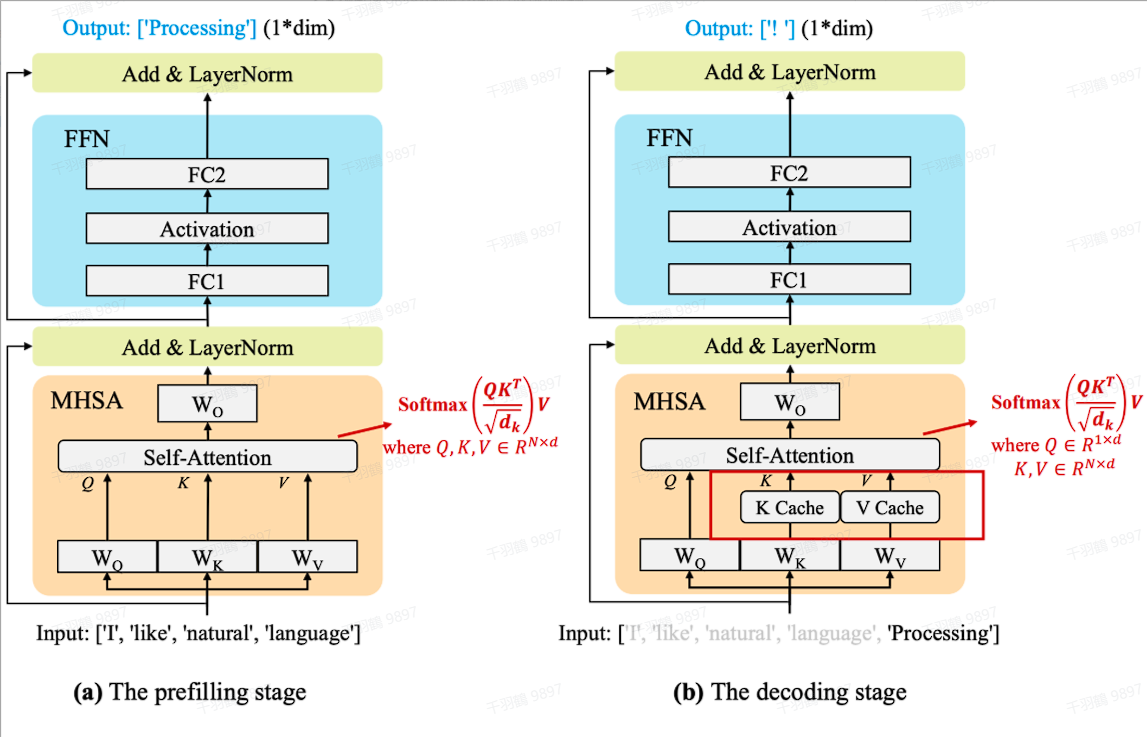
PageAttention原理
PageAttention原理
核心机制
利用虚拟内存的思想,合理利用碎片内存。大模型推理的性能瓶颈主要来自于内存。一是自回归过程中缓存的K和V张量非常大,在LLaMA-13B中,单个序列输入进来需要占用1.7GB内存。二是内存占用是动态的,取决于输入序列的长度。由于碎片化和过度预留,现有的系统浪费了60%-80%的内存。PagedAttention灵感来自于操作系统中虚拟内存和分页的经典思想,它可以允许在非连续空间里存储连续的KV张量。具体来说,PagedAttention把每个序列的KV缓存进行了分块,每个块包含固定长度的token,而在计算attention时可以高效地找到并获取那些块。
