Megatron-LM
Megatron-LM
Megatron-LM 是一个基于 PyTorch 的分布式训练框架,用来训练基于 Transformer 的大型语言模型。大型模型能够提供更精准和强大的语义理解与推理能力。随着计算资源的普及和数据集的增大,模型参数的数量呈指数级增长。然而,训练这样规模庞大的模型面临着一些挑战:
Megatron-LM 的优缺点
Megatron-LM 是预训练必用框架,训练速度比 DeepSpeed 快,但也有诸多缺点:
- Megatron-LM 作为框架完全没有分层分模块,也没有太多抽象设计,导致模型跟框架无法解耦,需要手动切割模型并且适配,只适合 GPT/LLama 系列模型。
- 通信有明显精度损失,特别是 ringallReduce。
- Megatron 推理时,kv cache 存在低级 bug,容易导致 RLHF 训练失败。
- 混合精度训练时,bf16 没有 master weight。
- 显存乱申请,加上 PyTorch allocator 拉垮,经常出现 OOM(Out of Memory)。
虽然有这么多缺点,但是 Megatron-LM 仍然是千卡集群以上最佳的选择,没有之一。千卡以内可以选择 FSDP 或者 TorchTitan。
Megatron-LM 的特点
Megatron-LM 支持数据并行、张量并行、流水线并行和专家并行,简称 4D 并行。
提醒
可以看看李沐的视频。
大型模型训练的挑战
训练大型模型面临的挑战主要包括显存限制、计算挑战以及并行策略挑战。
显存限制
即便是目前最大的 GPU 主内存也难以容纳这些模型的参数。举例来说,一个 1750 亿参数的 GPT-3 模型需要约 700GB 的参数空间,对应的梯度约为 700GB,而优化器状态还需额外的 1400GB,总计需求高达 2.8TB。
计算挑战
即使我们设法将模型适应单个 GPU(例如通过在主机内存和设备内存之间进行参数交换),模型所需的大量计算操作也会导致训练时间大幅延长。举个例子,使用一块 NVIDIA V100 GPU 来训练拥有 1750 亿参数的 GPT-3 模型,大约需要耗时 288 年。
并行策略挑战
不同的并行策略对应不同的通信模式和通信量,这也是一个需要考虑的挑战。
