FlashAttention Forword流程
FlashAttention Forward流程
在这篇博客文章中,我们将深入探讨FlashAttention的前向流程,尤其是其独特的分块计算方法。FlashAttention通过引入额外的统计量,解决了注意力计算中Softmax分块计算的难题,并通过kernel融合优化了计算效率。
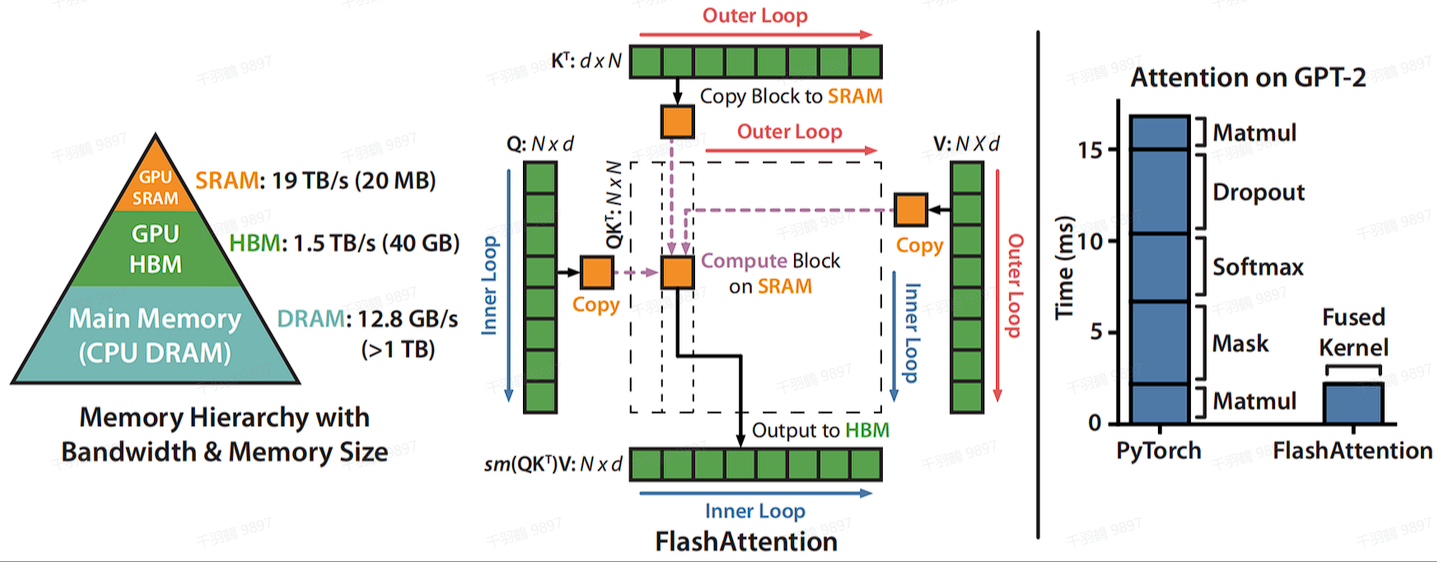
Tiling 分块计算
SRAM的读写速度比HBM高一个数量级,但内存小很多。通过kernel融合的方式,将多个操作融合为一个操作,利用高速的SRAM进行计算,可以减少读写HBM的次数,从而有效减少内存受限操作的运行时间。但SRAM的内存大小有限,不可能一次性计算完整的注意力,因此必须进行分块计算,使得分块计算需要的内存不超过SRAM的大小。
分块计算的难点
注意力计算流程是矩阵乘法
FlashAttention的做法
引入额外的统计量
为了实现Softmax分块计算,FlashAttention引入了额外的统计量
公式说明
通过保持额外的两个统计量可以实现Softmax的分块计算,同时注意,多个block的Softmax,GPU是可以做并行计算的,这也提升了计算效率。
Kernel融合
在FlashAttention中,通过kernel融合,将mask和dropout加上的forward过程整合为一个操作:
Tiling分块计算使得可以用一个CUDA kernel来执行注意力的所有操作,从HBM中加载输入数据,在SRAM中执行所有的计算操作(矩阵乘法,mask,softmax,dropout,矩阵乘法),再将计算结果写回到HBM中,通过kernel融合将多个操作融合为一个操作,避免了反复地从HBM中读写数据。
一个分块计算Softmax的例子
为了更好地理解分块计算Softmax,我们来看一个简单的例子:对向量
计算block1:
计算block2:
类似的方法可以用于计算第二个block。
通过这些步骤,我们可以有效地进行分块计算Softmax,从而提升计算效率。
Forward具体流程
Flash Attention 具体做法
首先,将
然后,将
同样,将
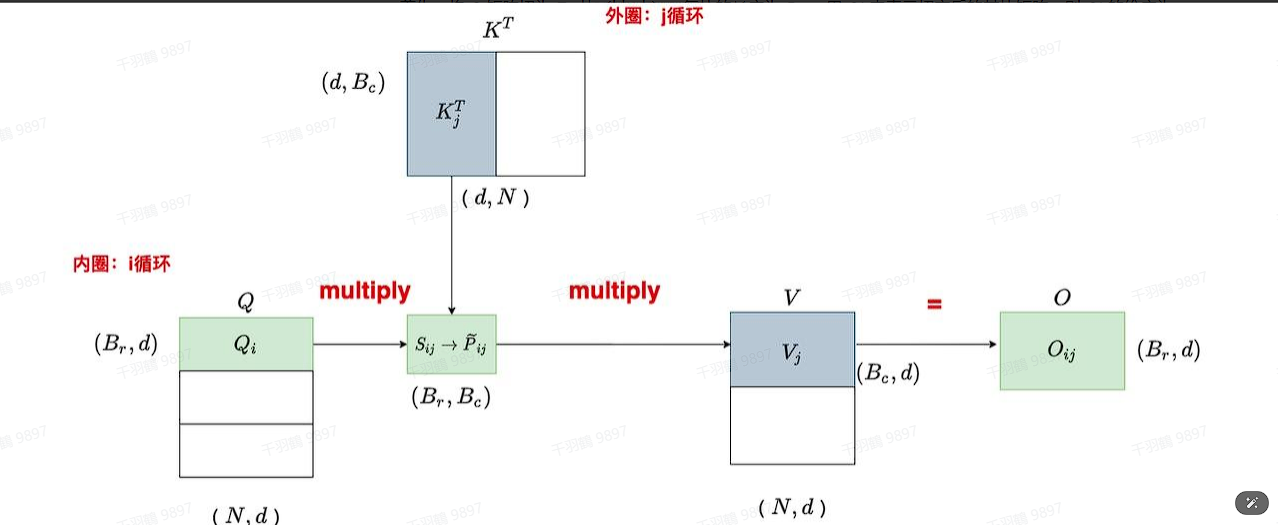
计算初始attention分数
图中的
afe softmax + mask + dropout
对
计算output
细心的你肯定又发现了,这个等式不太对劲,这个
计算的伪代码
