X-ray
X-ray: 大语言模型分布式强化学习框架
构建思想
在强化学习中,特别是基于人类反馈的强化学习(RLHF),通常需要多个模型之间进行交互通信。这种通信具有数据量较小、交互模式灵活性要求高的特点,因此非常适合使用 Ray 的 Actor Programming 编程范式来实现模型间通信(inter model communication)。
大模型的训练通常采用 3D 并行技术,其前向、反向和生成过程涉及到大量数据通信。为了高效地实现这些通信,通常采用 GPU NCCL 的集合通信(collective communication)。开源工具如 Deepspeed 和 Megatron 已经提供了模型内通信(intra model communication)的高效解决方案。
通过构建模型间通信和模型内通信的层次化通信平面,我们可以实现以下目标:
- 模型间:基于 Ray 的 Actor Programming 编程范式,实现高效的异步通信。
- 模型内:集成 Megatron 的 TP/PP/DP 并行算法,集成 Deepspeed 的 DP(Zero)并行算法,具备完整的 3D 并行加速方案。
同时,借鉴 trlX 对 PPO 等算法的实现(该算法已经过实战测试),我们采用了 trlX 的 PPO 算法流程。
此外,引入 Deepspeed Inference 和 vLLM 推理加速方案,加速 Actor 的 token 生成效率,支持两种后端组合:Megatron 训练 + vLLM 推理,以及 Deepspeed Zero3 训练 + Deepspeed Inference 推理。
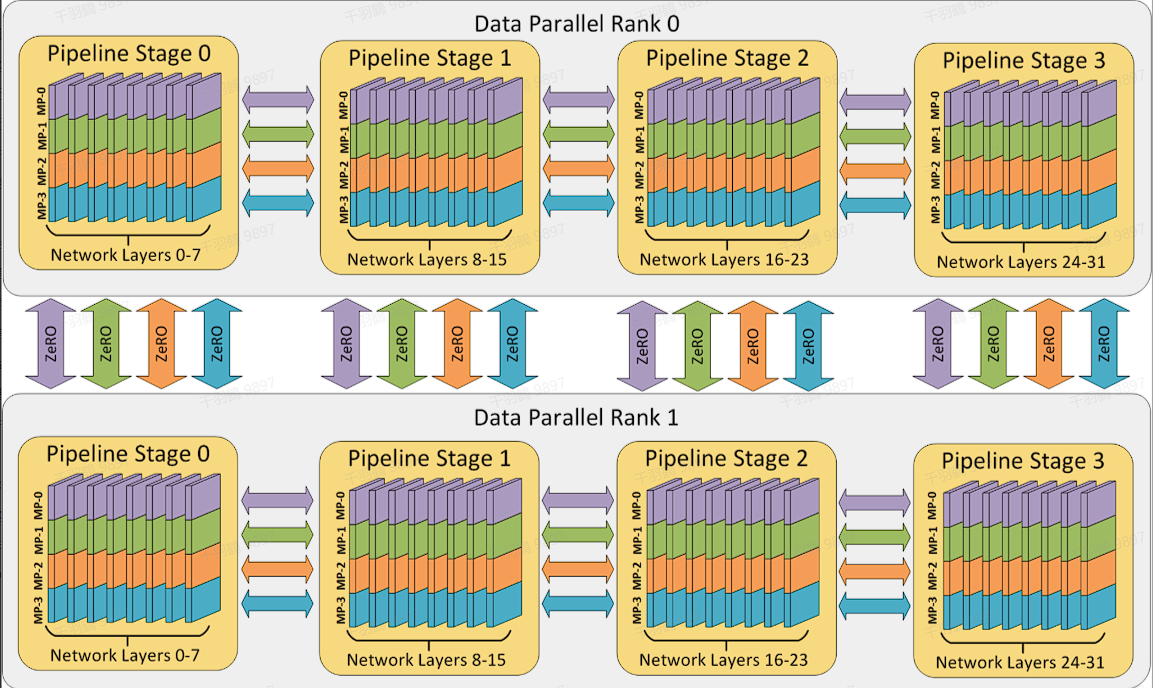
大模型并行训练
在训练大模型时,必然伴随着大数据的处理。并行训练主要涉及以下几个技术:
数据并行(Data Parallel,DP)
在数据并行中,数据在模型副本之间分摊,在反向传播时副本之间交换梯度。更多细节可以参考 PyTorch 的教程。
张量并行(Tensor Parallel,TP)
张量并行涉及 Intra Layer 内的拆分。例如,在 Transformer 结构上按照 Attention Heads 进行
流水线并行(Pipeline Parallel,PP)