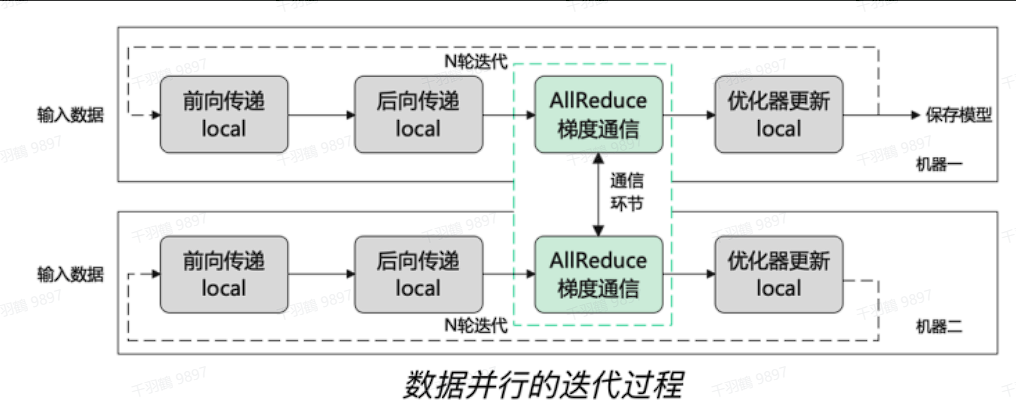
在现代的深度学习训练中,数据并行是一种常用的策略,通过将模型的训练任务分散到多个计算单元上来提高效率和加速训练过程。本文将详细介绍数据并行的概念、其优缺点,以及在分布式计算中常用的 All-Reduce 操作。
数据并行
数据并行(Data Parallelism, DP)是一种将模型训练任务分散到多个计算单元(如 GPU)的策略。假设有
对于无法放进单个 Worker 的大模型,可以在模型的较小片段上使用数据并行。这种方法在扩展性上通常表现出色,但存在两个限制:

限制
-
降低 GPU 利用率:在一定点之后,每个 GPU 的批量大小变得太小,这会降低 GPU 的利用率,并增加通信成本。
-
设备数限制:可用于训练的 GPU 设备数量受到批量大小的限制,这限制了可以使用的最大设备数。
All-Reduce 操作
All-Reduce 是一种在并行计算和分布式计算中常用的通信操作,用于在多个计算节点(例如 GPU 或 CPU)之间汇总数据。
工作原理
-
数据分发:每个节点在完成了自己的计算后会生成一组梯度(或者其他需要汇总的数据),这些数据需要在所有节点之间进行汇总。
-
数据汇总:All-Reduce 操作将每个节点上的数据在所有节点之间进行相加或其他类型的归约操作(例如,求和、求平均、求最大值等)。这意味着最终每个节点都会得到相同的结果,该结果是所有节点数据的汇总。
-
结果广播:完成汇总操作后,汇总结果会被广播回每个节点,使得每个节点都持有相同的汇总数据。这一步确保了所有节点在下一步的计算中都能使用一致的数据。
模型并行
Model Parallelism MP
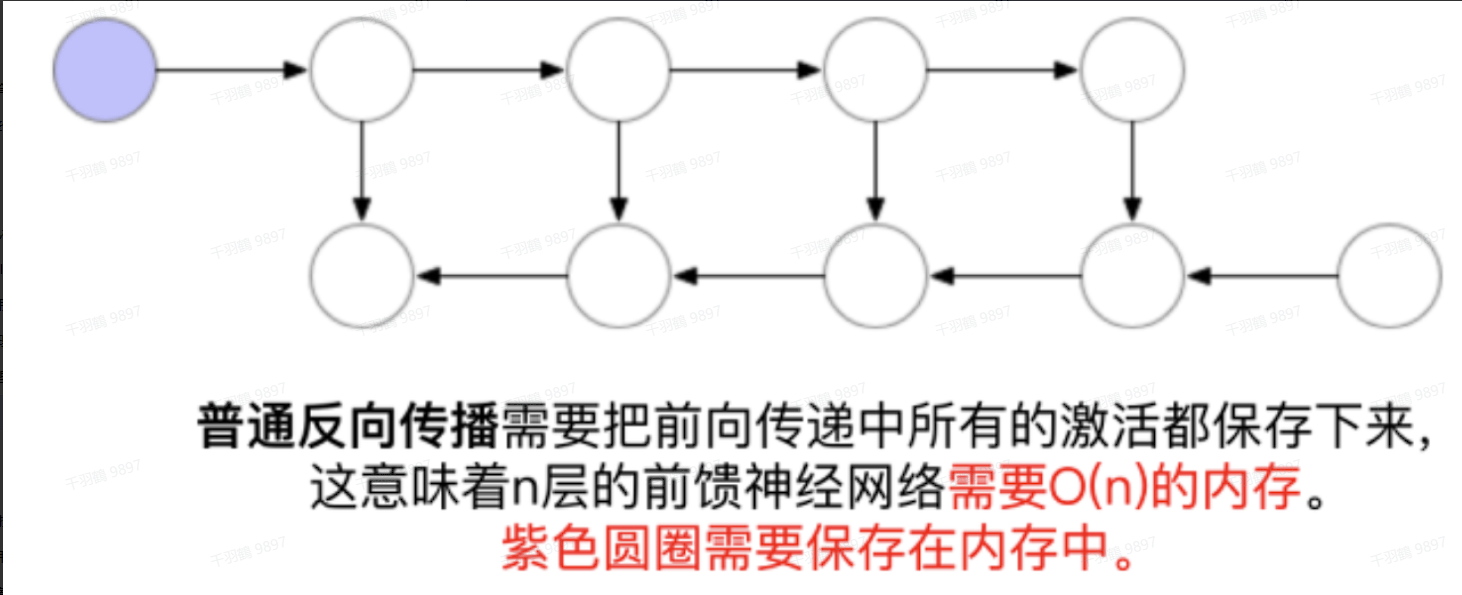
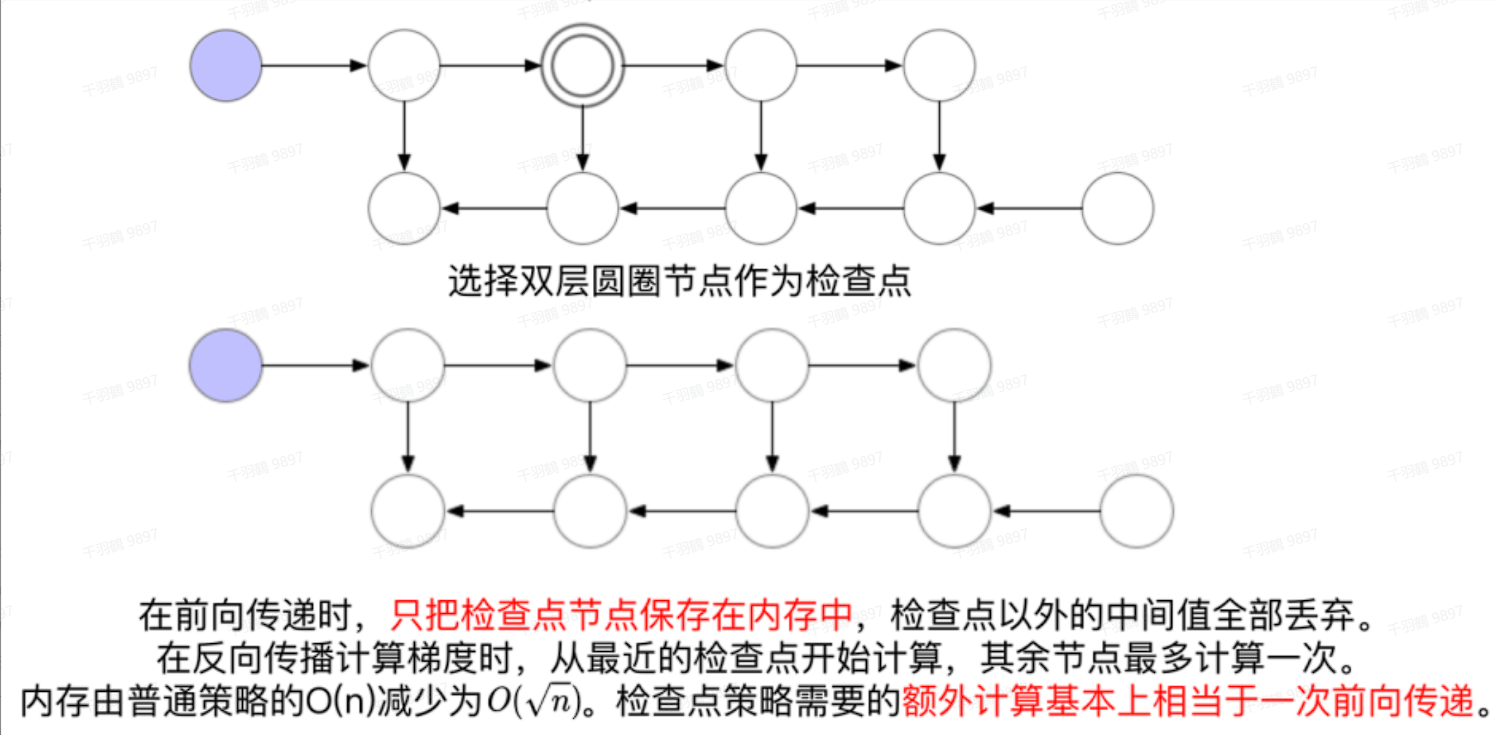
对于数据并行的限制,可以采用一些内存管理技术,比如激活检查点(Activation Checkpointing)。
Activation Checkpointing(gradient_checkpointing)
