计算与内存限制
在现代计算中,尤其是在处理自然语言处理任务时,transformer模型的self-attention块是一个关键组件。然而,self-attention块的计算复杂度和空间复杂度与序列长度N的二次方成正比,这对计算资源提出了巨大的要求。因此,许多近似注意力的方法被提出,以减少attention的计算和内存要求。
近似注意力方法
稀疏近似和低秩近似是两种常见的方法,它们将计算复杂度降低到了序列长度的线性或亚线性。然而,这些方法并没有得到广泛应用,因为它们过于关注FLOPs(浮点数计算次数)的减少,而忽略了IO读写的内存访问开销。在现代GPU中,计算速度已经远超过了显存访问速度,transformer中的大部分计算操作的瓶颈是显存访问。
注意区分FLOPS和FLOPs
- FLOPS:全大写,表示每秒钟执行的浮点数操作次数,是衡量硬件性能的指标。
- FLOPs:s为小写,表示浮点数运算次数,是衡量模型或算法复杂度的指标。
计算带宽与内存带宽
- 计算带宽(math bandwidth):处理器每秒钟可以执行的数学计算次数,单位通常是OPS(即operations/second)。如果用浮点数进行计算,单位是FLOPS。
- 内存带宽(memory bandwidth):处理器每秒钟从内存中读取的数据量,单位是bytes/second。
性能受限类型
- math-bound:性能受限于计算带宽,例如大矩阵乘法、通道数很大的卷积运算。
- memory-bound:性能受限于内存带宽,例如逐点运算的操作,如激活函数、dropout、mask,以及reduction操作如softmax、batch normalization和layer normalization。
对于self-attention块,除了大矩阵乘法是计算受限,其他操作如计算softmax、dropout、mask都是内存受限的。
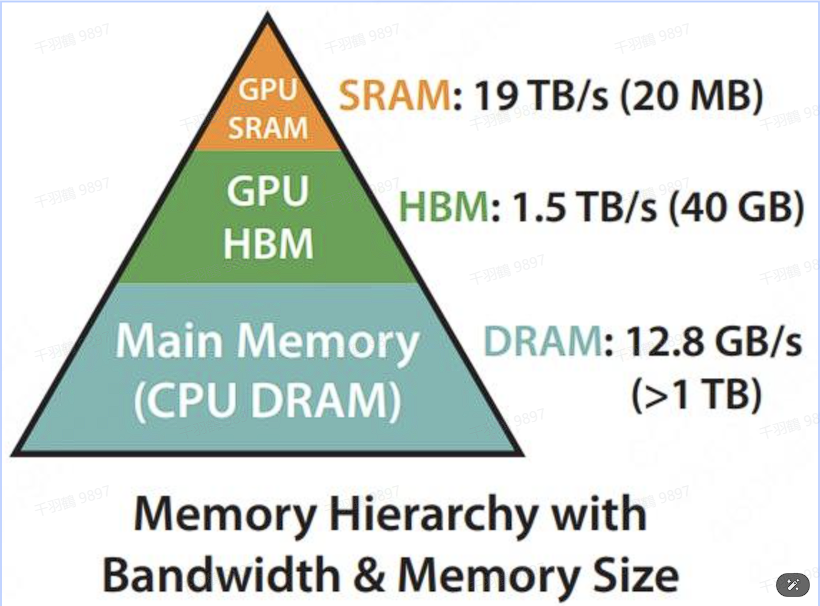
GPU内存分级
GPU内存由多个不同大小和不同读写速度的内存组成。内存越小,读写速度越快。
- 片上内存:主要用于缓存(cache)及少量特殊存储单元(例如texture),其特点是“存储空间小,但带宽大”。例如SRAM,其存储空间只有20MB,但带宽可以达到19TB/s。
- 片下内存:主要用于全局存储(global memory),即我们常说的显存,其特点是“存储空间大,但带宽小”。例如HBM,其存储空间有40GB(A100 40GB),但带宽相比于SRAM小得多,只有1.5TB/s。因此,减少对HBM的读写次数,有效利用更高速的SRAM进行计算非常重要。
GPU运行模式
GPU有大量的线程来执行某个操作,称为kernel。执行操作分为三步:
- 每个kernel将输入数据从低速的HBM中加载到高速的SRAM中。
- 在SRAM中进行计算。
- 将计算结果从SRAM中写入到HBM中。
kernel融合
在进行GPU计算时,kernel融合是一种优化策略,可以减少显存访问次数,提高计算效率。通过将多个kernel操作融合为一个,可以在一次显存访问中完成多个计算任务,从而提高整体性能。
在现代计算中,理解计算与内存限制对于优化模型性能至关重要。通过合理利用GPU的不同内存层级和优化kernel执行策略,可以有效提升模型运行效率。希望这篇文章能帮助您更好地理解这些概念,并在实践中应用这些知识。