DeepSpeed
DeepSpeed 深入解析
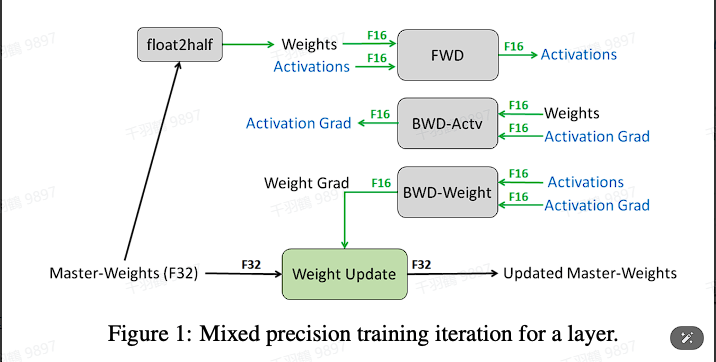
混合精度训练
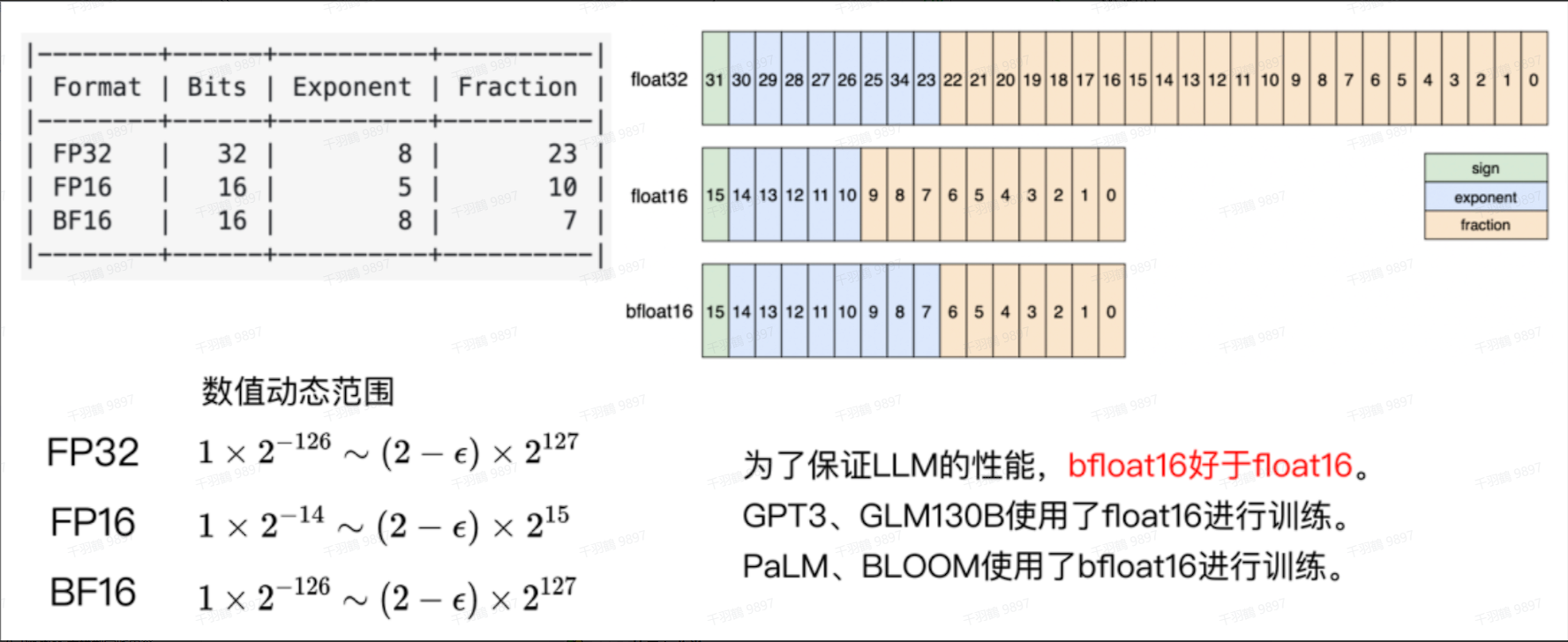
在训练过程中,DeepSpeed 支持同时使用 FP16 和 FP32 两种精度的数据类型。具体而言,在进行前向传播(forward)和反向传播(backward)时,数据类型会转换为 FP16,而在参数更新阶段则转换为 FP32。这种方法可以有效提高训练效率,同时保持较高的计算精度。关于混合精度训练的详细信息,可以参考 2.3.7 章。
ZeRO 零冗余优化器
ZeRO的显存分类
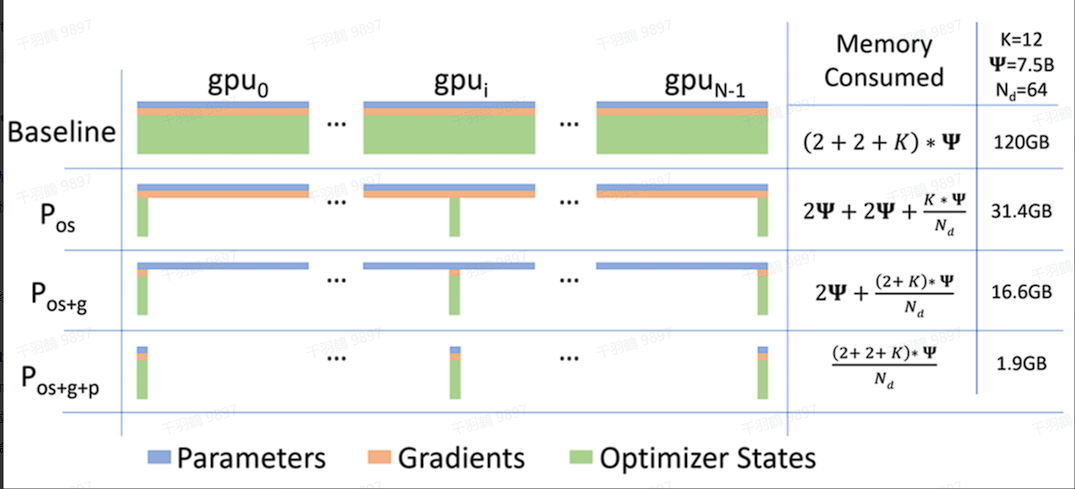
ZeRO 优化器通过显存的精细管理来提高模型训练的效率,其显存分类如下:
-