激活检查点是一种在前向传播过程中计算节点的激活值并保存的方法。计算下一个节点完成后丢弃中间节点的激活值,反向传播时如果有保存下来的梯度就直接使用,如果没有就使用保存下来的前一个节点的梯度重新计算当前节点的梯度再使用。
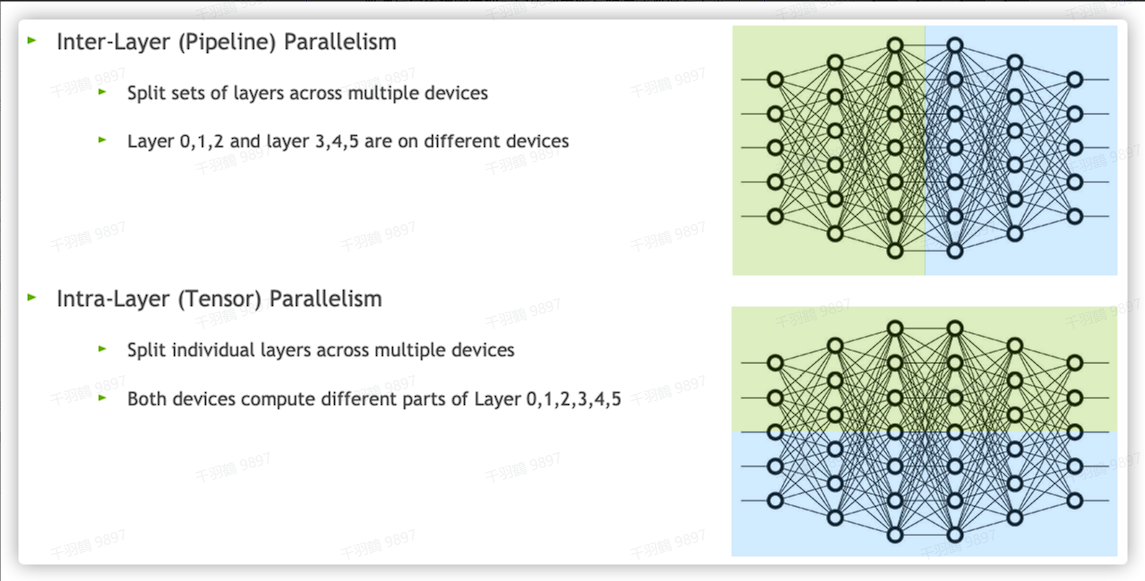
此外,还可以使用模型并行来划分模型的不同阶段,从而解决GPU内存容量和计算限制的问题,使得权重和关联的优化器状态不需要同时存储在一个GPU上。一个模型的内存和计算被分布在多个计算节点上,主要的方式分为流水线并行和张量并行。
张量并行 Intra-Layer Tensor Parallelism
有的tensor/layer很大,一张卡放不下,将tensor分割成多块,一张卡存一块。这也可以被理解为将大矩阵运算拆分成多个小矩阵运算,然后分布到不同的设备上进行计算。
代码块
高度的模型并行会产生很多的小矩阵乘法(GEMMS)。对于一个GEMMs
# 假设模型有三层:L0, L1, L2 每层有两个神经元 两张卡
GPU0:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
GPU1:L0 | L1 | L2
---|----|---
a1 | b1 | c1
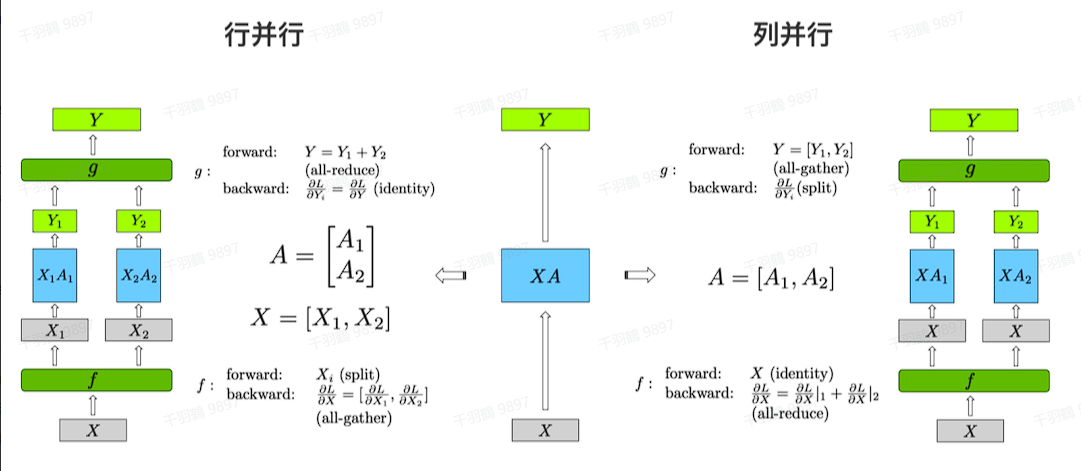
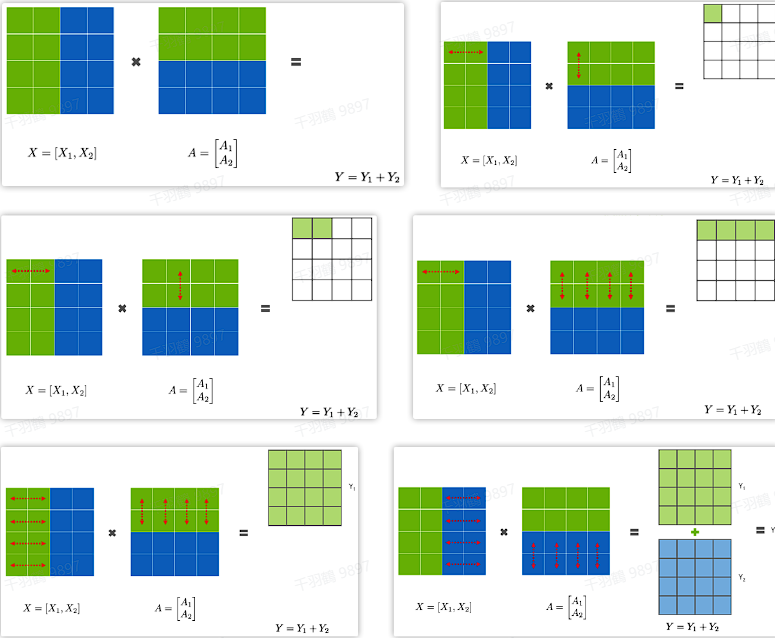
GEMMs行并行
先分析Row Parallelism,就是把权重矩阵
这样
通过这种方式,可以有效地将大型模型的计算任务分配到多个GPU上,从而提高计算效率,同时解决单个GPU内存不足的问题。这种技术在处理大型深度学习模型时尤为重要,因为它能够显著提高训练速度,并允许更大规模的模型在有限硬件资源下进行训练。
GEMMs列并行与Transformer中的张量并行
在现代深度学习模型中,尤其是Transformer架构中,矩阵计算的并行化是提升模型训练和推理速度的关键。本文将探讨GEMMs列并行和Transformer中的张量并行技术。
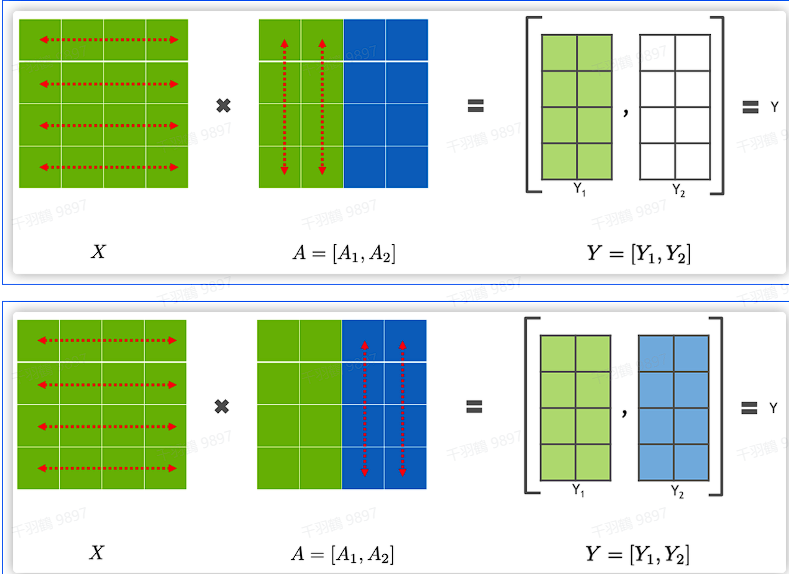
GEMMs列并行
GEMMs列并行是一种将矩阵
