标准Attention与Safe softmax
标准Attention
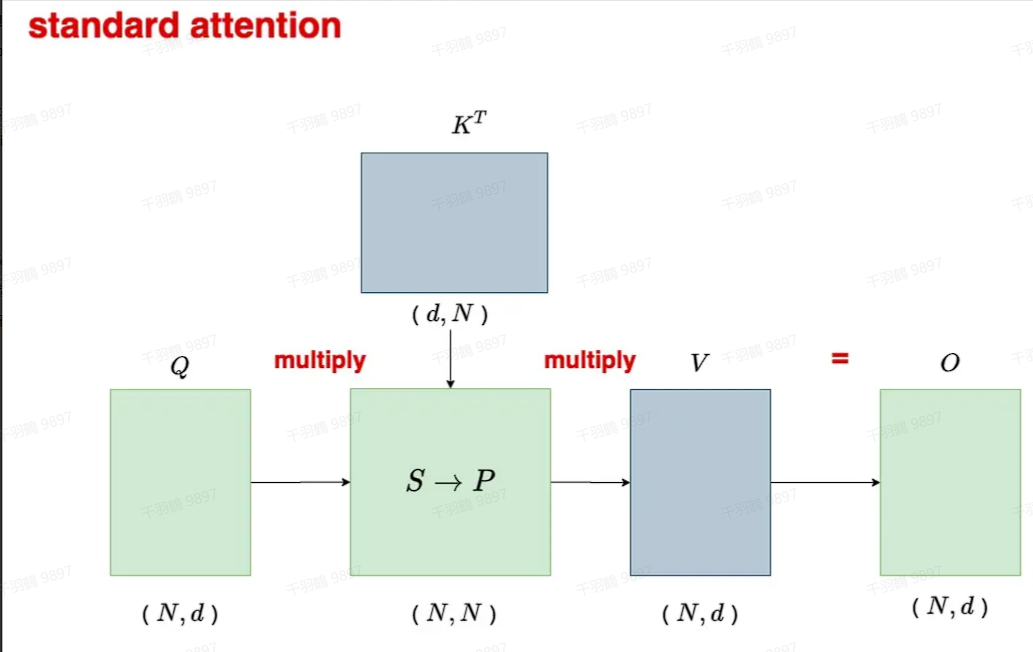
在介绍标准Attention之前,我们先定义几个基本变量:假设
标准Safe softmax
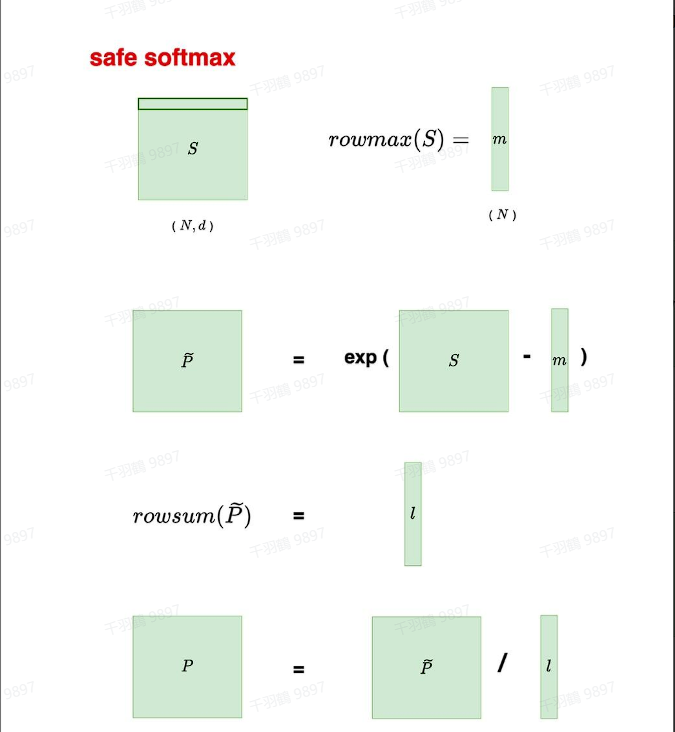
在处理浮点数时,特别是对于
首先,找出最大值
然后,计算Safe softmax:
通过这样的处理,可以有效避免数值不稳定的问题,提高计算的精度和稳定性。在实际应用中,Safe softmax是一个非常重要的技巧,尤其是在深度学习模型中涉及到概率分布的计算时。
在介绍标准Attention之前,我们先定义几个基本变量:假设
在处理浮点数时,特别是对于
首先,找出最大值
然后,计算Safe softmax:
通过这样的处理,可以有效避免数值不稳定的问题,提高计算的精度和稳定性。在实际应用中,Safe softmax是一个非常重要的技巧,尤其是在深度学习模型中涉及到概率分布的计算时。