模型状态(model states):包括模型参数(FP16)、模型梯度(FP16)和 Adam 状态(FP32 的模型参数备份,FP32 的 momentum 和 FP32 的 variance)。假设模型参数量为
,则共需要存储空间为 字节。可以看到,Adam 优化器状态占据了显存的 75%,而更新参数时还需加上 FP32 的梯度。 -
剩余状态(residual states):包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)。其中,激活值可以通过 activation checkpointing 来大幅减少。
ZeRO 三个阶段以及显存占用分析
数据通信量分析
DeepSpeed ZeRO 主要采用数据并行的方法。
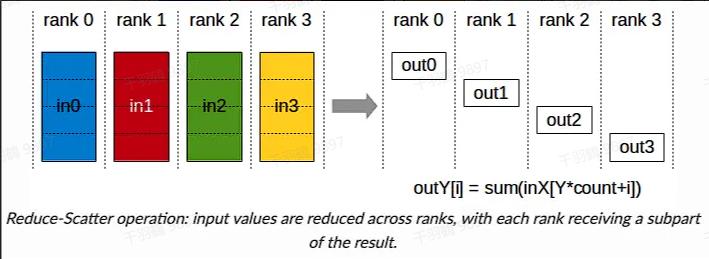
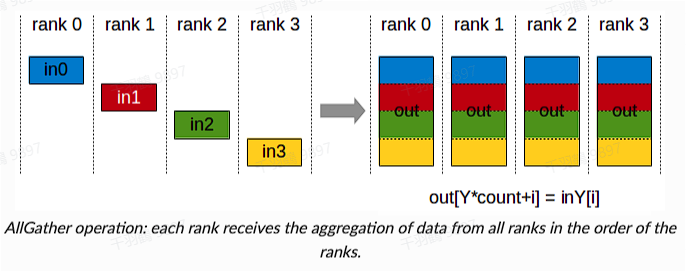
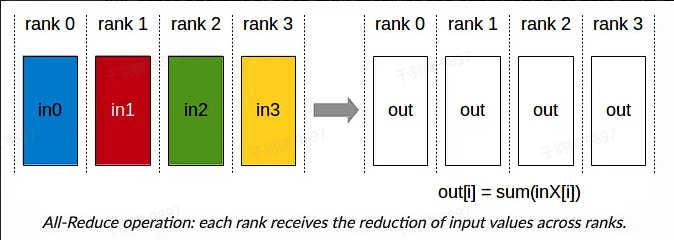
传统数据并行