Transformer中的张量并行
Transformer架构包含了Self-Attention和Feed Forward Network,这些操作涉及大量的矩阵计算,非常适合在GPU上进行并行操作,以加速模型的训练和推理过程。
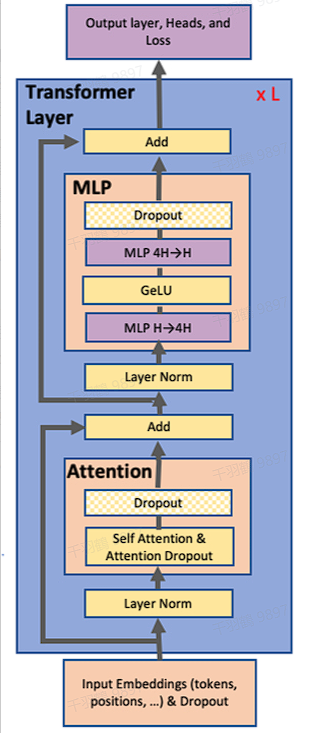
Masked Multi-Head Self Attention
Masked Multi-Head Self Attention涉及到大量的矩阵乘法操作,这些操作可以被高效地并行执行,从而提高计算速度。
Feed Forward Neural Network
Feed Forward Neural Network包含多个全连接层,每个全连接层都涉及矩阵乘法、激活函数(通常是GeLU)和可能的Dropout层。这些操作也是高度并行化的,可以在GPU上迅速执行。
Megatron的FFN是一个两层MLP,第一层是维度从
张量并行就是要对Transformer进行切分,Megatron把Masked Multi-Head Self Attention和Feed Forward都进行切分以并行化,通过添加一些同步通信操作来创建一个简单的模型并行实现。
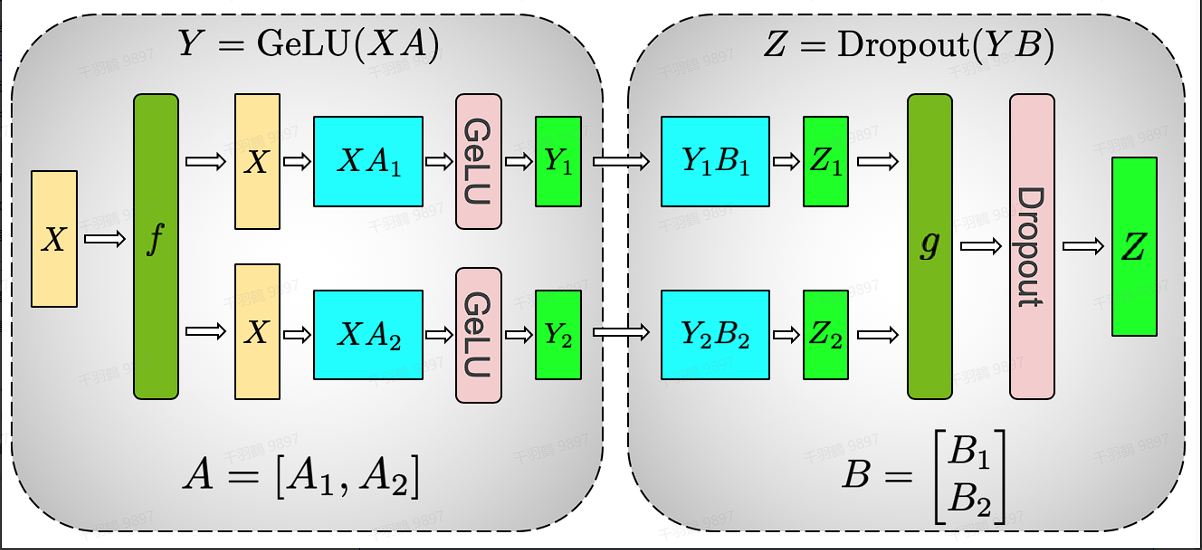
切分MLP
从MLP开始,MLP的第一部分是GEMM,后面是激活函数GeLU:
对比按照行列切分权重的方法
行并行
行并行的方法如下:
但是,由于GeLU是非线性计算:
所以这种方案需要在GeLU函数之前加上一个同步点,这个同步点让不同GPU之间交换信息。
列并行
列并行的方法如下:
这种方法不需要同步点,可以直接把两个GeLU的输出拼接起来,而不需要额外的通信(比如GeLU这里就不用all-reduce了)。在前向和后向传递的时候做一次all-reduce通信操作。对于第二个MLP使用行并行,可以直接与第一个MLP得到的
总的来说,在MLP层中,对
在现代深度学习中,模型的规模和复杂度不断增加,如何高效地利用GPU资源成为了一个重要的研究课题。本文将探讨在神经网络计算中,如何通过合理的切分策略来减少GPU之间的通信量,以提高整体计算效率。
