首Token时延优化
首Token时延
在LLM(大型语言模型)推理过程中,生成首token是一个计算密集型任务。生成首token阶段也被称为预填充阶段(prefill phase)或上下文阶段(context phase)。生成首token的时间与处理输入给大模型的Prompt的计算量有关,与Prompt长度直接相关。例如,在Prompt长度相对较长的情况下,再考虑到技术优化,使用FlashAttention2生成首token的时间与输入Prompt的长度近似成线性关系。
首个token的推理延迟
首个token的推理延迟可以表示为:
后续每个token的推理延迟
对于后续每个token的推理延迟,可以表示为:
优化System Prompt
System Prompt Caching的基本思想是对System Prompt部分进行一次计算,并缓存其对应的Key和Value值(例如,存放在GPU显存中)。当LLM推理再次遇到相同的(甚至部分相同的)System Prompt时,可以直接利用已经缓存的System Prompt对应的Key和Value值,这样就避免了对于System Prompt的重复计算。
第一种形式:Prefix Sharing
Prefix Sharing适用于“Prompt = System Prompt + User Prompt”这样的场景,其中System Prompt就是前缀(Prefix)。

第二种形式:Prompt Cache
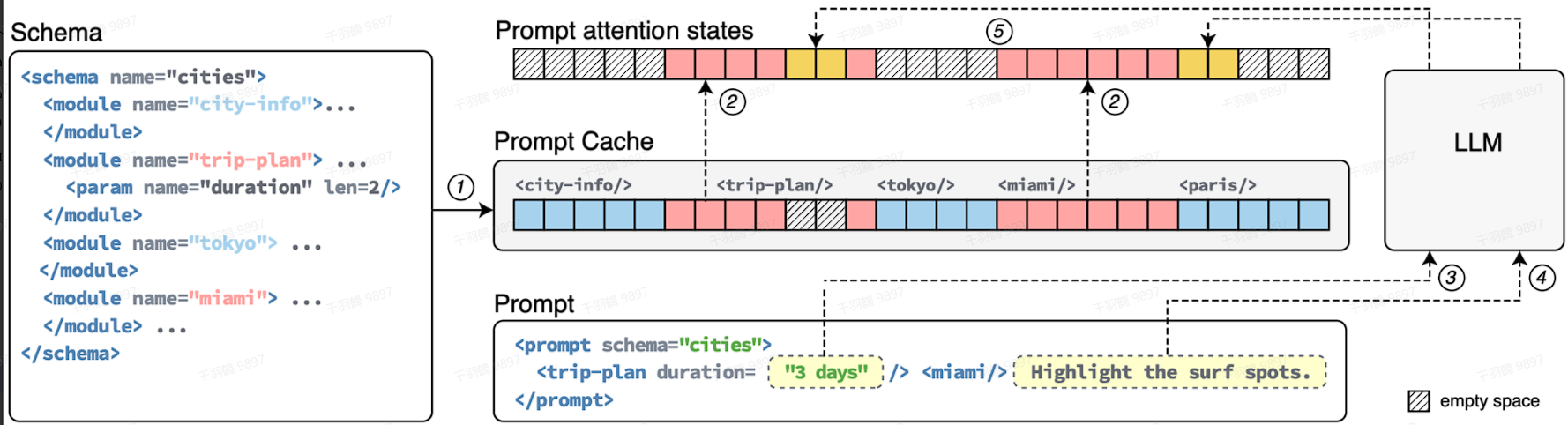
Prompt Cache属于相对高级的用法,是对整个输入Prompt对应的Key和Value值进行Caching操作,不局限于共享前缀。
特别地,对于多轮对话场景,以及基于LLM的AI Agent应用场景,上述第二种方式,即Prompt Cache,可以支持Session Prompt Cache。在一个多轮对话session里,输入到LLM的Prompt会携带多轮对话历史,涉及到很多重复计算。通过Session Prompt Cache可以显著减少不必要的重复计算,节省GPU资源,提高对话响应速度和用户体验。
通过对首Token时延和System Prompt Caching的优化,可以有效提高LLM推理的效率,降低计算资源消耗,从而提升用户体验。这些技术在实际应用中具有重要价值,特别是在涉及大量文本处理和生成任务的场景中。