Knowledge Distillation 知识蒸馏
知识蒸馏简介
知识蒸馏(Knowledge Distillation, KD)是一种旨在将知识从大型复杂模型(即教师模型)转移到较小简单模型(即学生模型)的技术。根据教师模型的开放性程度,知识蒸馏可以分为以下两类:
- Blackbox知识蒸馏:通常只能访问教师模型的输出,这些教师模型一般来自闭源的大语言模型。
- Whitebox知识蒸馏:在这种情况下,可以获取教师模型的参数或输出分布,教师模型通常来自开源的大语言模型。
知识蒸馏的基本组成部分
知识蒸馏算法由以下三部分组成:
- 知识(Knowledge):表示从教师模型中提取的内容。
- 蒸馏算法(Distillation Algorithm):用于实现知识转移的具体方法。
- 师生架构(Teacher-Student Architecture):描述教师模型与学生模型之间的关系及其结构。
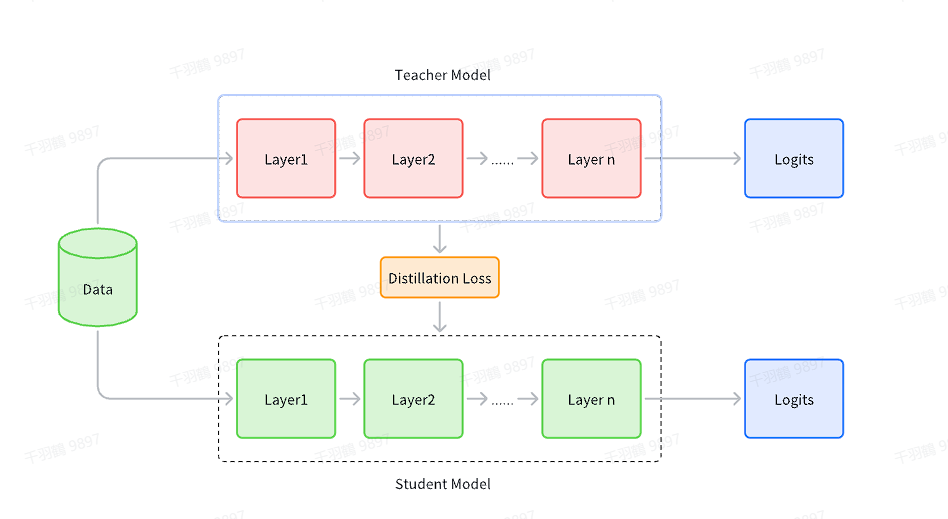
一般的师生架构如下图所示:
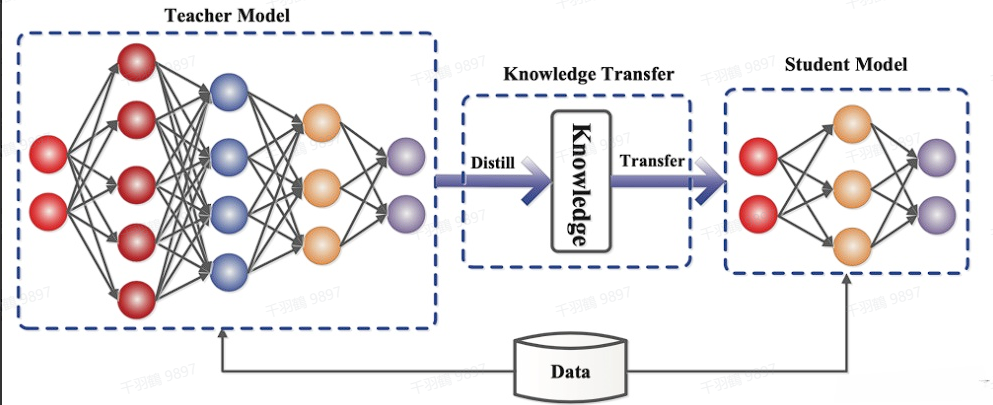
通常情况下,教师网络会比学生网络大,通过知识蒸馏的方法将教师网络的知识转移到学生网络。因此,蒸馏学习可以用于压缩模型,将大模型变成小模型。需要注意的是,知识蒸馏的过程需要数据集,这个数据集可以是用于教师模型预训练的数据集,也可以是额外的数据集。
白盒知识蒸馏
知识蒸馏是一种重要的模型压缩方法,其核心思想是通过教师模型(Teacher Model)向学生模型(Student Model)传递知识,以便在保持模型性能的同时减少模型的参数量和计算复杂度。在知识蒸馏领域,白盒知识蒸馏和黑盒知识蒸馏是两个主要研究方向。
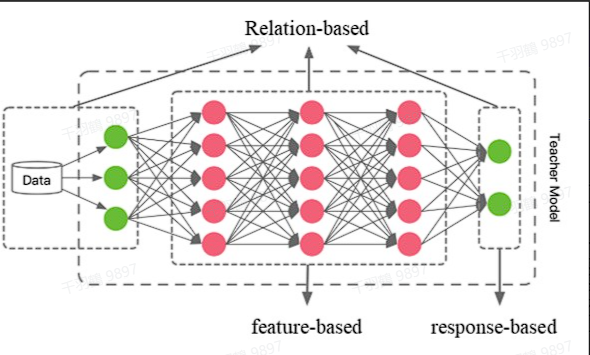
知识的类型
白盒知识蒸馏中,知识的类型主要分为三种:Response-based、Feature-based 和 Relation-based。这三种类型各有特点,适用于不同的场景和需求。
1. Response-based
在 Response-based 知识蒸馏中,学生模型直接学习教师模型输出层的特征。通俗地说,教师模型在充分学习后,直接将结论告诉学生模型。这种方法的特点是学习目标非常明确,学生模型只需模仿教师模型的最终预测结果即可。
2. Feature-based
相比于 Response-based 方法直接学习教师模型的输出结果,Feature-based 方法进一步挖掘深度神经网络中不同层级的特征信息。它将教师模型中间层的特征激活作为学生模型的学习目标,从而对 Response-based 知识形成补充。