GELU计算中的行列切割策略
在处理矩阵
通信量分析
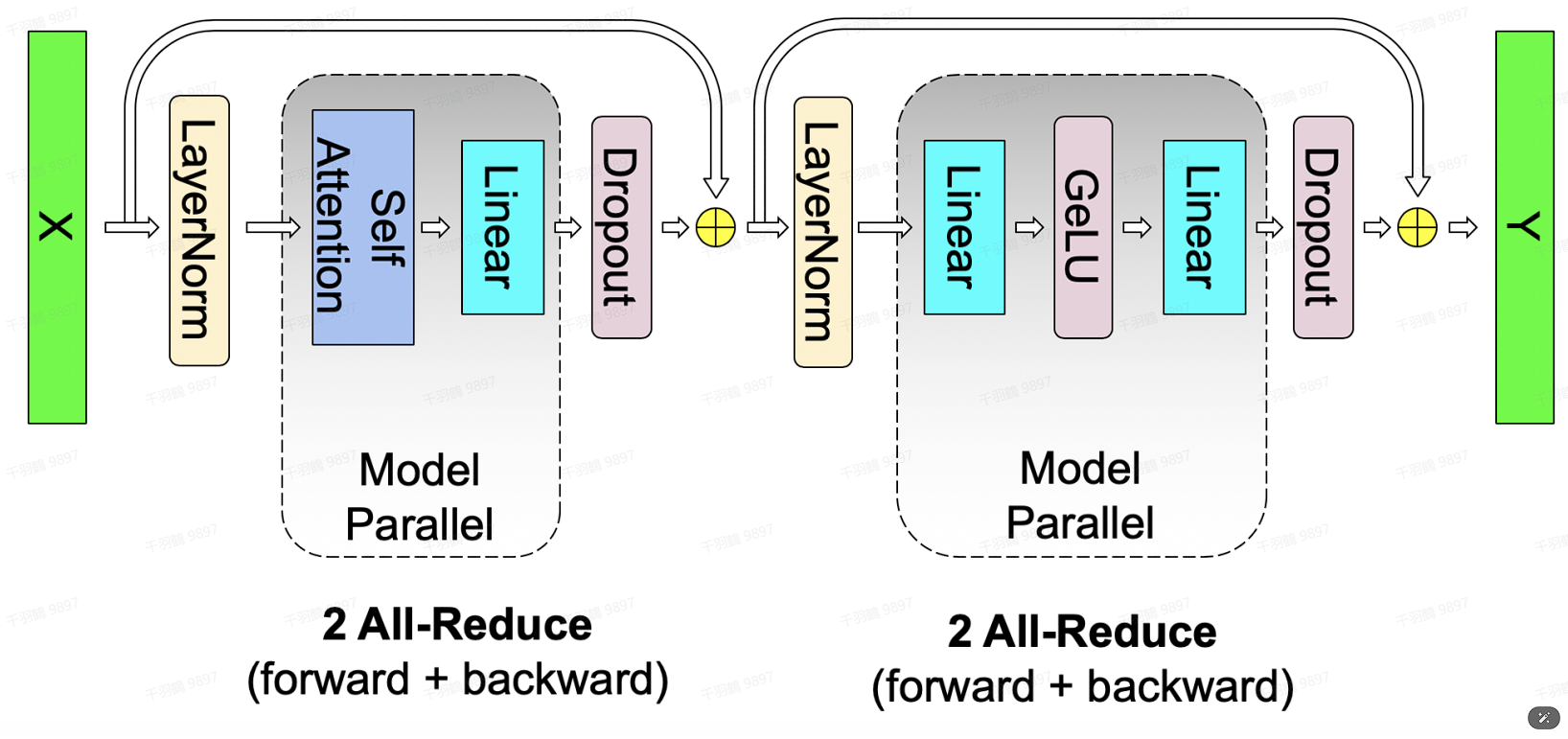
在MLP层中,forward和backward阶段各会产生一次AllReduce。AllReduce的过程分为两个阶段:Reduce-Scatter和All-Gather,每个阶段的通信量都相等。设每个阶段的通信量为
其中:
Self-Attention的切分策略
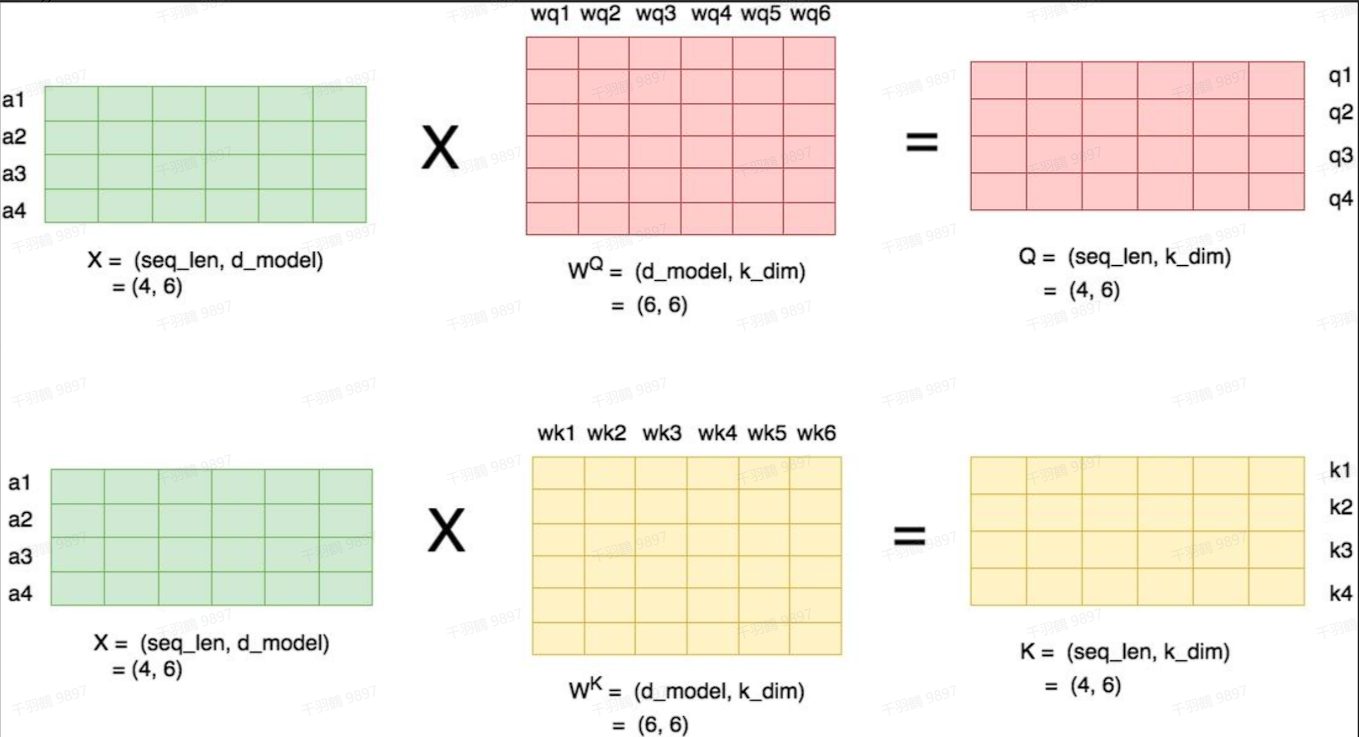
多头注意力并行切分
利用多头注意力固有的并行特性,可以直接以列并行的方法切分QKV相关的GEMMs。首先考虑head=1的情况,self-attention的计算方式如下图所示(图略)。
当num_heads = 2时的情况
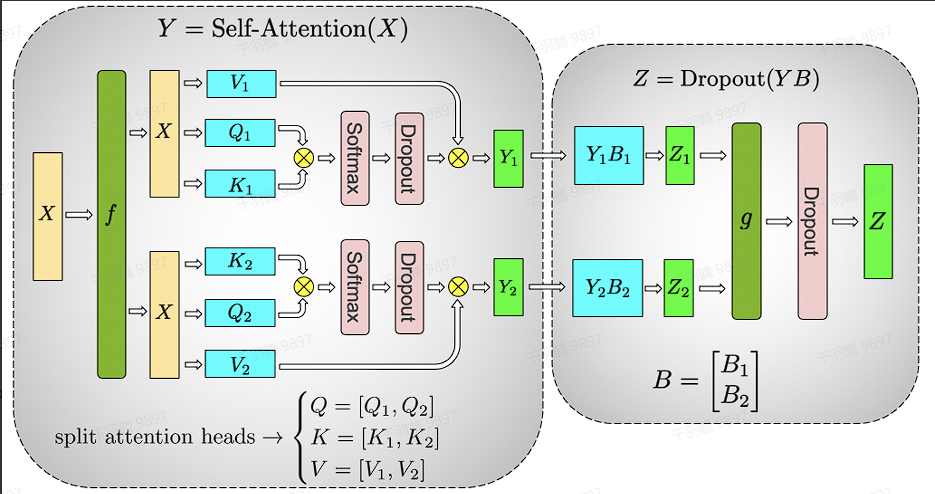
对于每一块权重,我们沿着列方向维度切割一刀。此时每个 head 上的
因此,我们可以把每个头的参数放到一块GPU上,也可以把多个head放到一块GPU上,但尽量保证head总数能被GPU个数整除。
通信量分析
使用
其中:
Embedding切分策略
输入层embedding
输入层embedding包括word embedding和positional embedding两部分。对于positional embedding,由于
输出层embedding
输出层只有一个word embedding。必须时刻保证输入层和输出层共用一套word embedding。在backward过程中,我们在输出层对word embedding计算一次梯度,在输入层中也会计算一次梯度。在用梯度更新word embedding权重时,必须用两次梯度的总和进行更新。
Cross-entropy切分的基本流程
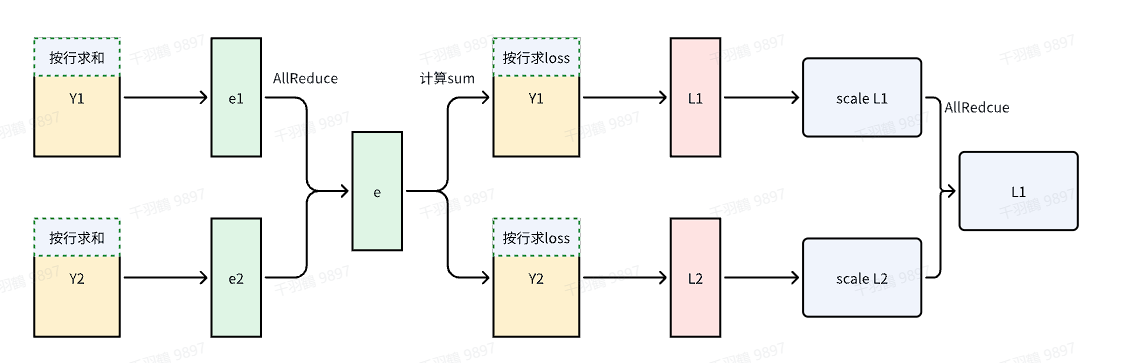
首先,需要对输出层的
然而,All-Gather操作会产生额外的通讯量:
当词表
优化策略
针对上述情况,可以采取以下优化策略:
GPU上的局部计算
每块GPU上,我们可以先按行求和,得到各自GPU上的
AllReduce操作