# 代码块
# ---------------------
# Tc: K和V的分块数
# Tr: Q的分块数量
# ---------------------
for 1 <= j <= Tc:
for 1 <= i <= Tr:
do....
图例加深理解
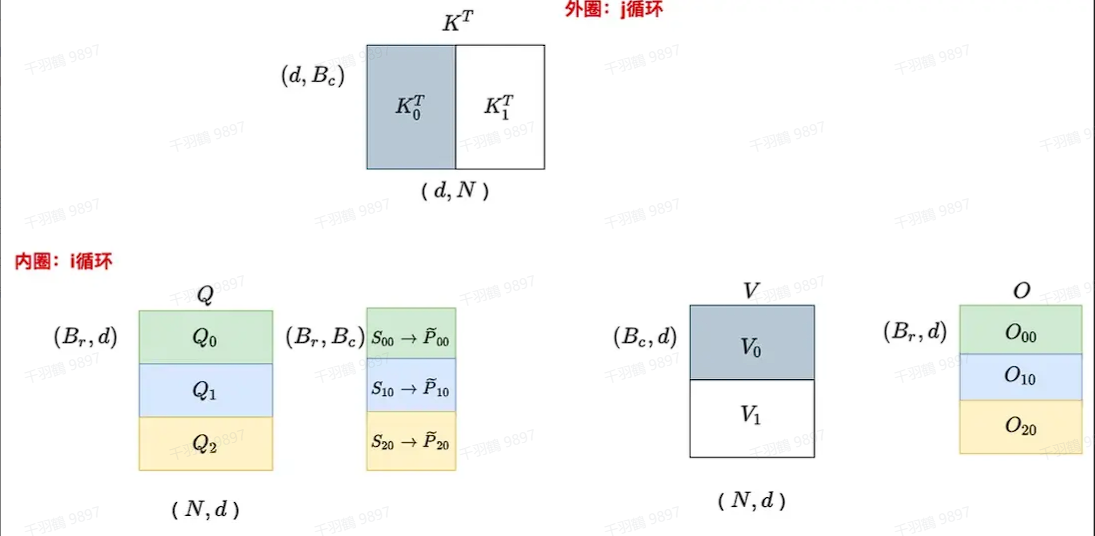
下面给出具体的图例加深理解(假设
当 j=1 时
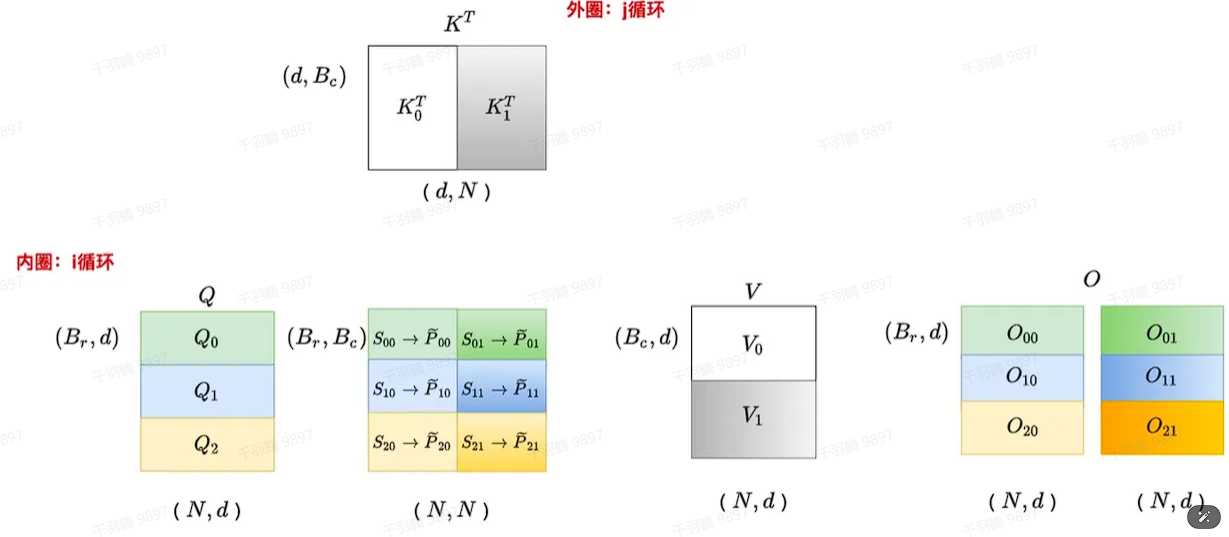
当 j=2 时
Tilling 中的 Safe Softmax
探讨 Tilling 中的 Safe Softmax 的概念及其计算方法。我们假设标准场景下,矩阵某一行的向量为
因为分块的原因,它被我们切成了两部分
我们定义:
在分块计算的过程中,我们将输出定义为
思路转变:
为了解决这个问题,我们需要换个思路。即使我们没有每块的
更新公式:
对于每一块,我们可以通过以下公式进行更新:
其中,
进一步简化为:
最终我们得到:
经过多次迭代更新后,我们可以表示为:
最终,我们得到完整的更新公式:
通过这样的更新方法,我们能够确保在遍历完所有块后,得到的结果与标准场景下完全一致。
Forward计算代码解析
在深度学习中,计算效率和模型性能是两个重要的考量因素。本文将详细解析一个用于前向传播(Forward Pass)的计算代码,帮助读者理解其内在逻辑和操作步骤。
import torch
NEG_INF = -1e10 # -infinity
EPSILON = 1e-10
Q_LEN = 6
K_LEN = 6
Q_BLOCK_SIZE = 3
KV_BLOCK_SIZE = 3
P_DROP = 0.2
Tr = Q_LEN // Q_BLOCK_SIZE
Tc = K_LEN // KV_BLOCK_SIZE
Q = torch.randn(1, 1, Q_LEN, 4, requires_grad=True).to(device='cpu')
K = torch.randn(1, 1, K_LEN, 4, requires_grad=True).to(device='cpu')
V = torch.randn(1, 1, K_LEN, 4, requires_grad=True).to(device='cpu')
O = torch.zeros_like(Q, requires_grad=True)
l = torch.zeros(Q.shape[:-1])[..., None]
m = torch.ones(Q.shape[:-1])[..., None] * NEG_INF
# step 4
Q_BLOCKS = torch.split(Q, Q_BLOCK_SIZE, dim=2)
