vLLM
vLLM
vLLM是一个开源的大模型推理加速框架,通过PagedAttention高效地管理attention中缓存的张量,实现了比HuggingFace Transformers高24倍的吞吐量,其原理是基于PagedAttention的。
Prefill
预填充阶段。在这个阶段中,我们把整段prompt喂给模型做forward计算。如果采用KV cache技术,在这个阶段中我们会把prompt过
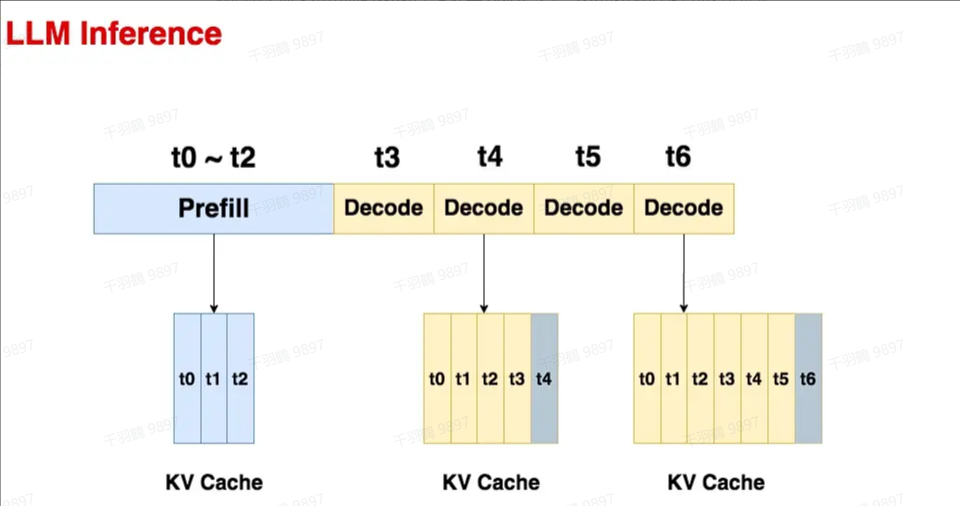
Decode
生成response的阶段。在这个阶段中,我们根据prompt的prefill结果,一个token一个token地生成response。由于Decode阶段的是逐一生成token的,因此它不能像prefill阶段那样能做大段prompt的并行计算,所以在LLM推理过程中,Decode阶段的耗时一般是更大的。
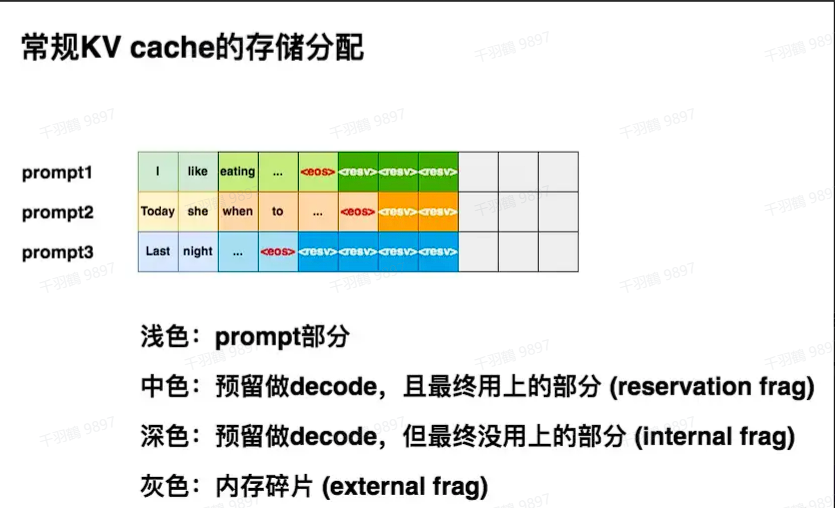
常规KV cache分配
痛点:由于推理所生成的序列长度大小是无法事先预知的,所以大部分框架会按照 (batch_size, max_seq_len) 这样的固定尺寸,在gpu显存上预先为一条请求开辟一块连续的矩形存储空间。然而,这样的分配方法很容易引起“gpu显存利用不足”的问题,进而影响模型推理时的吞吐量。