将每块GPU上的结果做AllReduce操作,得到每行最终的
这就是softmax中的分母。此时的通讯量为:
计算局部Cross-entropy
在每块GPU上,即可计算各自维护部分的
将其与真值做cross-entropy,得到每行的loss,按行加总起来以后得到GPU上的 scalar Loss。
汇总总Loss
将GPU上的 scalar Loss 做AllReduce操作,得到总Loss。此时通讯量为
通过上述优化,我们把原先的通讯量从
大大降至
TransformerBlock中的通信优化
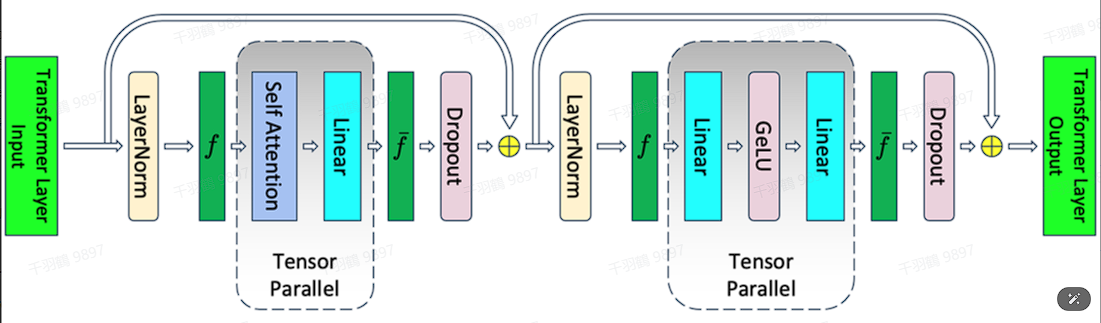
一个TransformerBlock需要在前向和后向总共需要4个all-reduce通信操作。
张量并行与序列并行
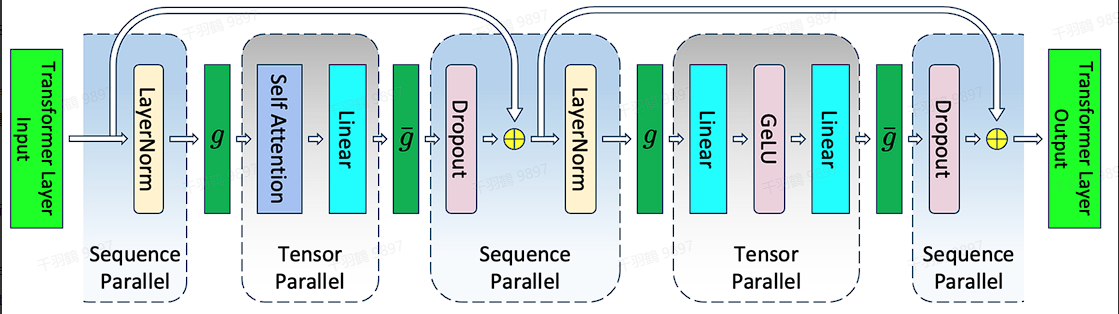
张量并行对AttentionBlock和MLP都进行了并行化,但没有对LN和dropout进行并行化。不过后续在megatron3中用序列并行技术对这两部分进行了并行,这部分就不过多展开了。
流水线并行 Inter-Layer Pipeline Parallelism
在深度学习模型的训练过程中,如何提高效率一直是研究的重点之一。流水线并行是一种将网络按层切分,划分成多组,并将每组放置在不同的设备上进行计算的方法。通过这种方式,可以在不同设备上并行执行不同的模型阶段,从而提高整体效率。
代码块
# 假设模型有8层 两张卡
====================== =====================
| L0 | L1 | L2 | L3 | | L4 | L5 | L6 | L7 |
====================== =====================
GPU0 GPU1
# 设想一下,当GPU0在进行(前向/后向)计算时,GPU1在干嘛?闲着
# 当GPU1在进行(前向/后向)计算时,GPU0在干嘛?闲着
# 为了防止”一卡工作,众卡围观“,实践中PP也会把batch数据分割成
# 多个micro-batch,流水线执行
目前主流的流水线并行方法包括Gpipe和PipeDream。