流水线并行涉及 Inter Layer 间的拆分。例如,[0,
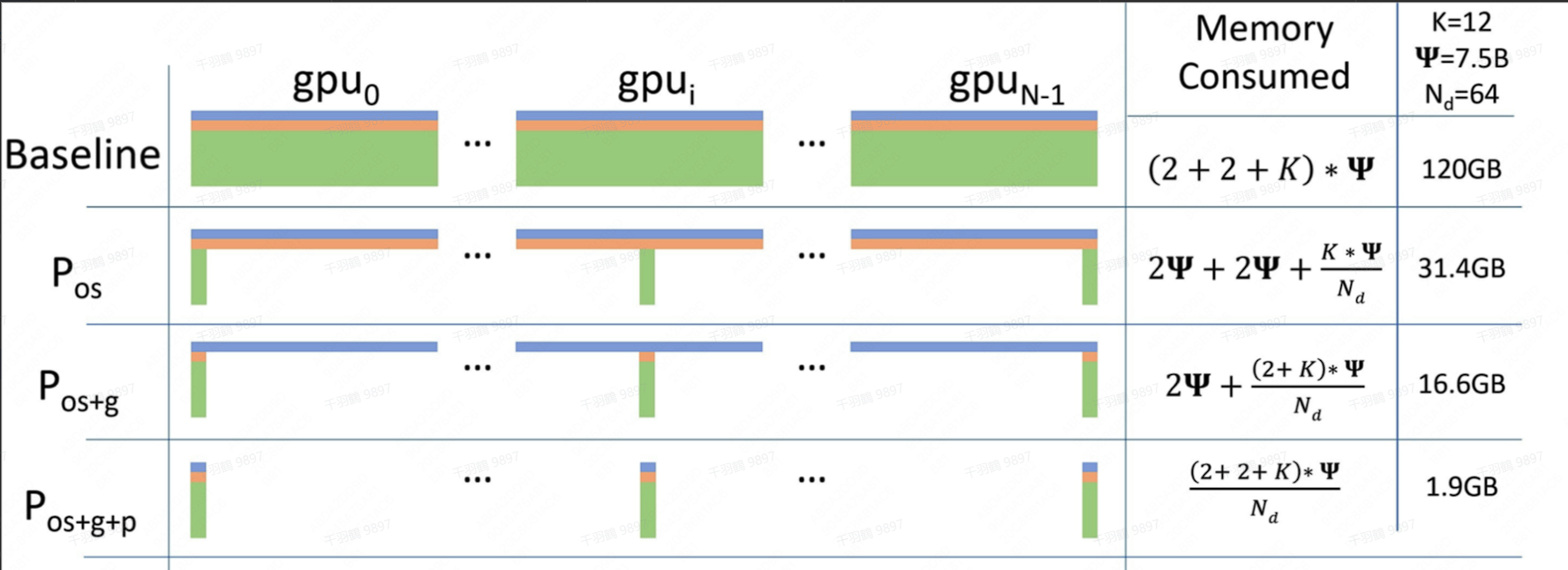
ZeRO (Zero Redundancy Optimizer),
思想上类似 Parameter Server 架构,GPU 间互为参数服务器,参数服务器根据不同模式存储着优化器参数、梯度、模型参数。ZeRO 本质上是数据并行,即一张卡上会发生一次完整的前向和反向。
Megatron-LM、Deepspeed 与 Ray:分布式计算的利器
在当今大数据和深度学习的时代,分布式计算框架成为了不可或缺的工具。本文将介绍三个重要的分布式计算框架:Megatron-LM、Deepspeed 和 Ray,并探讨它们各自的特点和优势。
Megatron-LM
Megatron-LM 是一个性能极高的深度学习模型训练框架,包含了大量的优化技巧。它通过算子融合和通信计算并行化等技术,极大地提高了模型训练的效率。然而,Megatron-LM 支持的模型类型较少,适配 Hugging Face 模型的成本较高,这使得它在某些应用场景中的灵活性受到限制。
Deepspeed
Deepspeed 是另一个广泛使用的深度学习框架,其最大的优势在于无缝支持 Hugging Face 的大量模型。Deepspeed 采用原生 torch 算子实现,因此性能相对一般,但其兼容性和易用性使得它成为许多开发者的首选。
Ray
Ray 是一个高性能分布式执行框架,为解决世界上最复杂和要求苛刻的计算问题提供了强大的支持。正如 OpenAI 的 CTO 和联合创始人 Greg Brockman 所说:
“在 OpenAI,我们正在解决世界上一些最复杂和要求苛刻的计算问题。Ray 为我们提供了解决这些棘手问题的动力,并使我们能够比以往更快地进行大规模迭代。”
Ray 提供了简单但通用的分布式编程抽象,处于较低的抽象层次,可以在其上构建各种分布式计算系统。Ray 的编程前端包括 Python、Java 和 C++(实验性),其去中心化的构建思想体现在分布式共享内存 object store、分布式引用计数和分布式调度。
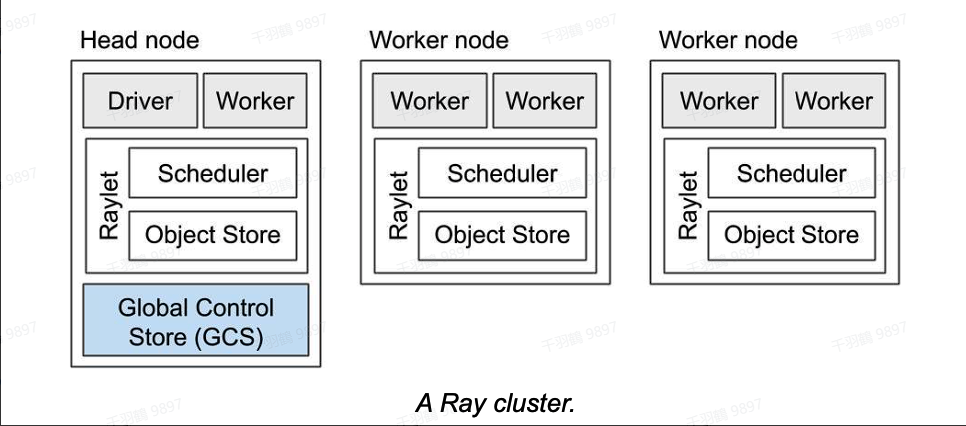