动图演示
每个固定长度的块可以看成虚拟内存中的页,token可以看成字节,序列可以看成进程。那么通过一个块表就可以将连续的逻辑块映射到非连续的物理块,而物理块可以根据新生成的token按需分配。
单个请求:
动图演示
多个请求:
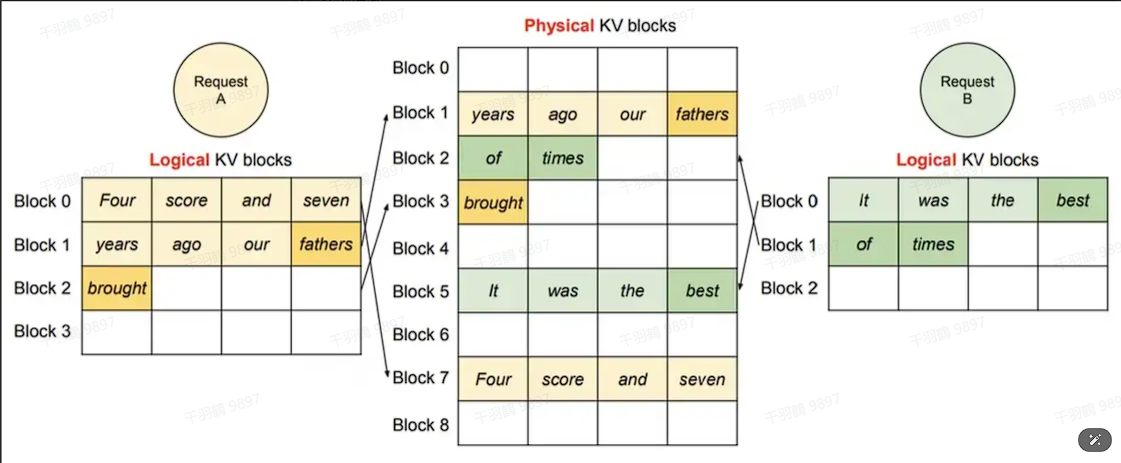
所有序列在分块之后,只有最后一个块可能会浪费内存(实际中浪费的内存低于4%)。高效利用内存的好处很明显:系统可以在一个batch中同时输入更多的序列,提升GPU的利用率,显著地提升吞吐量。
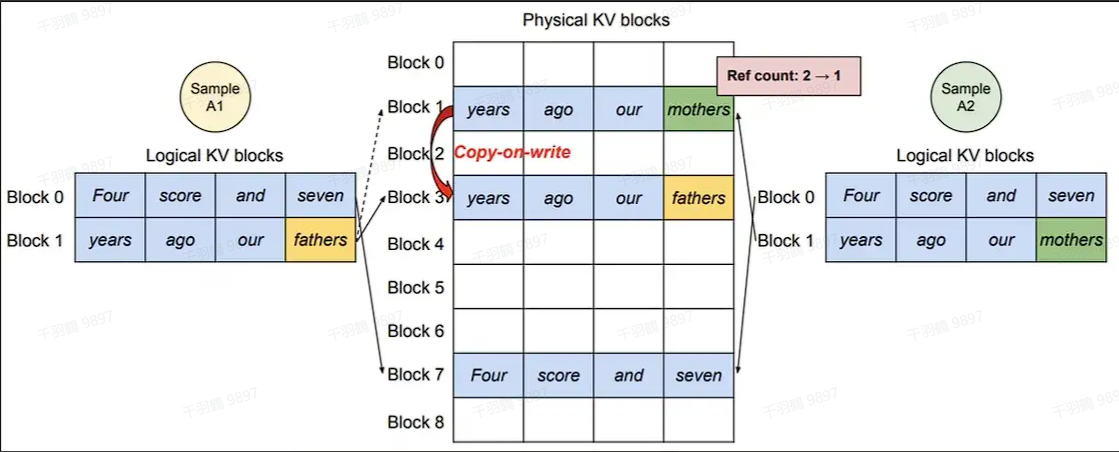
PagedAttention的另外一个好处是高效内存共享。例如,在并行采样的时候,一个prompt需要生成多个输出序列。这种情况下,对于这个prompt的计算和内存可以在输出序列之间共享。