与这两者相比,Megatron中的流水线并行实现略有不同,采用了Virtual Pipeline的方法。传统的流水线并行通常会在一个设备上放置几个模块,通过在计算和通信之间取得平衡来提高效率。然而,虚拟流水线则采取相反的策略。在设备数量不变的前提下,它将流水线阶段进一步细分,以承载更多的通信量,从而降低空闲时间的比率,以缩短每个步骤的执行时间。
Gpipe
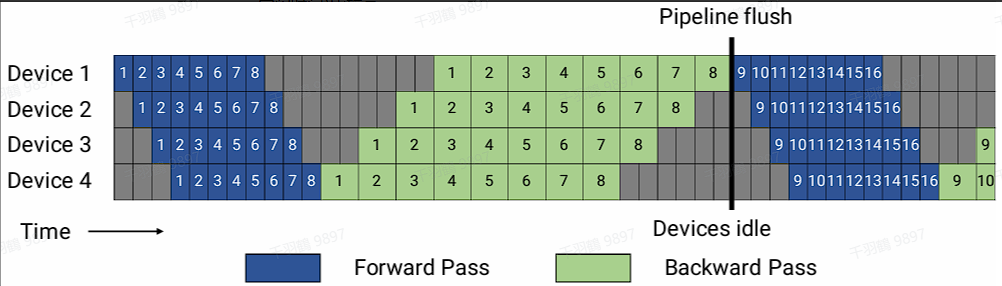
Gpipe方法将transformer层按层切分放到不同的设备上,并将一个batch切分成多个mini-batch。在前向传播时,每个mini-batch从第一个设备流向最后一个设备;在反向传播时,在最后一个设备上计算出梯度并更新对应层的参数,然后将梯度传递给前一个设备进行梯度计算和参数更新。这种方法的劣势之一是空泡率(流水线空闲时间)比较高。
PipeDream

PipeDream相对于Gpipe的改进主要体现在内存方面。虽然空泡时间和Gpipe一致,但通过合理安排前向和反向过程的顺序,在步骤中间的稳定阶段形成1前向1反向(1F1B)的模式。在这个阶段,每个设备上最少只需要保存一份micro-batch的激活值,最多需要保存流水线阶段数份激活值,从而可以有效降低空泡占比。
Virtual Pipeline
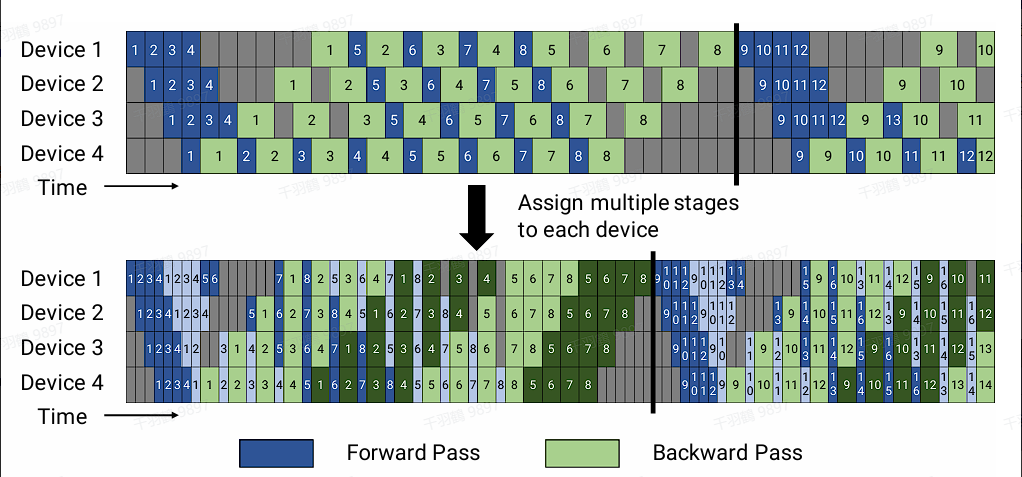
传统的pipeline并行通常会在一个设备上放置几个block,这是为了扩展效率考虑,在计算强度和通信强度中间取一个平衡。但Virtual Pipeline却反其道而行之,在设备数量不变的情况下,分出更多的pipeline阶段,以更多的通信量换取空泡比率降低,减小了每一步的执行时间。假设网络共有16层(编号0-15),4个设备,前述Gpipe和PipeDream是分成4个阶段,按编号0-3层放Device1,4-7层放Device2,以此类推。Virtual Pipeline则是减小切分粒度,以virtual_pipeline_stage=2为例,将0-1层放Device1, 2-3层放在Device2,...,6-7层放到Device4,8-9层继续放在Device1,10-11层放在Device2,...,14-15层放在Device4。在稳定的时候也是1F1B的形式。按照这种方式,设备之间的点对点通信次数(量)直接翻了virtual_pipeline_stage倍,但空泡比率降低了。