K_BLOCKS = torch.split(K, KV_BLOCK_SIZE, dim=2)
V_BLOCKS = torch.split(V, KV_BLOCK_SIZE, dim=2)
# step 5
O_BLOCKS = list(torch.split(O, Q_BLOCK_SIZE, dim=2))
l_BLOCKS = list(torch.split(l, Q_BLOCK_SIZE, dim=2))
m_BLOCKS = list(torch.split(m, Q_BLOCK_SIZE, dim=2))
# step 6
for j in range(Tc):
# step 7
Kj = K_BLOCKS[j]
Vj = V_BLOCKS[j]
# step 8
for i in range(Tr):
# step 9
Qi = Q_BLOCKS[i]
Oi = O_BLOCKS[i]
li = l_BLOCKS[i]
mi = m_BLOCKS[i]
# step 10
S_ij = torch.einsum('... i d, ... j d -> ... i j', Qi, Kj)
# step 11
mask = S_ij.ge(0.5)
S_ij = torch.masked_fill(S_ij, mask, value=0)
# step 12
m_block_ij, _ = torch.max(S_ij, dim=-1, keepdims=True)
P_ij = torch.exp(S_ij - m_block_ij)
l = torch.cat(l_BLOCKS, dim=2)
m = torch.cat(m_BLOCKS, dim=2)
数据块的拆分
首先,我们需要将输入的数据张量
O_BLOCKS = list(torch.split(O, Q_BLOCK_SIZE, dim=2))
l_BLOCKS = list(torch.split(l, Q_BLOCK_SIZE, dim=2))
m_BLOCKS = list(torch.split(m, Q_BLOCK_SIZE, dim=2))
循环计算过程
Step 6: 外层循环
我们开始遍历
for j in range(Tc):
Kj = K_BLOCKS[j]
Vj = V_BLOCKS[j]
Step 8: 内层循环
在内层循环中,我们遍历
for i in range(Tr):
Qi = Q_BLOCKS[i]
Oi = O_BLOCKS[i]
li = l_BLOCKS[i]