虽然基于特征的知识转移为学生模型提供了更多信息,但它也带来了新的挑战:
- 教师模型和学生模型的结构可能不同,如何选择教师模型中的哪一层特征激活(提示层)以及学生模型中的哪一层(引导层)进行模仿,是一个需要深入研究的问题。
- 当提示层和引导层的大小存在差异时,如何正确匹配教师与学生的特征表示也是一个尚未完全解决的难题。
目前,对于这些问题,还没有成熟统一的解决方案。
3. Relation-based
与前两种方法不同,Relation-based 方法不仅关注教师模型中特定网络层的特征输出,还进一步探索了各网络层输出之间的关系或样本之间的关系。例如:
- 使用教师模型中两层 feature maps 之间的 Gram 矩阵作为知识,这反映了网络层输出之间的关系。
- 利用样本在教师模型上的特征表示的概率分布,捕捉样本之间的关系。
这种基于关系的方法能够更全面地传递教师模型中蕴含的信息,但其实现和优化也存在一定难度。
蒸馏的方法
在白盒知识蒸馏中,常见的蒸馏方法可以分为三类:Offline distillation、Online distillation 和 Self-distillation。
1. Offline distillation
Offline distillation 是大多数知识蒸馏算法采用的方法,其过程主要包括两个步骤:
- 教师模型预训练:首先对教师模型进行充分训练,使其具备较高的精度和性能。
- 蒸馏算法迁移知识:将教师模型中的知识迁移到学生模型中。
这种方法通常侧重于知识迁移部分,教师模型通常参数量大且训练时间较长。例如,大型预训练语言模型 BERT 通过这种方式可以生成更小、更高效的模型,如 tinyBERT。
2. Online distillation
与 Offline distillation 不同,Online distillation 要求教师模型和学生模型同时更新。这种方法主要适用于以下场景:
- 教师模型参数量大且精度性能高,但无法直接获得。
- 在线环境下需要动态更新模型。
然而,由于在线环境下难以获得参数量大且精度性能高的教师模型,这种方法在实际应用中面临一定限制。
3. Self-distillation
Self-distillation 是 Online distillation 的一种特例。在这种方法中,教师模型和学生模型采用相同的网络结构。通过这种方式,学生模型在学习过程中能够更好地模仿教师模型,从而实现性能提升。
黑盒知识蒸馏
白盒知识蒸馏与黑盒知识蒸馏的区别