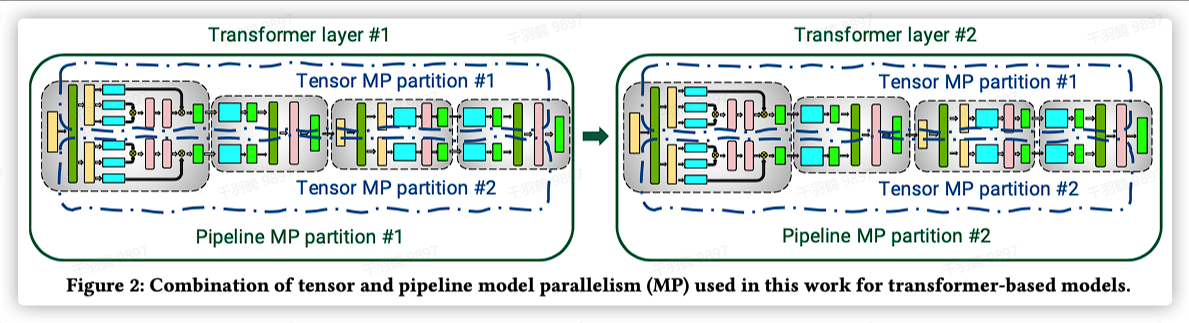
3D并行
数据并行
计算效率高, 实现简单
数据并行是一种计算效率极高且实现简单的并行技术。在这种模式下,每个计算节点都保存完整的模型、梯度和优化器状态,因此显存效率不高。然而,当增加并行度时,单卡的计算量保持恒定,可以实现近乎完美的线性扩展。不过,规约梯度的通信开销与模型大小成正相关。
张量并行
因模型结构而异, 实现难度大
张量并行的实现难度较大,因为它依赖于模型的具体结构。随着并行度增加,显存占用成比例地减少,这是减少单层神经网络中间激活的唯一方法。然而,频繁的通信限制了两个通信阶段之间的计算量,导致计算效率很低。
流水线并行
通信成本最低
流水线并行具有最低的通信成本。虽然减少的显存与流水线并行度成正相关,但流水线并行不会减少每层中间激活的显存占用。其计算效率得益于成本更低的点对点(P2P)通信,通信量与流水线各个阶段边界的激活值大小成正相关。
显存和通信效率比较
- 显存效率:模型并行 > 流水线并行 > 数据并行
- 通信效率:流水线并行 > 数据并行 > 模型并行
3D并行技术的混合应用
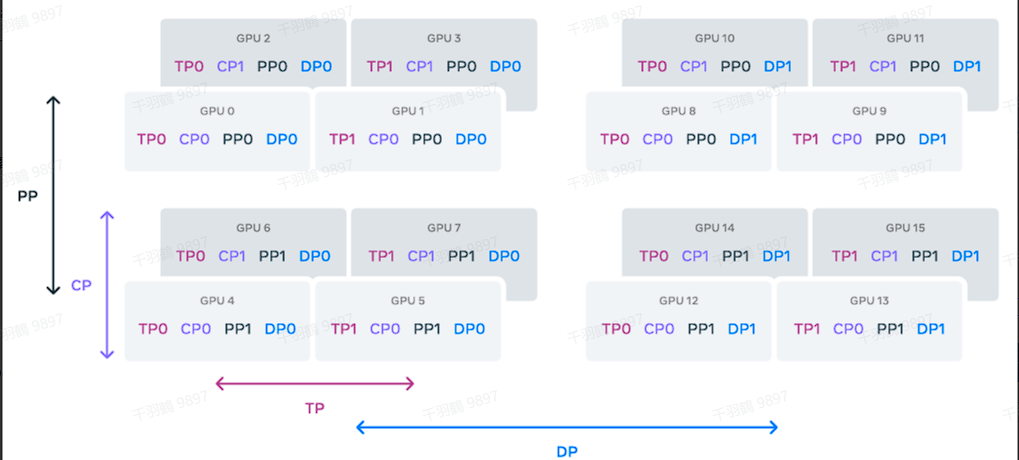
3D并行技术是混合数据并行(DP)、张量并行(TP)和流水线并行(PP)组成的。在实际应用中,可以通过四路张量并行、四路流水线并行、两路数据并行以及32个worker来实现高效的3D并行。
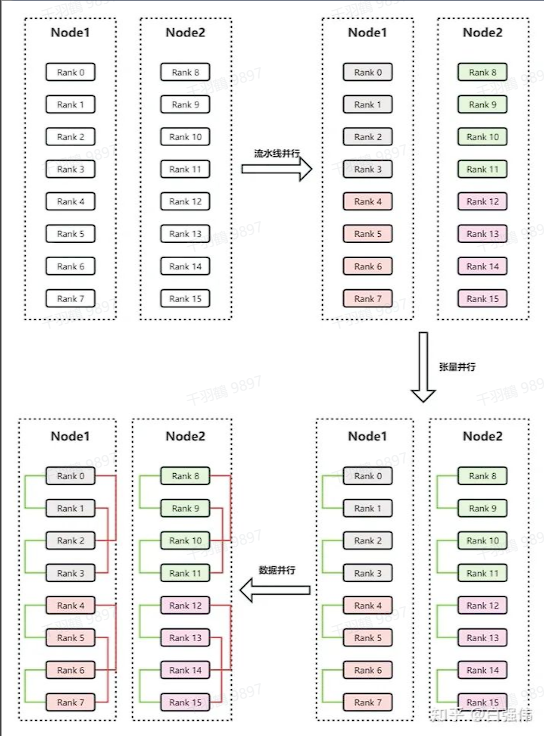
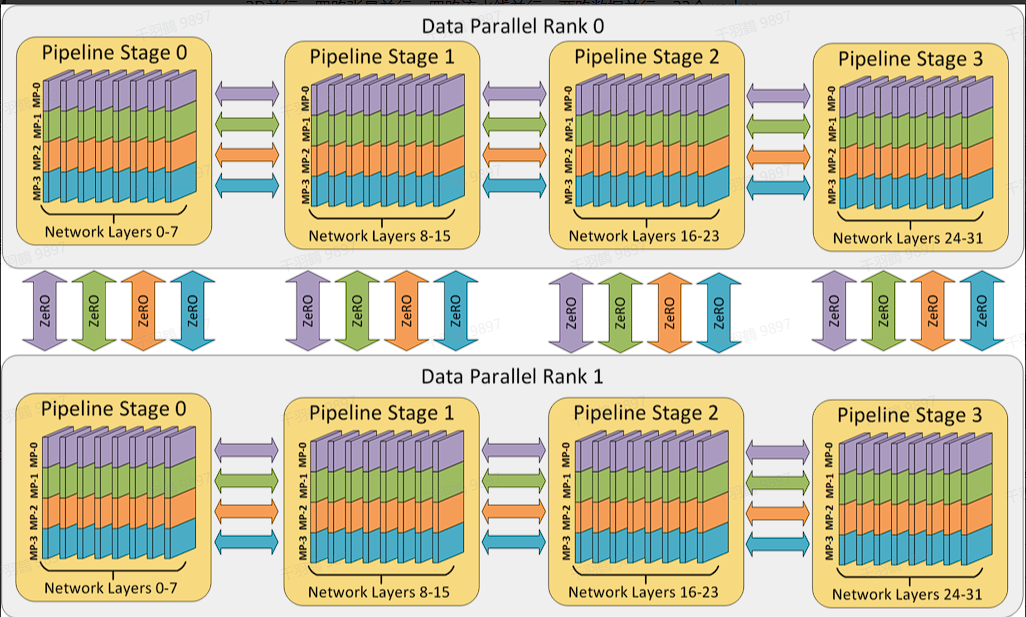
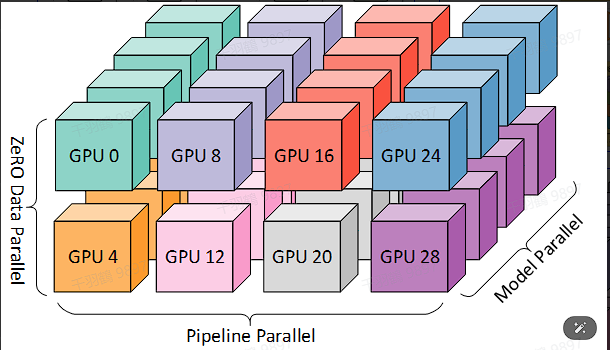
4D并行技术在LLaMA3中的应用
在LLaMA3的技术报告中,他们还使用了4D并行技术。除了PP、TP和DP,还加上了CP(context parallel),进一步提高了模型训练的效率。