在 Ray 的编程抽象中,Actor 实现为一个 Python Class,代表的是一个 Long Running Python Process。我们可以通过调用 Class 的方法向 Ray Actor 发送请求。
代码示例
以下是一个简单的 Ray Actor 示例代码:
import ray
@ray.remote
class Counter:
def __init__(self):
self.value = 0
def increment(self):
self.value += 1
return self.value
def get_counter(self):
return self.value
# Create ten Counter actors.
counters = [Counter.remote() for _ in range(10)]
# Increment each Counter once and get the results. These tasks all happen in
# parallel.
results = ray.get([c.increment.remote() for c in counters])
print(results)
# Increment the first Counter five times. These tasks are executed serially
# and share state.
results = ray.get([counters[0].increment.remote() for _ in range(5)])
print(results)
通过这个示例,我们可以看到 Ray 如何使用 Python Class 来实现 Actor 模型,使得开发者能够轻松地构建分布式应用程序。
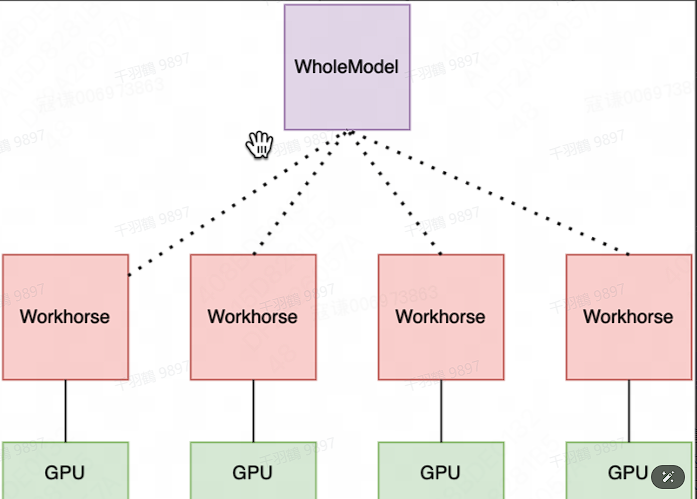
为了构建大语言模型分布式强化学习框架,我们抽象出 Workhorse 和 WholeModel 两个核心类:
Workhorse,是一个 Ray Actor,其持有一张 GPU 卡,是模型的一个分片。
WholeModel,是一个 Ray Actor,它代表了一个模型整体,是一个代理,而模型本身可能被 shard / replicate 到多机多卡上,它持有着多个 Workhorse。