Megatron和DeepSpeed后端实现的区别
Megatron和DeepSpeed后端实现的区别
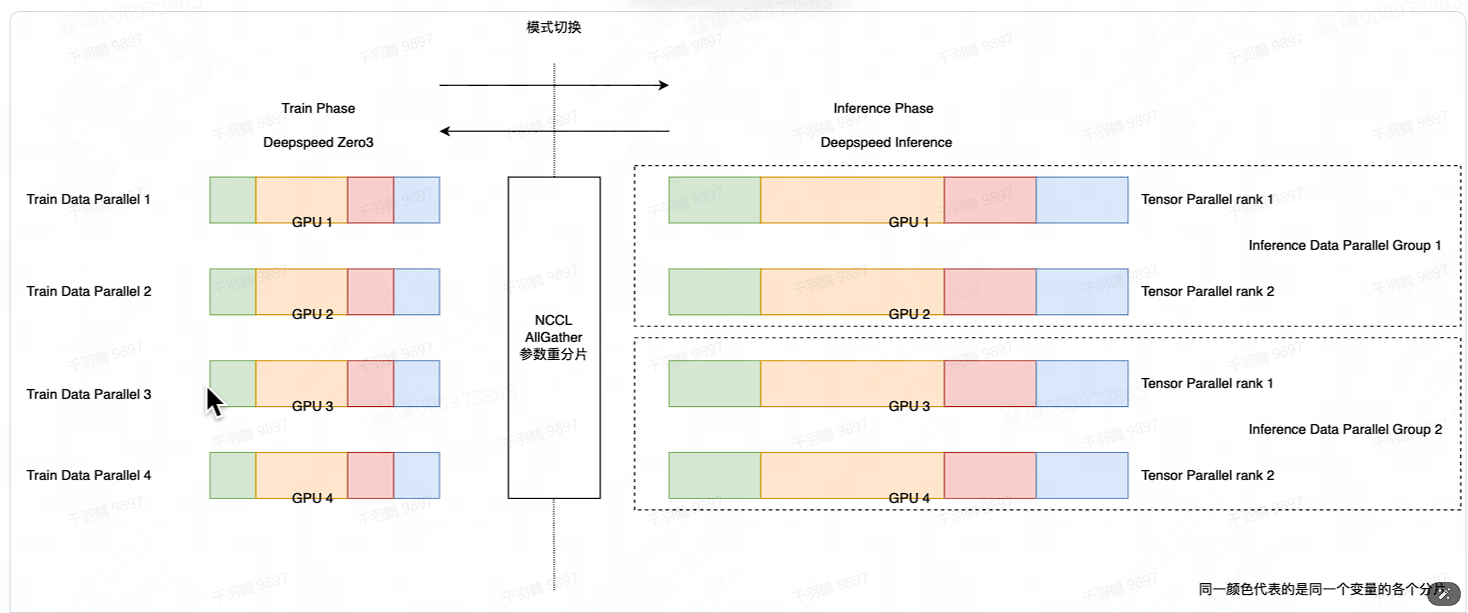
Deepspeed 后端
Deepspeed 后端采用 Zero3 数据并行方式进行的训练,同一个变量的参数被分片后放到不同的 GPU 卡上。如果直接进行生成,每一个变量都会触发一次 AllGather,生成会十分缓慢。我们可以首先通过一次 AllGather 进行参数的重分片,从 Zero3 的参数分片模式,切换到张量并行的参数分片模式。由于生成环节不需要保存模型前向过程中的激活值,也不需要计算梯度,张量并行的并行度可以低于 Zero3 的数据并行度,从而构建出多个推理数据并行组,进行并行生成,进一步加速生成。本方案采用的是 in-place 模式切换的方式,这些卡既用作训练也用作生成,在 Train Phase 和 Inference Phase 间来回切换。
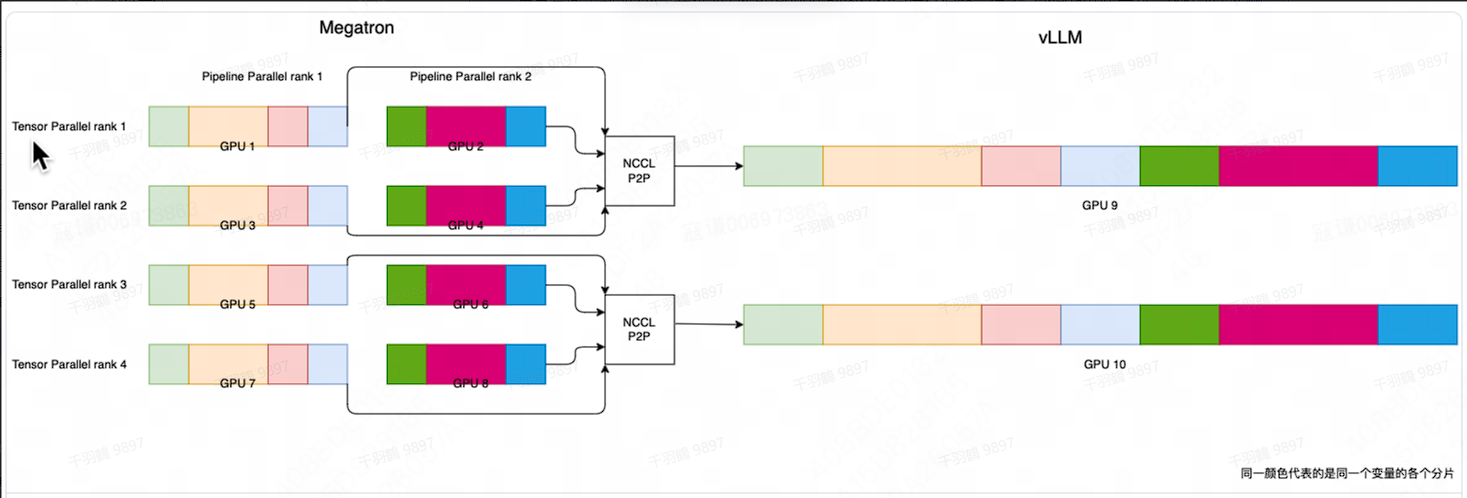
Megatron 后端
Megatron 后端采用 3D 并行方式进行的训练,对模型进行了张量维度和流水线维度的分片,放到不同的 GPU 卡上,直接生成的速度会十分缓慢。我们引入了 vLLM 开源推理引擎,vLLM 实现了张量并行和 PagedAttention,具有显存利用率高、推理吞吐高的特点。我们采用 NCCL P2P 通信将 Megatron 的参数重分片同步到 vLLM,并对 vLLM Attention 的内存布局进行调整,使之与 Megatron 一致,这样 vLLM 侧就可以 recv in place,省略掉参数 rearrange 的过程,加速参数重分片同步的过程。
通过对比可以看出,Deepspeed 和 Megatron 在处理大规模模型训练和推理时,都采取了不同的策略来优化性能和效率。Deepspeed 更强调在训练和推理阶段的灵活切换,而 Megatron 则通过与 vLLM 的结合来提升推理效率。两者各有其独特的优势,根据具体需求选择合适的方案,可以更好地满足不同场景下的性能要求。