mi = m_BLOCKS[i]
Step 10: 相似度计算
通过爱因斯坦求和约定计算相似度矩阵
Step 11: 掩码处理
将
mask = S_ij.ge(0.5)
S_ij = torch.masked_fill(S_ij, mask, value=0)
Step 12: 权重计算
通过最大值归一化和指数函数计算权重矩阵
Step 13: 更新最大值和权重
更新
Step 14: Dropout操作
对
m = torch.nn.Dropout(p=P_DROP)
P_ij_Vj = m(P_ij_Vj)
Step 15: 更新输出块
更新输出块
并打印调试信息:
print(f'-----------Attention : Q {i} xK {j} ---------')
print(O_BLOCKS[i].shape)
print(O_BLOCKS[0])
print(O_BLOCKS[1])
print('\n')
Step 16: 更新块信息
将更新后的
l_BLOCKS[i] = li_new
m_BLOCKS[i] = mi_new
拼接结果
最后,将所有块拼接回完整的张量:
O = torch.cat(O_BLOCKS, dim=2)
l = torch.cat(l_BLOCKS, dim=2)
m = torch.cat(m_BLOCKS, dim=2)
计算量和显存
FlashAttention 计算流程
计算量
在算法第9行,我们有
其中
根据前置知识,求
的计算量为
在算法第12行,我们有
其中
则这里的计算量同样为
接下来我们看一共计算了多少次(1)和(2),也就是执行了多少次内循环:
综合以上三点,flash attention的forward计算量为:
同理大家可以自行推一下backward中的计算量,在论文里给出的结论是
,
显存
和标准attention相比,如果不考虑
。而标准attention需要存储
。可以发现相比于标准attention,flash attention明显降低了对显存的需求。
IO复杂度
我们来看伪代码的第六行,在每个外循环中,我们都会加载
因此这里的IO复杂度为:
再看伪代码第8行,在每个内循环中,我们都加载了部分
),因此我们暂时忽略它们,只考虑
。同时我们会经历
将
。不过在原论文的分析中并没有考虑写回的复杂度,不过省略一些常数项不会影响我们最终的分析。
所以,总体来说flash attention的IO复杂度为:
。论文中提过,一般
。因此可以看出,Flash attention的IO复杂度是要显著小于标准attention的IO复杂度的。