动图演示
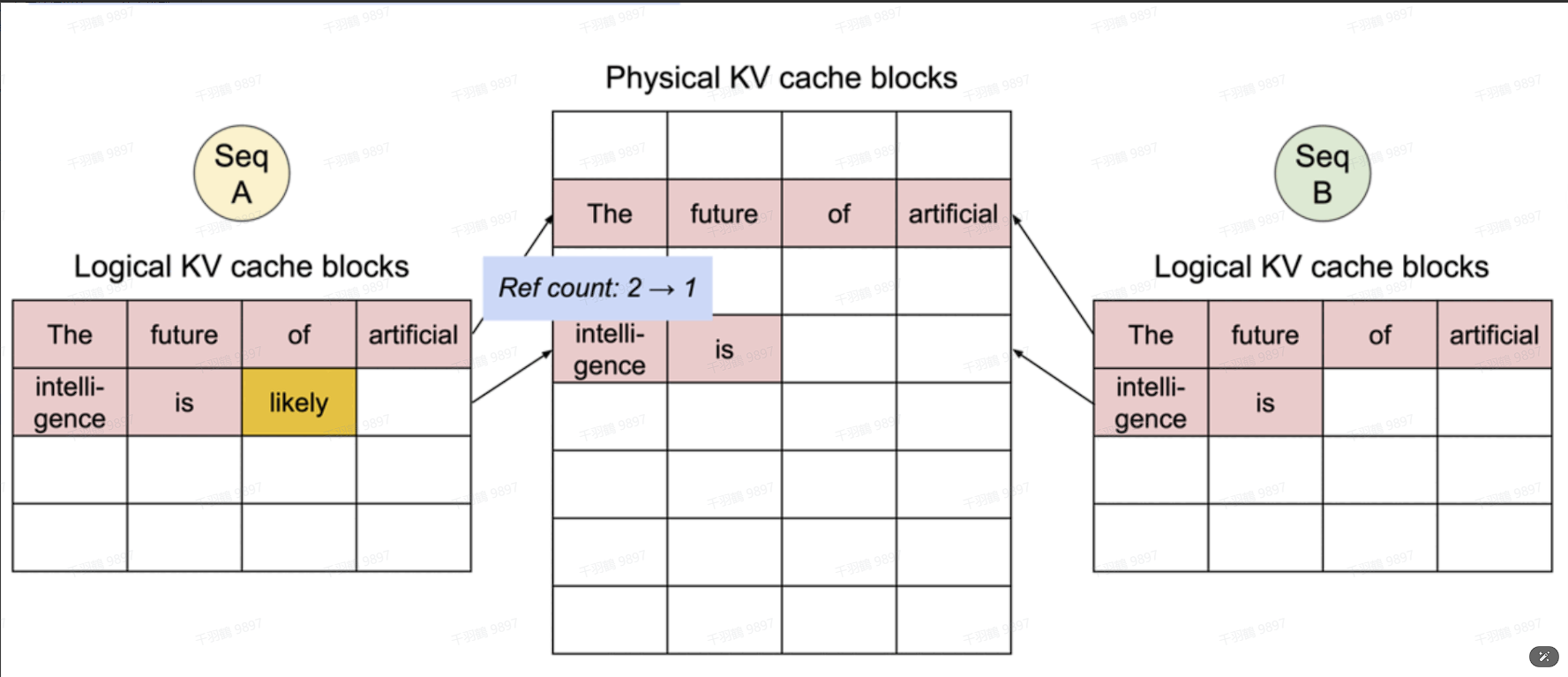
通过块表可以自然地实现内存共享。类似进程间共享物理页,在PagedAttention中的不同序列通过将逻辑块映射到一样的物理块上可以实现共享块。为了确保安全共享,PagedAttention跟踪物理块的引用计数,并实现了Copy-on-Write机制。内存共享减少了55%内存使用量,大大降低了采样算法的内存开销,同时提升了高达2.2倍的吞吐量。
动图演示
不同解码策略下的用法
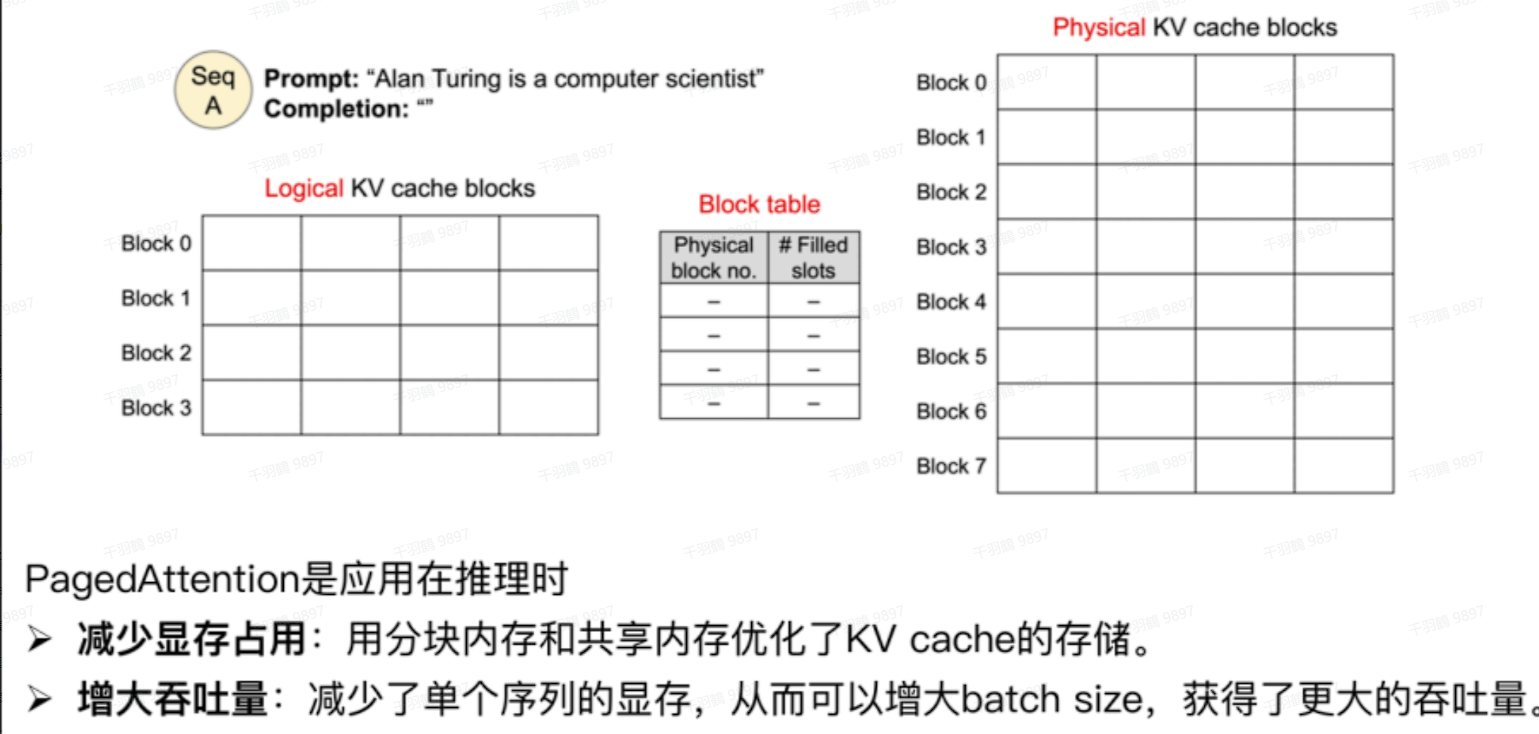
给模型发送一个请求,希望它对prompt做续写,并给出三种不同的回答。我们管这个场景叫parallel sampling。
prefill阶段
vLLM拿到Sample A1和Sample A2,根据其中的文字内容,为其分配逻辑块和物理块。其中A1和A2的block0和block1是共享的。
decode阶段
当两个sample生成的token不一致时,触发copy-on-write,即在物理内存上新开辟一块空间。此时物理块block1只和A2的逻辑块block1映射,将其ref count减去1;物理块block3只和A1的逻辑块block1映射,将其ref count设为1。
通过上述机制,PagedAttention实现了高效的内存管理和共享,大大提升了系统性能和资源利用率。这种创新性的内存管理方式为大规模模型推理提供了新的解决方案,值得进一步研究和应用。