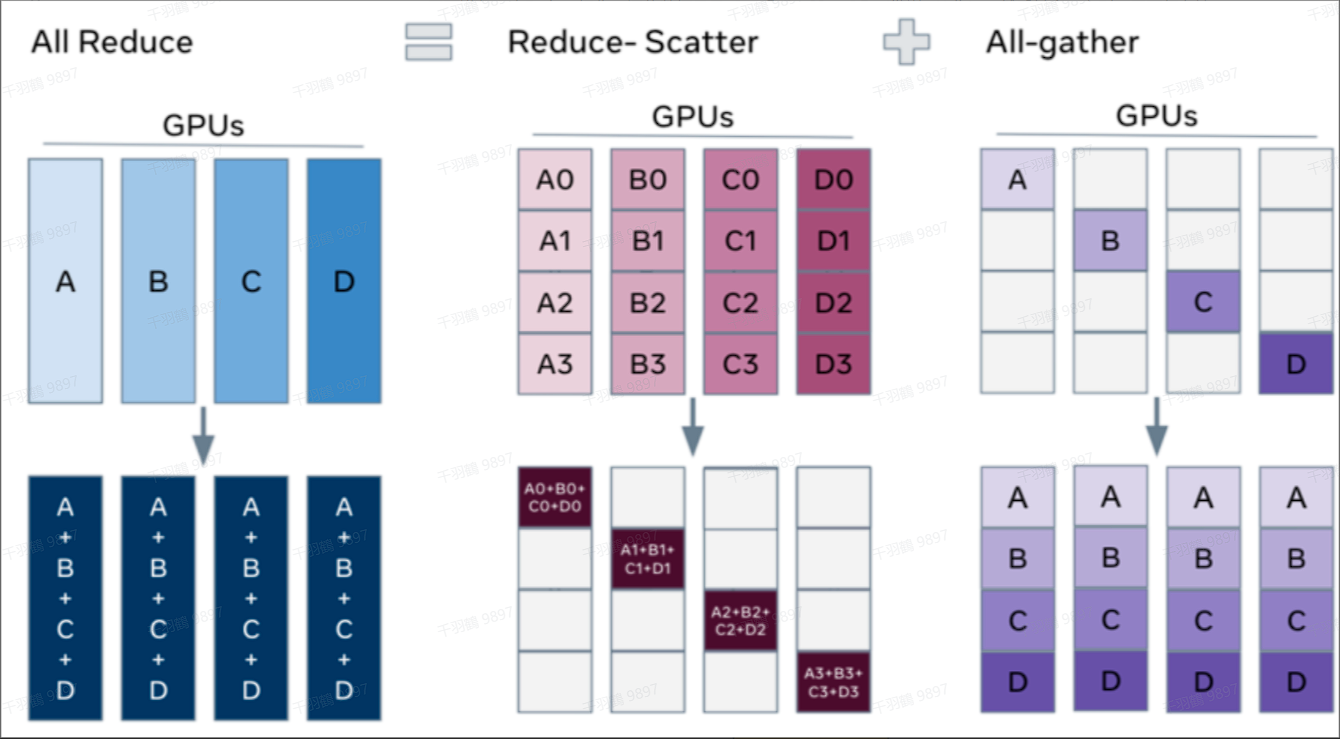
在传统的数据并行中,每一步(step/iteration)计算梯度后,需要进行一次 AllReduce 操作来计算梯度均值。常用的方法是 Ring AllReduce,分为 ReduceScatter 和 AllGather 两步,每张卡的通信数据量(发送+接受)近似为
ZeRO1、2阶段(优化器状态分区、梯度分区)
在 ZeRO1 和 ZeRO2 阶段,与传统数据并行类似。每张卡只存储
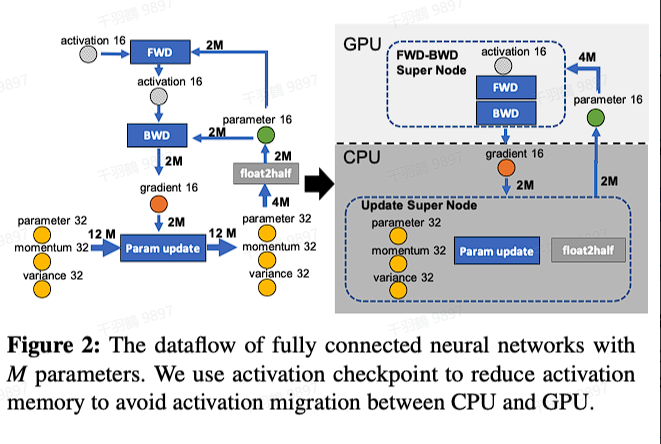
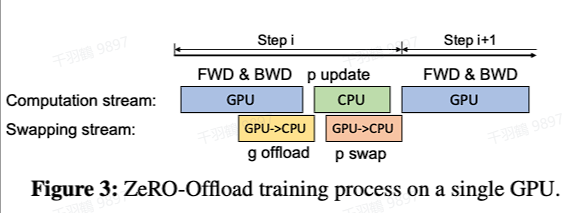
深入理解 ZERO3 与 CPU 卸载技术
在深度学习的训练过程中,模型参数的存储和计算效率一直是研究的重点。本文将详细探讨 ZERO3 技术以及 CPU 卸载策略如何优化深度学习模型的训练过程。