白盒知识蒸馏(也叫标准KD)旨在让学生模型学习大语言模型(LLM)所用的常见知识,例如输出分布和特征信息。而黑盒知识蒸馏则有所不同,它通常促使教师大语言模型生成一个蒸馏数据集,利用该数据集微调学生语言模型,从而将能力从教师大语言模型转移到学生语言模型。
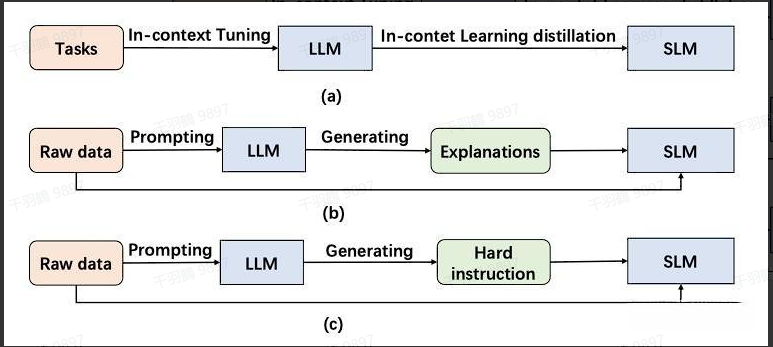
特别地,对于LLM来说,知识转移还涵盖了蒸馏它们独特的涌现能力(Emergent Abilities),因此黑盒知识蒸馏又被称为 Emergent Abilities-based KD。这种方法主要包括以下三种蒸馏方式:ICL、CoT 和 Instruction Following。
ICL:上下文少样本学习蒸馏
ICL(In-Context Learning)采用结构化的自然语言提示(prompt),其中包含任务描述和一些示例。通过这些任务示例,LLM可以在不需要显式梯度更新的情况下掌握和执行新任务。
ICL 蒸馏的核心目标是将 LLM 的上下文少样本学习能力和语言建模能力转移到学生模型中。这种方法将上下文学习目标与传统的语言建模目标相结合,并在少样本学习范式下进行 ICL 蒸馏。
CoT:中间推理步骤蒸馏
CoT(Chain of Thought)与 ICL 相比,在提示中加入了中间推理步骤。这些步骤不仅能够影响最终的输出,还能提升模型的推理能力,而不仅仅是简单的输入-输出对。
一些基于 CoT 的蒸馏工作包括:
-
MT-COT
MT-COT 利用 LLM 生成的解释来增强较小推理器的训练。通过多任务学习框架,较小的模型不仅具备强大的推理能力,还能够生成解释。 -
Fine-tune-CoT
Fine-tune-CoT 通过随机采样从 LLM 生成多个推理解决方案。这种训练数据的增加有助于学生模型的学习过程。 -
SOCRATIC CoT
SOCRATIC CoT 训练了两个蒸馏模型:问题分解器和子问题解决器。其中,分解器将原始问题分解为一系列子问题,而子问题解决器则负责解决这些子问题。 -
DISCO
DISCO 引入了一种基于 LLM 的完全自动反事实知识蒸馏方法。它通过工程化提示生成短语扰动,然后通过任务特定的教师模型将这些扰动数据过滤,以提取高质量的反事实数据。 -
SCOTT
SCOTT 采用对比解码,将每个原理与答案联系起来,鼓励学生模型从教师模型中提取相关的原理。
IF:基于指令跟随的蒸馏
IF(Instruction Following)与 ICL 不同,它仅依赖于任务描述,而不依赖于少量示例。通过使用一系列以指令形式表达的任务进行微调,语言模型展现出能够准确执行以前未见过的指令描述任务的能力。
这种方法充分利用了 LLM 的适应性来提升学生模型的性能。具体来说,它促使 LLM 识别和生成“困难”的指令,然后利用这些指令来增强学生模型的能力。