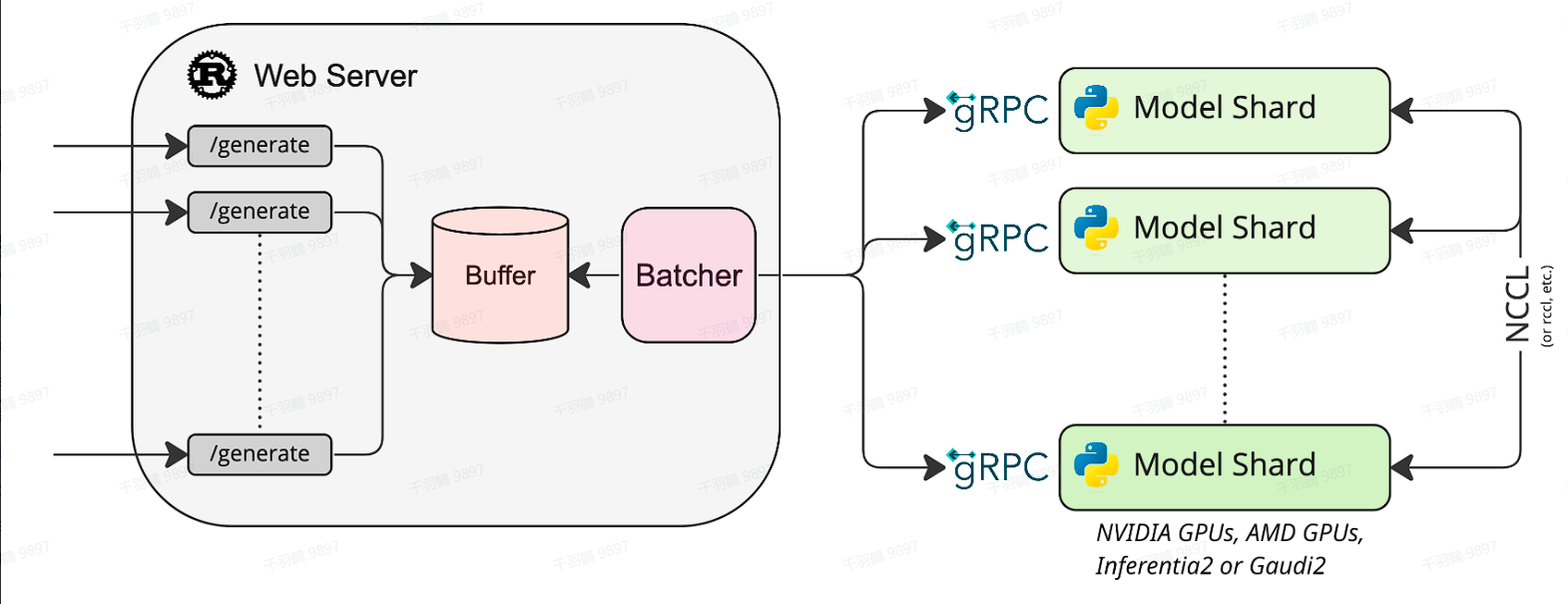
从图中可以看出,若干个客户端同时请求Web Server的“/generate”服务后,服务端会将这些请求在“Buffer”组件处整合为Batch,并通过gRPC协议转发请求给GPU推理引擎进行计算生成。至于将请求发给多个Model Shard,多个Model Shard之间通过NCCL通信,这是因为显存容量有限或出于计算效率考虑,需要多张GPU进行分布式推理。
Prefill和Decode
出于效率考虑,推理框架一般会将第1次推理(生成第1个Token)和余下的推理(生成其余Token)分别设计为Prefill和Decode两个过程。
Prefill是将1个请求的Prompt一次性转换为KV Cache,并生成第1个Token的过程。假设Prompt的长度为 L H H S [ L , H , H S ] [ L , H ∗ H S ]
从第2个Token开始,将上一次推理的输出(新生成的1个Token)作为输入进行一次新的推理,这就是Decode的过程。假设BatchSize=1,已生成的新子序列长度为 N [ 1 , H , H S ] [ L + N + 1 , H , H S ] [ 1 , H ∗ H S ] 很明显,将推理分为Prefill和Decode两个流程,是考虑到生成第1个Token和其余Token时计算模式的差异较大,分开实现有利于针对性的优化。
Concatenate和Filter
上述讨论仅在BatchSize=1的情况下讨论,从计算维度可以看出,Prefill环节在Prompt较长时计算强度足够高(可以这样“不准确地”理解:Prompt有 L L
对Late-joining Requests的处理。相对常见的CV业务而言,占用GPU推理的时间是漫长的(<1S VS 数秒到数十秒)。所以如果没有一个将新请求插入到推理Batch的机制,还是还像之前场景那样等前面的请求都推理结束后才进行推理,用户增加排队的时间会很长。因此需要设计一个机制来动态处理这些Late-joining Requests,以提高整体效率。