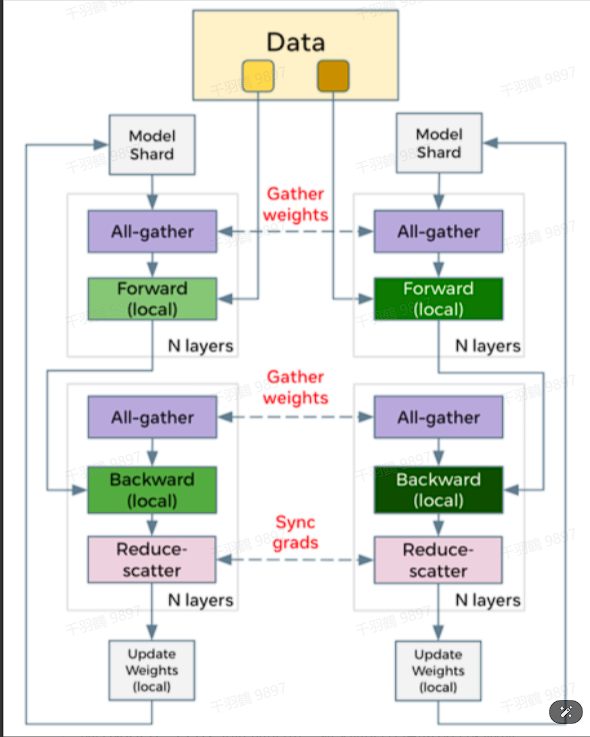
通信效率分析
ZERO3 的通信量为
CPU卸载策略
CPU卸载技术不仅仅是将数据卸载到 CPU,还包括将部分计算任务转移到 CPU,从而显著减少 GPU - CPU 之间的通信量。
CPU卸载的优化目标
CPU卸载应满足以下三个方面的最优:
- 减少CPU的计算量:避免 CPU 成为性能瓶颈。
- 最小化GPU - CPU之间的通信量:避免通信开销成为性能瓶颈。
- 在最小化通信量时,最大化GPU的显存节省。
数据卸载策略
- FP32的模型参数、优化器状态:这些被卸载到 CPU。
- FP16的模型参数、中间激活:这些则保留在 GPU 上。
计算卸载策略
- 优化器更新模型参数:这部分计算任务被卸载到 CPU。
- 前向传递和后向传递:这些计算任务依然在 GPU 上进行。
通信量分析
在 CPU卸载策略中,通信涉及到 FP16 的梯度和模型参数。这种策略有效地减少了 GPU 和 CPU 之间的数据传输需求。